- Un namespace Linux e' una zona di rete isolata: ha le sue interfacce, le sue rotte, il suo stack IP
- I veth pair sono i cavi virtuali che collegano i namespace - equivalenti dei cavi fisici in Cisco
iptables -P FORWARD DROPe' il security-level dell'ASA: blocca tutto il traffico in transito per default- Le ACL diventano
iptables -A FORWARD: stessa logica, sintassi diversa
▶ $ history
ip netns add- crea un namespaceip link add veth0 type veth peer name veth1- crea un cavo virtualeip netns exec <ns> <comando>- esegue un comando dentro un namespaceiptables -P FORWARD DROP- blocca tutto il traffico in transitoiptables -A FORWARD- aggiunge una regola di permesso
Perche' questo lab#
mindmap
root((Perche questo lab))
Scenario
corsobitcoin.com
Sofia nginx in DMZ
Giulia MySQL in LAN
Confronto Cisco vs Linux
ASA sostituito da iptables
Switch sostituito da veth pair
VLAN sostituite da namespace
Obiettivo
Stessa topologia
Zero hardware dedicato
Solo Ubuntu e comandi
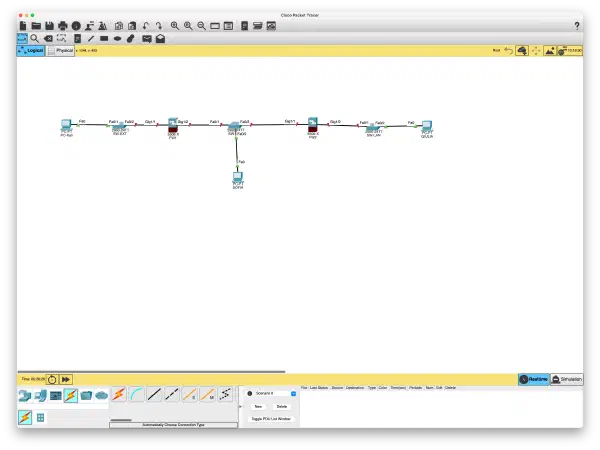
Stesso scenario del cisco-packet-tracer-dmz|lab Cisco: corsobitcoin.com con Sofia/nginx nella DMZ e Giulia/MySQL nella LAN privata.
La differenza: nessun ASA, nessuno switch fisico, nessun Packet Tracer. Solo una VM Ubuntu e i comandi giusti.
In Cisco il firewall e' un dispositivo dedicato con security-level e nameif. In Linux e' un namespace con iptables. In Cisco le VLAN separano i segmenti a livello 2. In Linux la separazione e' gia' nella struttura dei namespace - ogni veth pair e' un segmento isolato.
Stesso risultato, strumenti diversi.
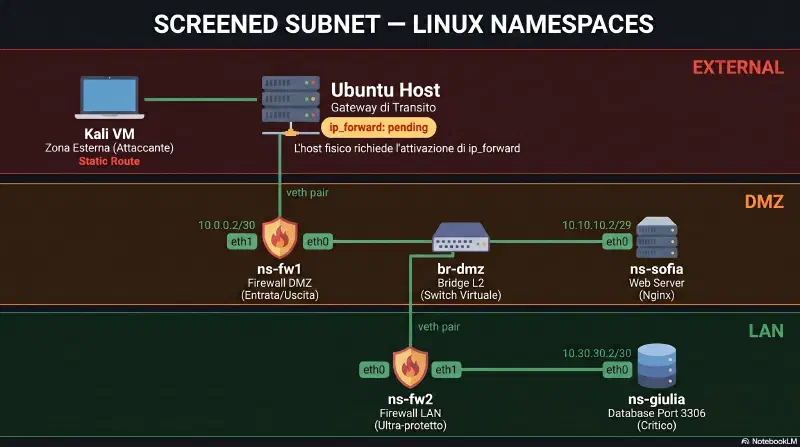
La topologia#
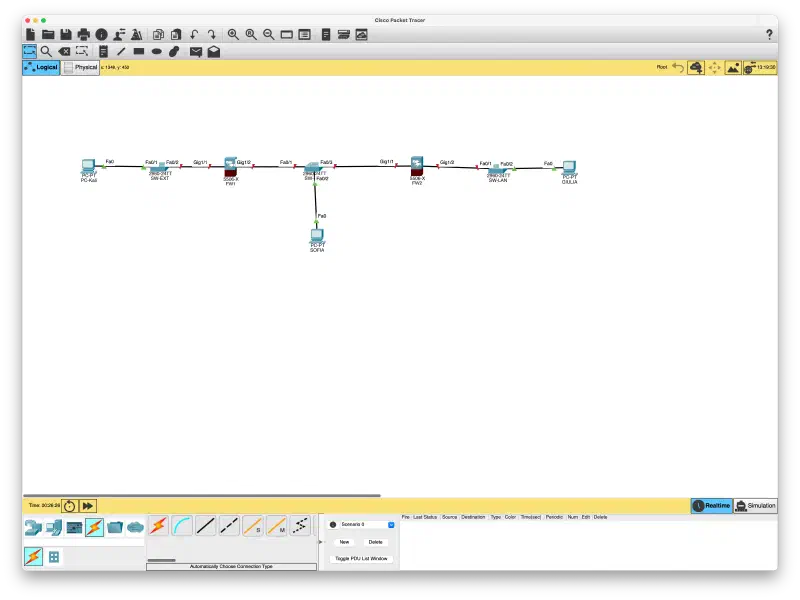
La topologia logica e' identica al cisco-packet-tracer-dmz|lab Cisco. In Linux i namespace sostituiscono i dispositivi fisici, i veth pair sostituiscono i cavi e gli switch, iptables sostituisce il security-level ASA.
A differenza del lab Cisco dove Kali era un PC simulato, qui Kali e' una VM reale (192.168.64.200) che attacca dall'esterno. Tutti i namespace girano su Ubuntu (192.168.64.3). ns-kali non esiste - Kali e' gia' fuori.
graph TD
KALI["Kali VM
192.168.64.200"]
UBUNTU["Ubuntu host
192.168.64.3
enp0s1 → rete UTM"]
FW1["ns-fw1
iptables — FW1
out: 10.0.0.2/30
dmz: 10.10.10.1/29"]
BRDMZ["br-dmz
switch virtuale L2"]
SOFIA["ns-sofia
nginx + WAF
10.10.10.2/29"]
FW2["ns-fw2
iptables — FW2
dmz: 10.10.10.3/29
lan: 10.30.30.1/30"]
GIULIA[("ns-giulia
netcat 3306
10.30.30.2/30")]
KALI -- "UTM host-only" --> UBUNTU
UBUNTU -- "veth-host 10.0.0.1/30" --> FW1
FW1 -- "veth-fw1-dmz" --> BRDMZ
BRDMZ -- "veth-sofia" --> SOFIA
BRDMZ -- "veth-fw2-dmz" --> FW2
FW2 -- "veth-fw2-lan / veth-giulia" --> GIULIA
classDef external fill:#2d1515,stroke:#e05555,color:#fff
classDef dmz fill:#2d1a0d,stroke:#ff7a4a,color:#fff
classDef lan fill:#0d2318,stroke:#4aaf7e,color:#fff
classDef fw fill:#0d1a2d,stroke:#4a9eff,color:#fff
class KALI,UBUNTU external
class SOFIA,BRDMZ dmz
class GIULIA lan
class FW1,FW2 fw
flowchart LR
classDef ext fill:#4a0d0d,stroke:#e05555,color:#eee
classDef fw fill:#0d1a3d,stroke:#4a9eff,color:#eee
classDef dmz fill:#3d2a0d,stroke:#ffaa4a,color:#eee
classDef lan fill:#0d2d15,stroke:#4aff7e,color:#eee
subgraph EXT[Zona esterna]
KALI(["🌐 Kali
192.168.64.200"]):::ext
FW1(["🛡 ns-fw1
iptables FW1"]):::fw
end
subgraph DMZ[DMZ 10.10.10.0/29]
SOFIA(["🖥 ns-sofia
nginx + WAF"]):::dmz
FW2(["🛡 ns-fw2
iptables FW2"]):::fw
end
subgraph LAN[LAN 10.30.30.0/30]
GIULIA[("🗄 ns-giulia
MySQL")]:::lan
end
KALI --> FW1
FW1 --> SOFIA
FW1 --> FW2
FW2 --> GIULIA
Per far raggiungere a Kali la rete 10.0.0.0/30 di ns-fw1, aggiungiamo una rotta su Kali:
# su Kali VM - dice a Kali che per raggiungere 10.0.0.0/30
# deve passare per Ubuntu (192.168.64.3)
sudo ip route add 10.0.0.0/30 via 192.168.64.3| Cisco | Linux | Ruolo |
|---|---|---|
| PC-Kali | Kali VM 192.168.64.200 | attaccante reale, fuori da Ubuntu |
| SW-EXT | veth pair | cavo virtuale (no namespace) |
| FW1 ASA | ns-fw1 + iptables | firewall perimetrale |
| SW-DMZ | veth pair | cavo virtuale |
| Sofia/nginx | ns-sofia + nginx | web server / WAF in DMZ |
| FW2 ASA | ns-fw2 + iptables | firewall interno |
| SW-LAN | veth pair | cavo virtuale |
| Giulia/MySQL | ns-giulia + netcat | database in LAN |
Gli switch non diventano namespace - sono solo veth pair. Un veth pair e' un cavo virtuale: due interfacce collegate, quello che entra da una esce dall'altra.
Riferimento rapido#
mindmap
root((Riferimento rapido))
ns-fw1
veth-fw1-out 10.0.0.2/30
veth-fw1-dmz 10.10.10.1/29
br-dmz
veth-fw1-dmz-br
veth-sofia-br
veth-fw2-dmz-br
ns-fw2
veth-fw2-dmz 10.10.10.3/29
veth-fw2-lan 10.30.30.1/30
Hosts
Kali 10.0.0.1/30
ns-sofia 10.10.10.2/29
ns-giulia 10.30.30.2/30
Rotte statiche
ns-fw1 default via 10.0.0.1
ns-fw1 LAN via 10.10.10.3
ns-fw2 default via 10.10.10.1
ns-fw1
veth-fw1-out 10.0.0.2/30 -> host (Kali arriva da qui)
veth-fw1-dmz 10.10.10.1/29 -> br-dmz (switch virtuale L2)
br-dmz <- bridge Linux = SW-DMZ del lab Cisco. Commuta frame L2 tra FW1, Sofia e FW2
veth-fw1-dmz-br -> ns-fw1
veth-sofia-br -> ns-sofia
veth-fw2-dmz-br -> ns-fw2
ns-fw2
veth-fw2-dmz 10.10.10.3/29 -> br-dmz (switch virtuale L2)
veth-fw2-lan 10.30.30.1/30 -> ns-giulia
HOSTS
Kali VM 10.0.0.1/30 gw: 10.0.0.2 (rotta aggiunta su Kali)
ns-sofia 10.10.10.2/29 gw: 10.10.10.1
ns-giulia 10.30.30.2/30 gw: 10.30.30.1
ROTTE
ns-fw1: ip route add default via 10.0.0.1
ns-fw1: ip route add 10.30.30.0/30 via 10.10.10.3
ns-fw2: ip route add default via 10.10.10.1Schema IP#
mindmap
root((Schema IP))
Zona esterna
10.0.0.0/30
ns-kali 10.0.0.1
ns-fw1 out 10.0.0.2
DMZ
10.10.10.0/29
ns-fw1 dmz 10.10.10.1
ns-sofia 10.10.10.2
ns-fw2 dmz 10.10.10.3
LAN
10.30.30.0/30
ns-fw2 lan 10.30.30.1
ns-giulia 10.30.30.2
| Zona | Subnet | Namespace | IP |
|---|---|---|---|
| Esterna | 10.0.0.0/30 | ns-kali | 10.0.0.1 |
| Esterna | 10.0.0.0/30 | ns-fw1 (out) | 10.0.0.2 |
| DMZ | 10.10.10.0/29 | ns-fw1 (dmz) | 10.10.10.1 |
| DMZ | 10.10.10.0/29 | ns-sofia | 10.10.10.2 |
| DMZ | 10.10.10.0/29 | ns-fw2 (dmz) | 10.10.10.3 |
| LAN | 10.30.30.0/30 | ns-fw2 (lan) | 10.30.30.1 |
| LAN | 10.30.30.0/30 | ns-giulia | 10.30.30.2 |
Gli IP sono identici al lab Cisco. Stessa topologia, stessi indirizzi, strumenti diversi.
VLAN in Linux: non esistono, e non servono#
Nel cisco-packet-tracer-dmz|lab Cisco abbiamo configurato VLAN 10, 20 e 30 su tre switch separati. Qui non c'e' nessuna VLAN da configurare - e l'isolamento funziona lo stesso.
In Cisco le VLAN erano necessarie perche' tutto passava per switch fisici condivisi. Senza VLAN, Kali e Sofia si vedevano a livello 2 sullo stesso switch. Le VLAN mettevano muri tra le zone.
In Linux ogni veth pair e' un cavo punto-punto dedicato. ns-sofia non ha nessuna interfaccia verso Kali - fisicamente il collegamento non esiste. Non c'e' nessuno switch condiviso dove i frame si potrebbero mescolare.
flowchart LR
classDef ext fill:#4a0d0d,stroke:#e05555,color:#eee
classDef fw fill:#0d1a3d,stroke:#4a9eff,color:#eee
classDef dmz fill:#3d2a0d,stroke:#ffaa4a,color:#eee
classDef lan fill:#0d2d15,stroke:#4aff7e,color:#eee
KALI["Kali VM"]:::ext
FW1["ns-fw1"]:::fw
SOFIA["ns-sofia"]:::dmz
FW2["ns-fw2"]:::fw
GIULIA[("ns-giulia")]:::lan
KALI <-->|"veth pair"| FW1
FW1 <-->|"veth pair"| SOFIA
SOFIA <-->|"veth pair"| FW2
FW2 <-->|"veth pair"| GIULIA
| Cisco | Linux namespace |
|---|---|
| SW-EXT + VLAN 10 | veth tra host e ns-fw1 |
| SW-DMZ + VLAN 20 | veth tra ns-fw1 e ns-sofia + veth tra ns-sofia e ns-fw2 |
| SW-LAN + VLAN 30 | veth tra ns-fw2 e ns-giulia |
L'isolamento che in Cisco richiedeva switch + configurazione VLAN, in Linux e' gia' nella struttura dei namespace. Non puoi sbagliare VLAN perche' le VLAN non esistono.
Le VLAN nella realta'#
mindmap
root((VLAN nella realta))
Switch fisico in datacenter
Porta server web VLAN 10 DMZ
Porta database VLAN 20 LAN
Porte FW collegate a entrambe
Equivalenti software
Linux namespaces veth pair
Docker docker network
AWS subnet e security group
Concetto comune
Zona esterna
DMZ
LAN privata
Le VLAN in produzione si configurano quando hai un'infrastruttura fisica condivisa - switch reali con tanti dispositivi collegati sullo stesso hardware:
Switch fisico in datacenter
├── porta 1 → server web 1 VLAN 10 (DMZ)
├── porta 2 → server web 2 VLAN 10 (DMZ)
├── porta 3 → database 1 VLAN 20 (LAN)
├── porta 4 → database 2 VLAN 20 (LAN)
├── porta 5 → FW1 VLAN 10 (DMZ)
└── porta 6 → FW2 VLAN 20 (LAN)Tutti fisicamente sullo stesso switch. Senza VLAN si vedrebbero tutti a livello 2. Le VLAN creano la separazione.
Ogni ambiente risolve lo stesso problema con strumenti diversi:
| Ambiente | Strumento di isolamento |
|---|---|
| Cisco / switch fisico | VLAN su porte dello switch |
| Linux namespaces | isolamento implicito nei veth pair |
| Docker | docker network |
| AWS / Azure | subnet + security group |
In cloud le VLAN non esistono come concetto - esistono le subnet dentro una VPC (Virtual Private Cloud) e i security group che decidono chi puo' parlare con chi. E' esattamente lo stesso modello: zona esterna, DMZ, LAN privata - ma tutto software, gestito dal provider. Quello che in Cisco richiedeva switch fisici e cavi, in AWS si configura sulla console. Il concetto sotto e' identico: isola le zone, controlla il traffico tra di esse.
Creazione namespace#
mindmap
root((Creazione namespace))
Concetto
Stack IP isolato
Interfacce proprie
Routing table propria
iptables proprie
Namespace del lab
ns-fw1 firewall perimetrale
ns-sofia web server DMZ
ns-fw2 firewall interno
ns-giulia database LAN
Comandi
ip netns add
ip netns list
ip netns exec
Analogia
Cisco canvas con dispositivi
Docker exec stesso meccanismo
Solo rete isolata non filesystem
Nel cisco-packet-tracer-dmz|lab Cisco questa era la fase in cui trascinavo i dispositivi sulla canvas: FW1, FW2, SW-DMZ, i PC. In Linux non c'e' canvas - i dispositivi si creano da terminale.
Un network namespace e' uno stack IP completamente isolato: interfacce proprie, routing table propria, regole iptables proprie. Stesso kernel, rete separata. Quattro namespace = quattro "router virtuali" indipendenti sullo stesso Ubuntu.
ip netns exec ns-fw1 <comando> funziona come docker exec <container> <comando>: entra nel contesto di rete di quel namespace ed esegue. La differenza e' che un namespace isola solo la rete - Docker isola anche filesystem, processi e utenti usando piu' tipi di namespace insieme. Ogni container Docker ha dentro di se' un network namespace - e' lo stesso meccanismo sotto il cofano.
ip netns list
# ns-giulia (id: 6)
# ns-fw2 (id: 5)
# ns-sofia (id: 4)
# ns-fw1 (id: 3)Gli ID sono assegnati dal kernel nell'ordine di creazione - ns-fw1 per primo (id 3), ns-giulia per ultimo (id 6). Sono identificatori interni, non ci servono per niente.
# crea ns-fw1 - equivalente di FW1 ASA in Cisco.
# sara' il firewall perimetrale tra Kali e la DMZ.
# ci metteremo iptables con policy DROP, come il security-level 0/50 dell'ASA
sudo ip netns add ns-fw1
# crea ns-sofia - equivalente di Sofia/nginx in Cisco.
# la zona di mezzo: esposta verso Kali, separata dalla LAN.
# ci installeremo nginx + ModSecurity come WAF reale
sudo ip netns add ns-sofia
# crea ns-fw2 - equivalente di FW2 ASA in Cisco.
# il secondo firewall: protegge ns-giulia dalla DMZ.
# stessa logica di FW2: security-level 50 verso dmz, 100 verso inside
sudo ip netns add ns-fw2
# crea ns-giulia - equivalente di Giulia/MySQL in Cisco.
# la zona piu' protetta: raggiungibile solo attraverso ns-fw2.
# useremo netcat sulla porta 3306 per simulare MySQL
sudo ip netns add ns-giulia
# verifica: mostra tutti i namespace creati
# equivalente di guardare la canvas in Packet Tracer e vedere i dispositivi
ip netns listOutput atteso:
ns-giulia
ns-fw2
ns-sofia
ns-fw1Quattro namespace, quattro zone. Ogni namespace corrisponde a un attore del lab Cisco:
| Cisco | Linux | Note |
|---|---|---|
| FW1 ASA | ns-fw1 | firewall perimetrale |
| Sofia/nginx | ns-sofia | web server in DMZ |
| FW2 ASA | ns-fw2 | firewall interno |
| Giulia/MySQL | ns-giulia | database in LAN |
| PC-Kali | Kali VM reale | fuori da Ubuntu, nessun namespace |
| SW-EXT / SW-DMZ / SW-LAN | veth pair / br-dmz | cavi virtuali, non hanno stack IP |
Gli switch non diventano namespace perche' non hanno bisogno di un routing table o di iptables - sono solo cavi. I namespace sono per i dispositivi che elaborano pacchetti.
A questo punto i namespace esistono ma sono vuoti: nessuna interfaccia, nessun IP, nessuna rotta. E' come aver posizionato i dispositivi sulla canvas di Packet Tracer ma senza ancora collegare i cavi o configurare gli IP.
Veth pair - i cavi virtuali#
mindmap
root((Veth pair))
Concetto
Due interfacce virtuali collegate
Tutto in entra da una esce dallaltra
Equivalente cavo fisico Cisco
Struttura del lab
veth-host verso ns-fw1
br-dmz bridge DMZ switch virtuale L2
veth-fw1-dmz-br
veth-sofia-br
veth-fw2-dmz-br
veth-fw2-lan verso ns-giulia
Perche il bridge DMZ
Tre dispositivi sulla stessa subnet
FW1 Sofia FW2 su 10.10.10.0/29
Senza bridge non si vedono a L2
Comandi
ip link add type veth peer
ip link set netns
ip link set master br-dmz
Nel cisco-packet-tracer-dmz|lab Cisco questa era la fase in cui trascinavo i cavi tra i dispositivi sulla canvas. In Linux i cavi si chiamano veth pair: due interfacce virtuali collegate tra loro - quello che entra da una esce dall'altra.
Una differenza importante rispetto a Cisco: nel lab Cisco la DMZ aveva tre dispositivi sullo stesso switch fisico (FW1, Sofia, FW2) tutti sulla subnet 10.10.10.0/29. Per replicarlo fedelmente usiamo un bridge Linux - uno switch virtuale che collega tutti e tre nella stessa zona L2. Senza bridge, FW1 e FW2 non si vedrebbero a livello 2 e non potrebbero condividere la stessa subnet.
# --- link esterno: host <-> ns-fw1 ---
# equivalente del cavo tra SW-EXT e FW1 in Cisco.
# "veth-host" resta nel namespace host (Ubuntu), "veth-fw1-out" va dentro ns-fw1.
# Kali VM raggiungera' ns-fw1 attraverso Ubuntu - per questo serve una rotta su Kali
sudo ip link add veth-host type veth peer name veth-fw1-out
# sposta veth-fw1-out dentro ns-fw1 - da questo momento quella interfaccia
# appartiene esclusivamente a ns-fw1 e non e' piu' visibile dal host
sudo ip link set veth-fw1-out netns ns-fw1
# --- bridge DMZ (br = bridge): equivalente di SW-DMZ con VLAN 20 ---
# un bridge Linux e' uno switch virtuale L2 - commuta frame in base al MAC,
# non instrada pacchetti IP. "br-dmz" e' SW-DMZ del lab Cisco.
# senza bridge, ns-fw1 e ns-fw2 sarebbero su link punto-punto separati
# e non potrebbero condividere la stessa subnet 10.10.10.0/29
sudo ip link add br-dmz type bridge
# attiva il bridge - senza questo e' creato ma non processa traffico
sudo ip link set br-dmz up
# veth pair per collegare ns-fw1 al bridge DMZ.
# "veth-fw1-dmz" va dentro ns-fw1, "veth-fw1-dmz-br" resta nel host collegato al bridge.
# equivalente del cavo tra FW1 Gig1/2 (dmz) e SW-DMZ
sudo ip link add veth-fw1-dmz type veth peer name veth-fw1-dmz-br
sudo ip link set veth-fw1-dmz netns ns-fw1
sudo ip link set veth-fw1-dmz-br master br-dmz
sudo ip link set veth-fw1-dmz-br up
# veth pair per collegare ns-sofia al bridge DMZ.
# "veth-sofia" va dentro ns-sofia, "veth-sofia-br" resta nel host collegato al bridge.
# equivalente del cavo tra Sofia/nginx e SW-DMZ
sudo ip link add veth-sofia type veth peer name veth-sofia-br
sudo ip link set veth-sofia netns ns-sofia
sudo ip link set veth-sofia-br master br-dmz
sudo ip link set veth-sofia-br up
# veth pair per collegare ns-fw2 al bridge DMZ.
# "veth-fw2-dmz" va dentro ns-fw2, "veth-fw2-dmz-br" resta nel host collegato al bridge.
# equivalente del cavo tra FW2 Gig1/1 (dmz) e SW-DMZ
sudo ip link add veth-fw2-dmz type veth peer name veth-fw2-dmz-br
sudo ip link set veth-fw2-dmz netns ns-fw2
sudo ip link set veth-fw2-dmz-br master br-dmz
sudo ip link set veth-fw2-dmz-br up
# --- link LAN: ns-fw2 <-> ns-giulia ---
# equivalente del cavo tra SW-LAN e FW2 Gig1/2 (inside) / Giulia/MySQL.
# solo due dispositivi - non serve bridge, basta un veth pair diretto
sudo ip link add veth-fw2-lan type veth peer name veth-giulia
sudo ip link set veth-fw2-lan netns ns-fw2
sudo ip link set veth-giulia netns ns-giuliaA questo punto i cavi esistono ma le interfacce sono ancora spente e senza IP. E' come aver collegato i cavi in Packet Tracer ma non aver ancora configurato gli IP sulle interfacce - le linee sono verdi ma non passa niente.
Per verificare cosa e' stato creato nel host namespace:
ip link show | grep veth# le prime 3 righe (veth012dcee, veth2f919ce, veth85d8349) sono di Wazuh - gia' presenti, ignorate
6: veth012dcee@if2: ... master wazuh-br0 state UP <- Wazuh, non toccare
7: veth2f919ce@if2: ... master wazuh-br0 state UP <- Wazuh, non toccare
8: veth85d8349@if2: ... master wazuh-br0 state UP <- Wazuh, non toccare
# queste sono le nostre:
10: veth-host@if9: state DOWN <- lato host del link verso ns-fw1 (outside)
12: veth-fw1-dmz-br@if13: master br-dmz state DOWN <- ns-fw1 collegato al bridge DMZ
14: veth-sofia-br@if14: master br-dmz state LOWERLAYERDOWN <- ns-sofia collegata al bridge DMZ
16: veth-fw2-dmz-br@if17: master br-dmz state LOWERLAYERDOWN <- ns-fw2 collegata al bridge DMZ
19: veth-fw2-lan@if18: state DOWN <- lato host del link verso ns-giuliaLOWERLAYERDOWN significa che l'altra meta' del veth pair (quella dentro il namespace) e' ancora spenta. Normale - non abbiamo ancora fatto ip link set up sulle interfacce interne.
Dentro ogni namespace:
sudo ip netns exec ns-fw1 ip link show
sudo ip netns exec ns-sofia ip link show
sudo ip netns exec ns-fw2 ip link show
sudo ip netns exec ns-giulia ip link show# ns-fw1: due interfacce, entrambe DOWN
9: veth-fw1-out@if10 state DOWN <- verso host (Kali arrivera' da qui)
13: veth-fw1-dmz@if12 state DOWN <- verso bridge DMZ (Sofia e FW2)
# ns-sofia: una interfaccia, DOWN
15: veth-sofia@if14 state DOWN <- verso bridge DMZ
# ns-fw2: una interfaccia, DOWN
17: veth-fw2-dmz@if16 state DOWN <- verso bridge DMZ (FW1 e Sofia)
# ns-giulia: una interfaccia, DOWN
18: veth-giulia@if19 state DOWN <- verso ns-fw2Tutti i cavi sono collegati, nessuna interfaccia e' attiva. Il prossimo passo e' assegnare gli IP e fare ip link set up su ogni interfaccia.
Nota: topologia L2 vs routing#
mindmap
root((Topologia L2 vs routing))
Cisco lab
Kali Mac FW1 stessa rete L2
Stesso switch fisico
Linux lab
Routing L3 attraverso Ubuntu host
Kali manda a Ubuntu
Ubuntu gira a ns-fw1 via ip forward
Percorso pacchetto
Kali 192.168.64.200
Ubuntu enp0s1 poi veth-host 10.0.0.1
ns-fw1 veth-fw1-out 10.0.0.2
Nel lab Cisco il segmento esterno aveva tre partecipanti sulla stessa rete L2: Kali, Mac (gateway UTM) e FW1 outside. In questo lab usiamo routing L3 attraverso Ubuntu host - piu' semplice, stessa sostanza.
Kali VM (192.168.64.200)
| ip route add 10.0.0.0/30 via 192.168.64.3
v
Ubuntu host (192.168.64.3)
enp0s1 <- interfaccia fisica verso la rete UTM host-only (192.168.64.0/24)
| ip_forward attivo: riceve su enp0s1, gira su veth-host
| veth-host 10.0.0.1/30
v
ns-fw1 veth-fw1-out 10.0.0.2/30enp0s1 e' il nome che Linux assegna alla prima interfaccia ethernet fisica di Ubuntu - in UTM su Apple Silicon corrisponde all'adattatore di rete virtuale connesso alla rete host-only 192.168.64.0/24. E' l'interfaccia su cui arrivano i pacchetti di Kali prima che ip_forward li giri verso ns-fw1.
Kali non si accorge di Ubuntu: manda il pacchetto verso 10.0.0.2 e Ubuntu lo instrada nel namespace tramite ip_forward. L'isolamento tra zone e' garantito dalla struttura dei namespace stessi - ns-sofia non ha nessuna interfaccia verso il link esterno, fisicamente il collegamento non esiste.
Configurazione IP#
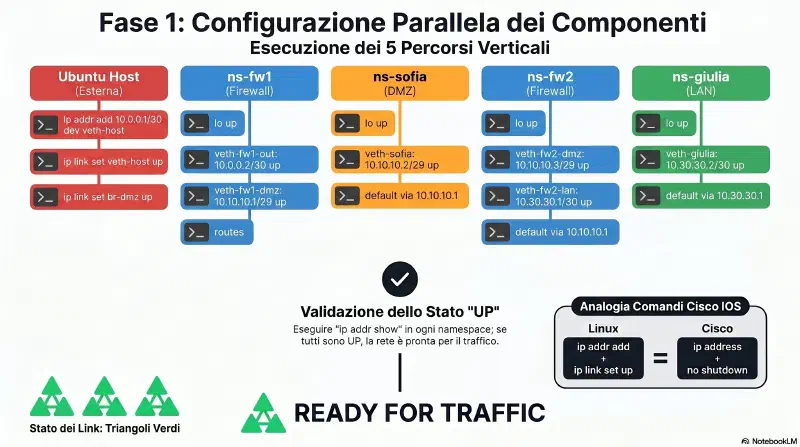
Per completezza: nel lab Cisco siamo all'equivalente di cisco-packet-tracer-dmz#FW1 - configurazione|FW1 - configurazione — la parte
ip address+no shutdown. Ilnameife ilsecurity-levelarrivano dopo con iptables.
In Cisco Packet Tracer a questo punto avremmo tutti i triangoli rossi: i cavi sono collegati ma le interfacce sono in shutdown. Assegnare gli IP e fare ip link set up e' l'equivalente di no shutdown + ip address su ogni interfaccia.
# --- host namespace ---
# veth-host e' il lato Ubuntu del link verso ns-fw1.
# in Cisco era il gateway UTM sulla rete esterna - non un dispositivo del lab,
# ma serve un IP per fare da nexthop quando Kali manda traffico verso 10.0.0.2
sudo ip addr add 10.0.0.1/30 dev veth-host
sudo ip link set veth-host up
# attiva il bridge DMZ - lo switch virtuale che collega FW1, Sofia e FW2
sudo ip link set br-dmz up
# --- ns-fw1 ---
# equivalente di FW1 Gig1/1 outside: ip address 10.0.0.2 255.255.255.252 + no shutdown
sudo ip netns exec ns-fw1 ip link set lo up
sudo ip netns exec ns-fw1 ip addr add 10.0.0.2/30 dev veth-fw1-out
sudo ip netns exec ns-fw1 ip link set veth-fw1-out up
# equivalente di FW1 Gig1/2 dmz: ip address 10.10.10.1 255.255.255.248 + no shutdown
sudo ip netns exec ns-fw1 ip addr add 10.10.10.1/29 dev veth-fw1-dmz
sudo ip netns exec ns-fw1 ip link set veth-fw1-dmz up
# equivalente di "route outside 0.0.0.0 0.0.0.0 10.0.0.1"
sudo ip netns exec ns-fw1 ip route add default via 10.0.0.1
# equivalente di "route dmz 10.30.30.0 255.255.255.252 10.10.10.3"
sudo ip netns exec ns-fw1 ip route add 10.30.30.0/30 via 10.10.10.3A questo punto ns-fw1 ha due interfacce su due reti diverse: 10.0.0.2/30 su veth-fw1-out (outside) e 10.10.10.1/29 su veth-fw1-dmz (dmz). Ha letteralmente "un piede" in ciascuna rete - ed e' proprio questo che lo rende un router e non un host qualunque.
Per le reti a cui e' collegato direttamente, il kernel non ha bisogno di istruzioni: appena assegni un IP a un'interfaccia, Linux aggiunge da solo una rotta "kernel" per quella subnet. Per tutto il resto, ns-fw1 guarda la sua routing table riga per riga:
default via 10.0.0.1- il gateway, il "prossimo salto" per qualsiasi destinazione che non compare in nessun'altra riga. E' la rotta verso Ubuntu/Kali, sull'interfaccia outside.10.30.30.0/30 via 10.10.10.3- ns-fw1 non ha un'interfaccia sulla LAN, ma sa che ns-fw2 (10.10.10.3, raggiungibile sullo stesso bridge DMZ) sa come arrivarci. Per quella rete specifica, il prossimo salto non e' il default gateway ma ns-fw2.
Senza questa seconda riga, un pacchetto diretto a 10.30.30.2 (ns-giulia) prenderebbe il default gateway e finirebbe verso Ubuntu/Kali invece che verso la LAN. Una rotta esplicita per la rete di destinazione vince sempre sul default: il default e' solo il "non so cosa farne, prova di la'".
Il /30 e il /29 sono la subnet mask in notazione CIDR: dicono quanti indirizzi appartengono a quella rete. /30 = 4 indirizzi (2 usabili, il link outside tra ns-fw1 e Ubuntu), /29 = 8 indirizzi (6 usabili, la DMZ condivisa da FW1, Sofia e FW2). Il router non deve conoscere ogni singolo host della rete: sa che tutto cio' che rientra in quel range e' raggiungibile su quell'interfaccia - o, per le reti remote come la LAN, tramite il next-hop indicato in tabella.
# --- ns-sofia ---
# equivalente di Sofia/nginx: ip address 10.10.10.2 + gateway 10.10.10.1
sudo ip netns exec ns-sofia ip link set lo up
sudo ip netns exec ns-sofia ip addr add 10.10.10.2/29 dev veth-sofia
sudo ip netns exec ns-sofia ip link set veth-sofia up
sudo ip netns exec ns-sofia ip route add default via 10.10.10.1
# --- ns-fw2 ---
# equivalente di FW2 Gig1/1 dmz: ip address 10.10.10.3 255.255.255.248 + no shutdown
sudo ip netns exec ns-fw2 ip link set lo up
sudo ip netns exec ns-fw2 ip addr add 10.10.10.3/29 dev veth-fw2-dmz
sudo ip netns exec ns-fw2 ip link set veth-fw2-dmz up
# equivalente di FW2 Gig1/2 inside: ip address 10.30.30.1 255.255.255.252 + no shutdown
sudo ip netns exec ns-fw2 ip addr add 10.30.30.1/30 dev veth-fw2-lan
sudo ip netns exec ns-fw2 ip link set veth-fw2-lan up
# equivalente di "route dmz 0.0.0.0 0.0.0.0 10.10.10.1"
sudo ip netns exec ns-fw2 ip route add default via 10.10.10.1
# --- ns-giulia ---
# equivalente di Giulia/MySQL: ip address 10.30.30.2 + gateway 10.30.30.1
sudo ip netns exec ns-giulia ip link set lo up
sudo ip netns exec ns-giulia ip addr add 10.30.30.2/30 dev veth-giulia
sudo ip netns exec ns-giulia ip link set veth-giulia up
sudo ip netns exec ns-giulia ip route add default via 10.30.30.1Verifica finale - tutti gli IP assegnati:
sudo ip netns exec ns-fw1 ip addr show
sudo ip netns exec ns-sofia ip addr show
sudo ip netns exec ns-fw2 ip addr show
sudo ip netns exec ns-giulia ip addr show# ns-fw1
9: veth-fw1-out@if10 inet 10.0.0.2/30 state UP
13: veth-fw1-dmz@if12 inet 10.10.10.1/29 state UP
# ns-sofia
15: veth-sofia@if14 inet 10.10.10.2/29 state UP
# ns-fw2
17: veth-fw2-dmz@if16 inet 10.10.10.3/29 state UP
19: veth-fw2-lan@if18 inet 10.30.30.1/30 state UP
# ns-giulia
18: veth-giulia@if19 inet 10.30.30.2/30 state UPTutti UP, tutti gli IP corretti. In Cisco Packet Tracer i triangoli sarebbero diventati verdi.
flowchart LR
classDef ext fill:#4a0d0d,stroke:#e05555,color:#eee
classDef hub fill:#1a1a2d,stroke:#8888cc,color:#eee
classDef fw fill:#0d1a3d,stroke:#4a9eff,color:#eee
classDef dmz fill:#3d2a0d,stroke:#ffaa4a,color:#eee
classDef lan fill:#0d2d15,stroke:#4aff7e,color:#eee
KALI["Kali
192.168.64.200"]:::ext
UBU["Ubuntu host
veth-host
10.0.0.1/30"]:::hub
subgraph FW1["ns-fw1"]
FW1OUT["veth-fw1-out
10.0.0.2/30"]:::fw
FW1DMZ["veth-fw1-dmz
10.10.10.1/29"]:::fw
end
BRDMZ{{"br-dmz
L2 bridge"}}:::hub
SOFIA["ns-sofia
veth-sofia
10.10.10.2/29"]:::dmz
subgraph FW2["ns-fw2"]
FW2DMZ["veth-fw2-dmz
10.10.10.3/29"]:::fw
FW2LAN["veth-fw2-lan
10.30.30.1/30"]:::fw
end
GIULIA[("ns-giulia
veth-giulia
10.30.30.2/30")]:::lan
KALI --- UBU --- FW1OUT
FW1OUT --- FW1DMZ
FW1DMZ --- BRDMZ
BRDMZ --- SOFIA
BRDMZ --- FW2DMZ
FW2DMZ --- FW2LAN
FW2LAN --- GIULIA
La topologia Linux e' identica al cisco-packet-tracer-dmz|lab Cisco a questo punto: dispositivi configurati, link attivi. Quello che in Cisco era ip address + no shutdown, in Linux e' ip addr add + ip link set up.
Rotte su Ubuntu e Kali#
mindmap
root((Rotte su Ubuntu e Kali))
Ubuntu host
Conosce solo 10.0.0.0/30
Aggiunge DMZ 10.10.10.0/29 via 10.0.0.2
Aggiunge LAN 10.30.30.0/30 via 10.0.0.2
Kali VM
Default via 192.168.64.1
Aggiunge 10.0.0.0/30 via Ubuntu
Aggiunge DMZ via Ubuntu
Aggiunge LAN via Ubuntu
Rotte effimere
Spariscono al reboot
Incluse in setup-dmz.sh
Verifica
ip route list
Nel lab Cisco, Kali aveva 10.0.0.2 (FW1) come default gateway e raggiungeva tutto attraverso di esso. In Linux il percorso e' a due hop: Kali → Ubuntu → ns-fw1. Questo richiede rotte esplicite su entrambe le macchine.
Su Ubuntu host - Ubuntu sa solo raggiungere 10.0.0.0/30 via veth-host. Non conosce DMZ e LAN. Aggiungiamo le rotte puntando a ns-fw1 (10.0.0.2) come nexthop:
sudo ip route add 10.10.10.0/29 via 10.0.0.2 dev veth-host
sudo ip route add 10.30.30.0/30 via 10.0.0.2 dev veth-hostSu Kali - Kali ha solo la rotta per 10.0.0.0/30. Aggiungiamo DMZ e LAN via Ubuntu (192.168.64.3):
sudo ip route add 10.10.10.0/29 via 192.168.64.3
sudo ip route add 10.30.30.0/30 via 192.168.64.3Verifica su entrambe le macchine:
ip route listUbuntu dopo le aggiunte:
default via 192.168.64.1 dev enp0s1
10.0.0.0/30 dev veth-host proto kernel scope link src 10.0.0.1
10.10.10.0/29 via 10.0.0.2 dev veth-host
10.30.30.0/30 via 10.0.0.2 dev veth-host
192.168.64.0/24 dev enp0s1 proto kernel scope link src 192.168.64.3Kali dopo le aggiunte:
default via 192.168.64.1 dev eth0 onlink
10.0.0.0/30 via 192.168.64.3 dev eth0
10.10.10.0/29 via 192.168.64.3 dev eth0
10.30.30.0/30 via 192.168.64.3 dev eth0
192.168.64.0/24 dev eth0 proto kernel scope link src 192.168.64.200Con queste rotte Kali raggiunge ns-fw1 (10.10.10.1) con TTL=63 — un solo hop L3 (Ubuntu):
# da Kali
ping -c3 10.10.10.1
# 64 bytes from 10.10.10.1: icmp_seq=1 ttl=63 time=1.33 ms
# 3 packets transmitted, 3 received, 0% packet lossAnche queste rotte sono effimere — spariscono al reboot di Ubuntu e Kali, esattamente come i namespace. Lo script setup-dmz.sh le includere'.
ip_forward - il kernel diventa un router#
Cisco: in cisco-packet-tracer-routing|Cinque Router, Una Catena, Nessun GPS ogni nodo della catena - Aldo, Marco, Sofia, Luca, Giulia - e' un router Cisco:
ip routinge' attivo di default su IOS, instrada sempre secondo la sua routing table, nessun interruttore da girare. Nel cisco-packet-tracer-dmz|lab DMZ invece Sofia/nginx e Giulia/MySQL sono PC - dispositivi che non instradano mai, per natura, anche se conoscono la rotta. FW1 e FW2 sono ASA, e instradano come i router della catena.In Linux non esiste questa distinzione "per tipo di dispositivo" - ogni namespace nasce come uno stack IP identico agli altri.
ip_forwarde' l'interruttore che decide se quel namespace si comporta come i router della catena (instrada sempre) o come un PC della DMZ (instrada solo se e' lui il destinatario).
ip_forward dice al kernel: "se ricevi un pacchetto che non e' destinato a te, non dropparlo - instradalo verso la destinazione giusta." Senza di esso ogni namespace si comporta come un host finale, non come un router.
La differenza e' tra L2 e L3. A livello 2 un'interfaccia riceve un frame se il MAC di destinazione e' il suo - vale per chiunque, host o router: e' l'ARP che risolve "chi ha questo IP" nel MAC giusto, a prescindere da cosa succedera' dopo. La domanda vera e' cosa fa il namespace a livello 3, quando l'IP di destinazione nel pacchetto non e' uno dei suoi: con ip_forward=0 lo droppa (comportamento host), con ip_forward=1 guarda la routing table e lo inoltra sull'interfaccia giusta (comportamento router).
Il comportamento senza ip_forward si capisce confrontando due ping da ns-fw1:
# ping verso ns-sofia (10.10.10.2) - stessa subnet DMZ, stesso bridge
sudo ip netns exec ns-fw1 ping -c3 10.10.10.2
# 64 bytes from 10.10.10.2: icmp_seq=1 ttl=64 time=0.107 ms <- FUNZIONA
# 64 bytes from 10.10.10.2: icmp_seq=2 ttl=64 time=0.114 ms
# 64 bytes from 10.10.10.2: icmp_seq=3 ttl=64 time=0.097 ms
# ping verso ns-giulia (10.30.30.2) - subnet diversa, richiede routing
sudo ip netns exec ns-fw1 ping -c3 10.30.30.2
# 3 packets transmitted, 0 received, 100% packet loss <- FALLISCEPerche' uno funziona e l'altro no: ns-sofia e' sulla stessa subnet 10.10.10.0/29 e sullo stesso bridge br-dmz. Il pacchetto viaggia a livello 2 - il bridge lo commuta direttamente in base al MAC, nessun routing necessario, nessun ip_forward coinvolto.
ns-giulia e' su una subnet diversa 10.30.30.0/30. ns-fw1 guarda la sua routing table, trova la rotta 10.30.30.0/30 via 10.10.10.3 e manda il pacchetto verso ns-fw2. A L2 ns-fw2 lo riceve regolarmente: l'ARP ha risolto 10.10.10.3 nel MAC di veth-fw2-dmz, il frame e' indirizzato a lui e lo prende. Ma a L3 ns-fw2 guarda l'IP di destinazione, 10.30.30.2, e non e' un suo indirizzo: senza ip_forward=1 lo droppa li'. Ricevere il frame (L2) e instradare il pacchetto (L3) sono due cose diverse - ed e' la seconda quella che manca.
In Cisco era la stessa logica: stessa VLAN = lo switch commuta senza coinvolgere il firewall. Subnet diversa = il pacchetto passa per l'ASA - che, essendo un ASA e non un PC, instrada sempre per natura: la security-level/ACL decide se PUO' farlo, non se SA farlo.
Il terzo caso e' Kali verso ns-fw1: il pacchetto arriva su Ubuntu ma Ubuntu lo droppa prima che entri nel namespace.
Su Kali la routing table e' corretta - la rotta c'e', i pacchetti partono:
# su Kali VM
sudo ip route add 10.0.0.0/30 via 192.168.64.3
ip route list
# default via 192.168.64.1 dev eth0 onlink
# 10.0.0.0/30 via 192.168.64.3 dev eth0 <- rotta verso il lab
# 192.168.64.0/24 dev eth0 proto kernel scope link src 192.168.64.200
ping -c3 10.0.0.2
# PING 10.0.0.2 (10.0.0.2) 56(84) bytes of data.
# 3 packets transmitted, 0 received, 100% packet loss, time 2029msI pacchetti escono da Kali, arrivano su Ubuntu (192.168.64.3), ma Ubuntu con ip_forward=0 li droppa: la destinazione 10.0.0.2 non e' una sua interfaccia, quindi li scarta invece di girarli a ns-fw1 tramite veth-host.
Per abilitarlo nei namespace che fanno da router:
# host namespace: Ubuntu deve poter girare i pacchetti di Kali verso ns-fw1.
# senza questo, i pacchetti di Kali arrivano su enp0s1 e vengono droppati
# prima ancora di entrare nel namespace
sudo sysctl -w net.ipv4.ip_forward=1
# ns-fw1: deve poter instradare tra la sua interfaccia outside (10.0.0.2)
# e la sua interfaccia dmz (10.10.10.1) — equivalente del routing interno dell'ASA
sudo ip netns exec ns-fw1 sysctl -w net.ipv4.ip_forward=1
# ns-fw2: deve poter instradare tra dmz (10.10.10.3) e lan (10.30.30.1).
# e' il passaggio critico: senza questo ns-giulia e' irraggiungibile da qualsiasi zona
sudo ip netns exec ns-fw2 sysctl -w net.ipv4.ip_forward=1Con ip_forward attivo su tutti e tre, i TTL raccontano esattamente cosa sta succedendo:
# ns-fw1 → ns-sofia (10.10.10.2) — stesso bridge L2
sudo ip netns exec ns-fw1 ping -c3 10.10.10.2
# 64 bytes from 10.10.10.2: ttl=64 <- TTL intatto, nessun hop di routing
# ns-fw1 → ns-giulia (10.30.30.2) — attraversa ns-fw2
sudo ip netns exec ns-fw1 ping -c3 10.30.30.2
# 64 bytes from 10.30.30.2: ttl=63 <- TTL decrementato di 1: ns-fw2 ha instradato
# Kali → ns-fw1 (10.0.0.2) — attraversa Ubuntu host
ping -c3 10.0.0.2
# 64 bytes from 10.0.0.2: ttl=63 <- TTL decrementato di 1: Ubuntu host ha instradatoTTL=64: il pacchetto ha viaggiato solo a L2, nessun router coinvolto. TTL=63: un hop L3 - un namespace (o Ubuntu host) ha fatto da router e decrementato il TTL.
Il TTL e' 63, non 64 - e' la prova che ip_forward sta funzionando.
packet-beta
0-3: "Version (4)"
4-7: "IHL"
8-15: "DSCP / ECN"
16-31: "Total Length"
32-47: "Identification"
48-50: "Flags"
51-63: "Fragment Offset"
64-71: "TTL ← decrementa ad ogni hop"
72-79: "Protocol"
80-95: "Header Checksum"
96-127: "Source IP"
128-159: "Destination IP"
TTL: cos'e' e perche' parte da 64
TTL (Time To Live) e' un contatore nel header IP che impedisce ai pacchetti di girare in loop all'infinito. Ogni router che instrada il pacchetto lo decrementa di 1. Quando arriva a 0, il pacchetto viene droppato e il mittente riceve un messaggio ICMP "Time Exceeded".
Linux usa 64 come valore di default per convenzione storica (RFC 791 non imponeva un valore specifico). E' una potenza di 2 sufficiente per attraversare qualsiasi rete reale - internet ha mediamente 15-20 hop. Windows usa 128, Cisco router usano 255.
Perche' 63 prova che ip_forward funziona: il pacchetto e' partito da Kali con TTL=64. Ubuntu l'ha ricevuto su enp0s1 e instradato verso ns-fw1 tramite veth-host - questo e' un hop L3, quindi TTL decrementato a 63. Se Kali e ns-fw1 fossero sullo stesso segmento L2 diretto, non ci sarebbe nessun hop di routing e il TTL arriverebbe intatto a 64.
Il TTL e' anche una tecnica di OS fingerprinting: se ricevi una risposta con TTL=64 il sistema e' probabilmente Linux, TTL=128 e' Windows, TTL=255 e' un router Cisco. Strumenti come nmap usano questo per identificare il sistema operativo remoto senza inviare nessuna probe specifica.
Wazuh/Docker e ip_forward
Sul server di lab ip_forward era gia' abilitato in tutti i namespace prima che lo configurassimo — Docker lo abilita a livello di sistema all'avvio perche' ne ha bisogno per il networking dei container, e i nuovi namespace Linux ereditano quel valore.
Per fare la lezione in modo pulito lo abbiamo disabilitato manualmente:
sudo sysctl -w net.ipv4.ip_forward=0
sudo ip netns exec ns-fw1 sysctl -w net.ipv4.ip_forward=0
sudo ip netns exec ns-fw2 sysctl -w net.ipv4.ip_forward=0In un ambiente senza Docker questo passaggio non sarebbe necessario — ip_forward sarebbe 0 per default.
Ping matrix - chi raggiunge chi e perche'#
Tutti i test qui sotto sono eseguiti prima di iptables -P FORWARD DROP — nessuna regola ancora, ip_forward attivo su tutti i namespace. L'obiettivo e' mappare il comportamento di default della rete prima di mettere i muri.
Test 1 - Kali → ns-fw1 (10.0.0.2)#
mindmap
root((Test 1))
Kali a ns-fw1
TTL 63
Un hop L3 Ubuntu
Risultato PASS
| Mittente | Kali VM 192.168.64.200 |
| Destinazione | ns-fw1 10.0.0.2 |
| TTL ricevuto | 63 |
| Risultato | FUNZIONA |
# da Kali VM
ping -c3 10.0.0.2
# 64 bytes from 10.0.0.2: icmp_seq=1 ttl=63 time=2.08 ms
# 3 packets transmitted, 3 received, 0% packet lossTTL=63: Ubuntu host ha fatto un hop L3 — ha ricevuto il pacchetto su enp0s1 e lo ha girato verso ns-fw1 tramite veth-host.
Test 2 - Kali → ns-sofia (10.10.10.2)#
mindmap
root((Test 2))
Kali a ns-sofia
TTL 62
Due hop Ubuntu poi ns-fw1
Risultato PASS
| Mittente | Kali VM 192.168.64.200 |
| Destinazione | ns-sofia 10.10.10.2 |
| TTL ricevuto | 62 |
| Risultato | FUNZIONA |
# da Kali VM
ping -c3 10.10.10.2
# 64 bytes from 10.10.10.2: icmp_seq=1 ttl=62 time=2.52 ms
# 3 packets transmitted, 3 received, 0% packet lossTTL=62: due hop L3 — Ubuntu instrada verso ns-fw1, ns-fw1 instrada verso ns-sofia tramite br-dmz.
Test 3 - Kali → ns-giulia (10.30.30.2)#
mindmap
root((Test 3))
Kali a ns-giulia
TTL 61
Tre hop Ubuntu ns-fw1 ns-fw2
Risultato PASS
| Mittente | Kali VM 192.168.64.200 |
| Destinazione | ns-giulia 10.30.30.2 |
| TTL ricevuto | 61 |
| Risultato | FUNZIONA |
# da Kali VM
ping -c3 10.30.30.2
# 64 bytes from 10.30.30.2: icmp_seq=1 ttl=61 time=8.10 ms
# 3 packets transmitted, 3 received, 0% packet lossTTL=61: tre hop L3 — Ubuntu → ns-fw1 → ns-fw2 → ns-giulia. Il TTL e' una mappa del percorso: ogni decremento e' un router attraversato.
| Destinazione | TTL | Hop |
|---|---|---|
ns-fw1 10.0.0.2 | 63 | Ubuntu |
ns-sofia 10.10.10.2 | 62 | Ubuntu → ns-fw1 |
ns-giulia 10.30.30.2 | 61 | Ubuntu → ns-fw1 → ns-fw2 |
Test 4 - ns-sofia → ns-fw1 (10.10.10.1)#
mindmap
root((Test 4))
ns-sofia a ns-fw1
TTL 64 intatto
Stesso bridge L2
Risultato PASS
| Mittente | ns-sofia 10.10.10.2 |
| Destinazione | ns-fw1 10.10.10.1 |
| TTL ricevuto | 64 |
| Risultato | FUNZIONA |
sudo ip netns exec ns-sofia ping -c3 10.10.10.1
# 64 bytes from 10.10.10.1: icmp_seq=1 ttl=64 time=0.050 ms
# 3 packets transmitted, 3 received, 0% packet lossTTL=64: stesso bridge br-dmz, nessun hop L3 — il frame e' commutato direttamente a livello 2.
Test 5 - ns-sofia → ns-fw2 (10.10.10.3)#
mindmap
root((Test 5))
ns-sofia a ns-fw2
TTL 64 intatto
Stesso bridge L2 br-dmz
Risultato PASS
| Mittente | ns-sofia 10.10.10.2 |
| Destinazione | ns-fw2 10.10.10.3 |
| TTL ricevuto | 64 |
| Risultato | FUNZIONA |
sudo ip netns exec ns-sofia ping -c3 10.10.10.3
# 64 bytes from 10.10.10.3: icmp_seq=1 ttl=64 time=0.218 ms
# 3 packets transmitted, 3 received, 0% packet lossTTL=64: ns-fw1, ns-sofia e ns-fw2 sono tutti sul bridge br-dmz — stesso segmento L2, nessun routing.
Test 6 - ns-sofia → host esterno (10.0.0.1)#
mindmap
root((Test 6))
ns-sofia a veth-host
TTL 63
Un hop L3 ns-fw1
Risultato PASS
| Mittente | ns-sofia 10.10.10.2 |
| Destinazione | veth-host 10.0.0.1 |
| TTL ricevuto | 63 |
| Risultato | FUNZIONA |
sudo ip netns exec ns-sofia ping -c3 10.0.0.1
# 64 bytes from 10.0.0.1: icmp_seq=1 ttl=63 time=1.37 ms
# 3 packets transmitted, 3 received, 0% packet lossTTL=63: ns-sofia usa il default route via ns-fw1 (un hop L3), poi ns-fw1 consegna direttamente su 10.0.0.0/30 dove vive veth-host.
Test 7 - ns-sofia → ns-giulia (10.30.30.2)#
mindmap
root((Test 7))
ns-sofia a ns-giulia
TTL 63
Un hop L3 ns-fw2
ICMP Redirect da ns-fw1
Risultato PASS
Attenzione
Redirect vettore di attacco
Disabilitare in produzione
| Mittente | ns-sofia 10.10.10.2 |
| Destinazione | ns-giulia 10.30.30.2 |
| TTL ricevuto | 63 |
| Risultato | FUNZIONA |
sudo ip netns exec ns-sofia ping -c3 10.30.30.2
# From 10.10.10.1: icmp_seq=1 Redirect Host(New nexthop: 10.10.10.3)
# 64 bytes from 10.30.30.2: icmp_seq=1 ttl=63 time=0.209 ms
# 3 packets transmitted, 3 received, 0% packet lossTTL=63: un hop L3 attraverso ns-fw2. ns-fw1 invia un ICMP Redirect — ns-sofia ha default route via ns-fw1 (10.10.10.1), ma ns-fw1 si accorge che il nexthop corretto (ns-fw2 10.10.10.3) e' sullo stesso bridge e suggerisce a ns-sofia di andarci direttamente. In produzione si disabilita: e' un vettore di attacco per dirottare il traffico. Su ASA Cisco e' disabilitato per default.
Test 8 - ns-giulia → ns-fw2 (10.30.30.1)#
mindmap
root((Test 8))
ns-giulia a ns-fw2
TTL 64 intatto
Link diretto su 10.30.30.0/30
Risultato PASS
| Mittente | ns-giulia 10.30.30.2 |
| Destinazione | ns-fw2 10.30.30.1 |
| TTL ricevuto | 64 |
| Risultato | FUNZIONA |
sudo ip netns exec ns-giulia ping -c3 10.30.30.1
# 64 bytes from 10.30.30.1: icmp_seq=1 ttl=64 time=0.056 ms
# 3 packets transmitted, 3 received, 0% packet lossTTL=64: stesso link /30 diretto tra ns-giulia e ns-fw2, nessun hop di routing.
Test 9 - ns-giulia → ns-sofia (10.10.10.2)#
mindmap
root((Test 9))
ns-giulia a ns-sofia
TTL 62 della risposta
Due hop ns-fw2 poi ns-fw1
Risultato PASS
| Mittente | ns-giulia 10.30.30.2 |
| Destinazione | ns-sofia 10.10.10.2 |
| TTL ricevuto | 62 |
| Risultato | FUNZIONA |
sudo ip netns exec ns-giulia ping -c3 10.10.10.2
# 64 bytes from 10.10.10.2: icmp_seq=1 ttl=62 time=0.111 ms
# 3 packets transmitted, 3 received, 0% packet lossTTL=62: il ping mostra il TTL della risposta, non della richiesta. La risposta parte da ns-sofia con TTL=64 e attraversa due hop L3 prima di arrivare a ns-giulia: ns-sofia usa il default route via ns-fw1 (primo hop, TTL→63), poi ns-fw1 instrada verso ns-fw2 (secondo hop, TTL→62), e ns-fw2 consegna a ns-giulia sullo stesso link diretto.
Riepilogo ping matrix#
mindmap
root((Riepilogo ping matrix))
Da Kali
ns-fw1 TTL 63 uno hop
ns-sofia TTL 62 due hop
ns-giulia TTL 61 tre hop
Da ns-sofia
ns-fw1 TTL 64 L2 bridge
ns-fw2 TTL 64 L2 bridge
veth-host TTL 63 ns-fw1
ns-giulia TTL 63 ns-fw2
Da ns-giulia
ns-fw2 TTL 64 link diretto
ns-sofia TTL 62 reply via ns-fw2 ns-fw1
| Test | Mittente | Destinazione | TTL | Hop |
|---|---|---|---|---|
| 1 | Kali | ns-fw1 10.0.0.2 | 63 | Ubuntu |
| 2 | Kali | ns-sofia 10.10.10.2 | 62 | Ubuntu → ns-fw1 |
| 3 | Kali | ns-giulia 10.30.30.2 | 61 | Ubuntu → ns-fw1 → ns-fw2 |
| 4 | ns-sofia | ns-fw1 10.10.10.1 | 64 | L2 bridge |
| 5 | ns-sofia | ns-fw2 10.10.10.3 | 64 | L2 bridge |
| 6 | ns-sofia | veth-host 10.0.0.1 | 63 | ns-fw1 |
| 7 | ns-sofia | ns-giulia 10.30.30.2 | 63 | ns-fw2 |
| 8 | ns-giulia | ns-fw2 10.30.30.1 | 64 | link diretto |
| 9 | ns-giulia | ns-sofia 10.10.10.2 | 62 | ns-fw2 → ns-fw1 (reply) |
Tutti FUNZIONANO — nessuna regola iptables ancora. Il prossimo passo: iptables -P FORWARD DROP. Da questo momento tutto e' bloccato per default e apriremo solo quello che serve, esattamente come fa un ASA Cisco per default.
flowchart LR
classDef ext fill:#4a0d0d,stroke:#e05555,color:#eee
classDef hub fill:#1a1a2d,stroke:#8888cc,color:#eee
classDef fw fill:#0d1a3d,stroke:#4a9eff,color:#eee
classDef dmz fill:#3d2a0d,stroke:#ffaa4a,color:#eee
classDef lan fill:#0d2d15,stroke:#4aff7e,color:#eee
KALI["Kali
TTL=64"]:::ext
UBU["Ubuntu host
L3 — TTL 64→63"]:::hub
FW1["ns-fw1
10.0.0.2
TTL=63 in, L3 — TTL 63→62"]:::fw
BRDMZ{{"br-dmz
L2 bridge
TTL invariato"}}:::hub
SOFIA["ns-sofia
10.10.10.2
TTL=62"]:::dmz
FW2["ns-fw2
10.10.10.3
TTL=62 in, L3 — TTL 62→61"]:::fw
GIULIA[("ns-giulia
10.30.30.2
TTL=61")]:::lan
KALI --> UBU --> FW1 --> BRDMZ
BRDMZ --> SOFIA
BRDMZ --> FW2 --> GIULIA
iptables default DROP - il security-level#
Cisco: cisco-packet-tracer-dmz#FW1 - configurazione|FW1 - configurazione — su un ASA Cisco il traffico da zona a security-level piu' basso verso zona a security-level piu' alto e' bloccato per default. Nessuna ACL = nessun transito.
iptables -P FORWARD DROPe' la stessa policy: la chain e' vuota, tutto cade nella policy di default.
| Stato attuale | Obiettivo | Come | |
|---|---|---|---|
| Kali → Sofia :qualsiasi | ✓ PASS | ✗ DROP | -P FORWARD DROP su FW1 |
| Sofia → Giulia :qualsiasi | ✓ PASS | ✗ DROP | -P FORWARD DROP su FW2 |
| Kali → Giulia :qualsiasi | ✓ PASS | ✗ DROP | DROP su FW1 + FW2 in cascata |
# ns-fw1: blocca tutto il traffico in transito.
# equivalente di: access-group outside_access_in in interface outside (deny-all implicito)
sudo ip netns exec ns-fw1 iptables -P FORWARD DROP
# ns-fw2: LAN isolata per default.
# nessun pacchetto dalla DMZ raggiunge ns-giulia senza una regola esplicita
sudo ip netns exec ns-fw2 iptables -P FORWARD DROPVerifica immediata dopo il DROP — Kali non raggiunge piu' Sofia:
# da Kali VM
ping -c3 10.10.10.2
# 3 packets transmitted, 0 received, 100% packet lossVerifica su ns-fw1 — i pacchetti droppati sono contati dalla policy:
sudo ip netns exec ns-fw1 iptables -L FORWARD -v -n
# Chain FORWARD (policy DROP 3 packets, 252 bytes)La chain e' vuota — nessuna regola esplicita. I 3 pacchetti sono esattamente i 3 ping di Kali, droppati dalla policy di default. Non da una regola, dalla policy. Differenza importante: le regole esplicite (-A FORWARD) compaiono nella lista sopra la policy. La policy e' il catch-all finale per tutto quello che non matcha nessuna regola.
flowchart LR
classDef ext fill:#4a0d0d,stroke:#e05555,color:#eee
classDef fw fill:#3d0d0d,stroke:#ff4444,color:#eee
classDef dmz fill:#2d2010,stroke:#886633,color:#aaa
classDef lan fill:#0d1a0d,stroke:#336633,color:#aaa
KALI["Kali"]:::ext
FW1["ns-fw1
FORWARD DROP
chain vuota"]:::fw
SOFIA["ns-sofia
irraggiungibile"]:::dmz
FW2["ns-fw2
FORWARD DROP
chain vuota"]:::fw
GIULIA[("ns-giulia
irraggiungibile")]:::lan
KALI -. "qualsiasi traffico" .-> FW1
FW1 -. "✗ DROP — nessuna regola" .-> SOFIA
SOFIA -. "qualsiasi traffico" .-> FW2
FW2 -. "✗ DROP — nessuna regola" .-> GIULIA
Isolamento namespace - il test equivalente alle VLAN#
Cisco: su un ASA con security-level configurati, un PC nella LAN non puo' raggiungere la DMZ senza una
access-listesplicita — anche se conosce il percorso. Stesso principio: la policy DROP blocca il transito indipendentemente dal routing.
Tre test dopo iptables -P FORWARD DROP su ns-fw1 e ns-fw2:
ns-giulia → ns-sofia (10.10.10.2)#
mindmap
root((ns-giulia a ns-sofia))
Percorso tentato
ns-giulia a ns-fw2 default gw
ns-fw2 dovrebbe forwardare a DMZ
Risultato DROP
FORWARD chain ns-fw2 policy DROP
Scartato silenziosamente
sudo ip netns exec ns-giulia ping -c3 10.10.10.2
# 3 packets transmitted, 0 received, 100% packet lossIl pacchetto parte da ns-giulia verso il default gateway ns-fw2 (10.30.30.1). ns-fw2 dovrebbe instradarlo verso la DMZ — ma la FORWARD chain di ns-fw2 ha policy DROP. Il pacchetto viene silenziosamente scartato.
ns-sofia → ns-giulia (10.30.30.2)#
mindmap
root((ns-sofia a ns-giulia))
ICMP Redirect da ns-fw1
ns-fw1 suggerisce nexthop ns-fw2
Risultato DROP
ns-fw2 FORWARD chain DROP
Redirect inutile se FW blocca
sudo ip netns exec ns-sofia ping -c3 10.30.30.2
# From 10.10.10.1: icmp_seq=1 Redirect Host(New nexthop: 10.10.10.3)
# From 10.10.10.1: icmp_seq=2 Redirect Host(New nexthop: 10.10.10.3)
# From 10.10.10.1: icmp_seq=3 Redirect Host(New nexthop: 10.10.10.3)
# 3 packets transmitted, 0 received, 100% packet lossns-fw1 manda ancora l'ICMP Redirect (vedi Linux-namespaces-dmz#Test 7 - ns-sofia → ns-giulia|Test 7) suggerendo a Sofia di andare direttamente a ns-fw2. Sofia ci prova — ma ns-fw2 riceve il pacchetto sulla sua interfaccia DMZ e deve instradarlo verso la LAN: FORWARD chain → DROP. Il redirect e' inutile se il firewall successivo blocca comunque.
ns-fw1 → ns-sofia (10.10.10.2)#
mindmap
root((ns-fw1 a ns-sofia))
Risultato PASS
TTL 64 nessun drop
Motivo
ns-fw1 e mittente non transito
Chain OUTPUT non FORWARD
sudo ip netns exec ns-fw1 ping -c3 10.10.10.2
# 64 bytes from 10.10.10.2: icmp_seq=1 ttl=64 time=0.081 ms
# 3 packets transmitted, 3 received, 0% packet lossFunziona — TTL=64, nessun drop. ns-fw1 e' il mittente del pacchetto, non un router di transito. La FORWARD chain si applica solo ai pacchetti che attraversano il namespace da un'interfaccia all'altra. Un pacchetto originato dal namespace stesso passa per la chain OUTPUT, non FORWARD.
| Test | Percorso | Chain coinvolta | Risultato |
|---|---|---|---|
| ns-giulia → ns-sofia | ns-fw2 deve forwardare | FORWARD ns-fw2 | DROP |
| ns-sofia → ns-giulia | ns-fw2 deve forwardare | FORWARD ns-fw2 | DROP |
| ns-fw1 → ns-sofia | ns-fw1 e' il mittente | OUTPUT ns-fw1 | PASS |
La regola e' semplice: FORWARD = traffico in transito. OUTPUT = traffico originato localmente. iptables -P FORWARD DROP non isola il firewall da se stesso — isola le zone tra loro.
flowchart TB
classDef ext fill:#4a0d0d,stroke:#e05555,color:#eee
classDef fw fill:#0d1a3d,stroke:#4a9eff,color:#eee
classDef dmz fill:#3d2a0d,stroke:#ffaa4a,color:#eee
classDef drop fill:#3d0d0d,stroke:#ff4444,color:#eee
classDef pass fill:#0d2d15,stroke:#4aff7e,color:#eee
subgraph TRANSIT["Pacchetto in TRANSITO — chain FORWARD"]
K["Kali"]:::ext -. "SYN verso Sofia" .-> F1T["ns-fw1
FORWARD chain
policy DROP"]:::fw -. "✗ DROP" .-> D["scartato"]:::drop
end
subgraph LOCAL["Pacchetto ORIGINATO da ns-fw1 — chain OUTPUT"]
F1L["ns-fw1
OUTPUT chain
nessun DROP"]:::fw -->|"✓ PASS"| S["ns-sofia
risponde TTL=64"]:::dmz
end
Security-level equivalente: chi puo' parlare con chi#
Cisco: cisco-packet-tracer-dmz#Security-level: chi puo' parlare con chi|Security-level ASA — su un ASA ogni interfaccia ha un security-level da 0 a 100. Il traffico fluisce liberamente da livello alto a livello basso (inside → DMZ → outside), il contrario richiede una
access-listesplicita. In Linux non esiste il concetto di security-level — tutto e' simmetrico e tutto e' bloccato. Ogni direzione richiede una regola esplicita.
| Zona | Cisco security-level | iptables equivalente |
|---|---|---|
| Outside (Kali) | 0 | nessuna interfaccia privilegiata — tutto bloccato |
| DMZ (ns-sofia) | 50 | FORWARD chain ns-fw1: regole esplicite per HTTP/HTTPS |
| Inside (ns-giulia) | 100 | FORWARD chain ns-fw2: regola esplicita per MySQL |
La differenza fondamentale:
In Cisco, inside (100) puo' raggiungere DMZ (50) e outside (0) senza ACL — il traffico fluisce naturalmente verso security-level piu' basso. Il firewall e' asimmetrico per design.
In Linux con iptables, la simmetria e' totale: ns-giulia non puo' raggiungere ns-sofia, e ns-sofia non puo' raggiungere ns-giulia, finche' non esiste una regola esplicita in entrambe le direzioni. Non c'e' gerarchia — c'e' solo permit o deny.
| Direzione | Cisco (default) | iptables (dopo FORWARD DROP) |
|---|---|---|
| Kali → Sofia | DENY (0→50) | DENY |
| Kali → Giulia | DENY (0→100) | DENY |
| Sofia → Kali | PERMIT (50→0) | DENY |
| Sofia → Giulia | DENY (50→100) | DENY |
| Giulia → Sofia | PERMIT (100→50) | DENY |
| Giulia → Kali | PERMIT (100→0) | DENY |
In produzione con iptables si replicano le stesse policy Cisco con regole esplicite — piu' verboso, ma piu' controllabile. Nessun comportamento implicito da ricordare.
Connessioni permesse — stato finale#
flowchart LR
classDef ext fill:#4a0d0d,stroke:#e05555,color:#eee
classDef fw fill:#0d1a3d,stroke:#4a9eff,color:#eee
classDef dmz fill:#3d2a0d,stroke:#ffaa4a,color:#eee
classDef lan fill:#0d2d15,stroke:#4aff7e,color:#eee
KALI["Kali
192.168.64.200"]:::ext
FW1["ns-fw1
FORWARD DROP
ACL: 80, 443"]:::fw
SOFIA["ns-sofia
nginx + WAF
10.10.10.2"]:::dmz
FW2["ns-fw2
FORWARD DROP
ACL: 3306 da Sofia"]:::fw
GIULIA[("ns-giulia
MySQL
10.30.30.2")]:::lan
KALI -->|"TCP 80"| FW1
KALI -->|"TCP 443"| FW1
FW1 -->|"PASS"| SOFIA
SOFIA -->|"TCP 3306"| FW2
FW2 -->|"PASS"| GIULIA
Dove si interrompe e perche'#
flowchart LR
classDef ext fill:#4a0d0d,stroke:#e05555,color:#eee
classDef fw fill:#0d1a3d,stroke:#4a9eff,color:#eee
classDef dmz fill:#3d2a0d,stroke:#ffaa4a,color:#eee
classDef lan fill:#0d2d15,stroke:#4aff7e,color:#eee
classDef drop fill:#1a1a1a,stroke:#666,color:#888
KALI["Kali"]:::ext
FW1["ns-fw1
FORWARD DROP"]:::fw
FW2["ns-fw2
FORWARD DROP"]:::fw
SOFIA["ns-sofia"]:::dmz
GIULIA[("ns-giulia")]:::lan
DROP1["✗ DROP
nessuna ACL per porta 22"]:::drop
DROP2["✗ DROP
nessuna ACL verso LAN"]:::drop
DROP3["✗ DROP
non e' 10.10.10.2"]:::drop
DROP4["✗ DROP
nessuna ACL outbound"]:::drop
DROP5["✗ DROP
nessuna ACL su porta 22"]:::drop
KALI -. "TCP 22 SSH" .-> FW1 -. " " .-> DROP1
KALI -. "TCP 3306 verso LAN" .-> FW1 -. " " .-> DROP2
GIULIA -. "TCP 80 inizia connessione" .-> FW2 -. " " .-> DROP4
SOFIA -. "TCP 3306 altro host DMZ" .-> FW2 -. " " .-> DROP3
SOFIA -. "TCP 22 verso Giulia" .-> FW2 -. " " .-> DROP5
Il ciclo richiesta-risposta — chi inizia e chi risponde#
sequenceDiagram
participant Kali
participant FW1
participant Sofia
participant FW2
participant Giulia
Note over Kali,FW1: ACL: TCP 80 in entrata
Kali->>FW1: SYN TCP 80 → PASS
FW1->>Sofia: SYN forwarded
Note over Sofia,FW1: ACL: ESTABLISHED in uscita
Sofia->>FW1: SYN-ACK → PASS
FW1->>Kali: SYN-ACK forwarded
Note over Sofia,FW2: ACL: TCP 3306 da 10.10.10.2
Sofia->>FW2: SYN TCP 3306 → PASS
FW2->>Giulia: SYN forwarded
Note over Giulia,FW2: ACL: ESTABLISHED in uscita
Giulia->>FW2: SYN-ACK → PASS
FW2->>Sofia: SYN-ACK forwarded
Note over Giulia,FW2: Giulia NON puo' iniziare
Giulia--xFW2: SYN TCP 80 → DROP
iptables ACL su ns-fw1 - HTTP e HTTPS verso ns-sofia#
Cisco: cisco-packet-tracer-dmz#FW1 - configurazione|FW1 ACL — su un ASA le access-list aprono porte specifiche dopo il default deny.
access-list outside_in permit tcp any host 10.10.10.2 eq 80diventa in Linux una regola FORWARD esplicita su ns-fw1.
| Stato attuale | Obiettivo | Come | |
|---|---|---|---|
| Kali → Sofia :80 | ✗ DROP | ✓ PASS | ACCEPT tcp:80 in entrata su FW1 |
| Kali → Sofia :443 | ✗ DROP | ✗ rimane bloccato | nessuna regola per ora |
| Sofia → Kali (risposta) | ✗ DROP | ✓ PASS | ACCEPT ESTABLISHED su FW1 |
Con iptables -P FORWARD DROP attivo, aggiungiamo due regole su ns-fw1: una per i pacchetti in ingresso verso Sofia, una per le risposte.
# apri TCP porta 80 da outside verso DMZ (Kali → ns-sofia)
sudo ip netns exec ns-fw1 iptables -A FORWARD \
-i veth-fw1-out -o veth-fw1-dmz \
-p tcp --dport 80 -j ACCEPT
# permetti il traffico di ritorno: SYN-ACK, ACK, dati in risposta (ns-sofia → Kali)
# ESTABLISHED = connessione gia' aperta, RELATED = traffico correlato (es. ICMP error)
sudo ip netns exec ns-fw1 iptables -A FORWARD \
-i veth-fw1-dmz -o veth-fw1-out \
-m state --state ESTABLISHED,RELATED -j ACCEPTVerifica regole aggiunte:
sudo ip netns exec ns-fw1 iptables -L FORWARD -v -n
# Chain FORWARD (policy DROP 6 packets, 504 bytes)
# pkts bytes target prot opt in out source destination
# 0 0 ACCEPT 6 -- veth-fw1-out veth-fw1-dmz 0.0.0.0/0 0.0.0.0/0 tcp dpt:80
# 0 0 ACCEPT 0 -- veth-fw1-dmz veth-fw1-out 0.0.0.0/0 0.0.0.0/0 state RELATED,ESTABLISHEDI contatori sono a 0 — le regole ci sono ma nessun pacchetto ha ancora attraversato la chain.
Primo test: 0 pacchetti — diagnosi#
mindmap
root((Primo test diagnosi))
Sintomo
nc non riceve niente
Contatori ns-fw1 a zero
Diagnosi
tcpdump ns-fw1 nessun SYN
tcpdump enp0s1 SYN arriva
Ubuntu droppa prima del namespace
Root cause
FORWARD chain Ubuntu host
Docker e ufw policy DROP
Traffico non e Docker non e noto
Listener su ns-sofia, connessione da Kali:
# Ubuntu - terminale 1
sudo ip netns exec ns-sofia nc -l -p 80
# Kali - terminale 2
echo "hello world" | nc 10.10.10.2 80Niente. Pacchetti ancora 0. Il testo non arriva su ns-sofia.
tcpdump su ns-fw1 per vedere se il SYN di Kali arriva sull'interfaccia outside:
sudo ip netns exec ns-fw1 tcpdump -i veth-fw1-out -n
# nessun outputIl pacchetto non arriva nemmeno a ns-fw1. Il problema e' prima — su Ubuntu host.
tcpdump su enp0s1 — l'interfaccia dove Ubuntu riceve i pacchetti di Kali:
sudo tcpdump -i enp0s1 -n host 192.168.64.200
# 20:22:02 IP 192.168.64.200.50882 > 10.10.10.2.80: Flags [S], seq 2068371333 ...
# 20:22:03 IP 192.168.64.200.50882 > 10.10.10.2.80: Flags [S], seq 2068371333 ...
# 20:22:04 IP 192.168.64.200.50882 > 10.10.10.2.80: Flags [S], seq 2068371333 ...Il SYN arriva su Ubuntu — ma non viene inoltrato a ns-fw1. Ubuntu riceve e droppa.
Root cause — FORWARD chain di Ubuntu host:
sudo iptables -L FORWARD -v -n
# Chain FORWARD (policy DROP 68 packets, 4080 bytes)
# pkts bytes target prot opt in out source destination
# 38265 417M DOCKER-USER 0 -- * * 0.0.0.0/0 0.0.0.0/0
# 38265 417M DOCKER-FORWARD 0 -- * * 0.0.0.0/0 0.0.0.0/0
# 95 6348 ufw-before-forward 0 -- * * 0.0.0.0/0 0.0.0.0/0
# 68 4080 ufw-reject-forward 0 -- * * 0.0.0.0/0 0.0.0.0/0
# ...Lo stesso problema di ip_forward: Docker e ufw hanno la loro FORWARD chain sul namespace di default di Ubuntu. Nessuna regola permette il traffico tra enp0s1 e veth-host — tutto cade nella policy DROP del host.
Docker/ufw e la FORWARD chain dell'host
Docker imposta iptables -P FORWARD DROP sull'host e aggiunge le sue catene (DOCKER-USER, DOCKER-FORWARD) per gestire il traffico dei container. ufw aggiunge le sue (ufw-before-forward, ufw-reject-forward). Il traffico del nostro lab non e' Docker e non e' noto a ufw — viene droppato silenziosamente.
In un ambiente senza Docker/ufw la FORWARD chain dell'host avrebbe policy ACCEPT di default e questo problema non si presenterebbe.
Fix — aggiungi regole FORWARD sull'host Ubuntu:
# permetti forwarding da Kali (enp0s1) verso ns-fw1 (veth-host)
# -I inserisce in cima alla chain, prima delle regole Docker/ufw
sudo iptables -I FORWARD -i enp0s1 -o veth-host -j ACCEPT
sudo iptables -I FORWARD -i veth-host -o enp0s1 -j ACCEPTSecondo test: funziona#
mindmap
root((Secondo test funziona))
Fix applicato
iptables -I FORWARD enp0s1 a veth-host
iptables -I FORWARD veth-host a enp0s1
Risultato
hello world arriva su ns-sofia
4 pacchetti per direzione
SYN SYN-ACK ACK dato
# Ubuntu
sudo ip netns exec ns-sofia nc -l -p 80
# Kali
echo "hello world" | nc 10.10.10.2 80Su ns-sofia compare:
hello worldVerifica contatori ns-fw1 dopo il test:
sudo ip netns exec ns-fw1 iptables -L FORWARD -v -n
# Chain FORWARD (policy DROP 6 packets, 504 bytes)
# pkts bytes target prot opt in out
# 4 228 ACCEPT 6 -- veth-fw1-out veth-fw1-dmz tcp dpt:80
# 4 216 ACCEPT 0 -- veth-fw1-dmz veth-fw1-out state RELATED,ESTABLISHED4 pacchetti per direzione: SYN, SYN-ACK, ACK, dato. La regola funziona. Il testo e' passato attraverso ns-fw1 come previsto.
flowchart LR
classDef ext fill:#4a0d0d,stroke:#e05555,color:#eee
classDef fw fill:#0d1a3d,stroke:#4a9eff,color:#eee
classDef fwblock fill:#3d0d0d,stroke:#ff4444,color:#eee
classDef dmz fill:#3d2a0d,stroke:#ffaa4a,color:#eee
classDef lan fill:#0d2d15,stroke:#4aff7e,color:#eee
classDef drop fill:#1a1a1a,stroke:#555,color:#888
KALI["Kali"]:::ext
FW1["ns-fw1
ACL: TCP 80 in
ESTABLISHED out"]:::fw
SOFIA["ns-sofia
nc listener :80"]:::dmz
FW2["ns-fw2
FORWARD DROP
nessuna ACL"]:::fwblock
GIULIA[("ns-giulia")]:::lan
DROP1["✗ DROP
porta non in ACL"]:::drop
DROP2["✗ DROP
FW2 no ACL"]:::drop
KALI -->|"TCP 80 ✓
hello world"| FW1 -->|"PASS"| SOFIA
SOFIA -->|"ESTABLISHED ✓
ritorno"| FW1 -->|"PASS"| KALI
KALI -. "TCP 443, 22..." .-> DROP1
SOFIA -. "verso Giulia" .-> FW2 -. " " .-> DROP2
iptables ACL su ns-fw2 - MySQL verso ns-giulia#
Cisco: cisco-packet-tracer-dmz#ACL su FW2 - MySQL verso Giulia/MySQL|FW2 ACL —
access-list DMZ_IN permit tcp host 10.10.10.2 host 10.30.30.2 eq 3306. La stessa logica: la sorgente e' un IP specifico, nonany. Solo ns-sofia puo' aprire connessioni verso il database.
| Stato attuale | Obiettivo | Come | |
|---|---|---|---|
| Kali → Giulia :3306 | ✗ DROP a FW1 | ✗ rimane bloccato | nessuna regola su FW1 verso LAN |
| Sofia → Giulia :3306 | ✗ DROP a FW2 (no ACL) | ✓ PASS | ACCEPT tcp:3306 src 10.10.10.2 su FW2 |
| Sofia → Giulia :altra porta | ✗ DROP a FW2 | ✗ rimane bloccato | nessuna regola su FW2 |
# Sofia → Giulia: bloccato a FW2 con ICMP Redirect da FW1
sudo ip netns exec ns-sofia ping -c3 10.30.30.2
# From 10.10.10.1: icmp_seq=1 Redirect Host(New nexthop: 10.10.10.3)
# From 10.10.10.1: icmp_seq=2 Redirect Host(New nexthop: 10.10.10.3)
# From 10.10.10.1: icmp_seq=3 Redirect Host(New nexthop: 10.10.10.3)
# 3 packets transmitted, 0 received, 100% packet loss
# Kali → Giulia: bloccato a FW1 (nessuna ACL verso LAN)
ping -c3 10.30.30.2
# 3 packets transmitted, 0 received, 100% packet lossFW2 ha policy DROP. ns-sofia non puo' raggiungere ns-giulia. Apriamo solo MySQL (3306) e solo dall'IP specifico del web server — non da qualsiasi host della DMZ.
# apri TCP porta 3306 solo da ns-sofia (10.10.10.2) verso ns-giulia (10.30.30.2).
# -s 10.10.10.2: solo il web server puo' aprire connessioni al database.
# se un attaccante compromette un altro host in DMZ, il suo IP non matcha
# questa regola e viene droppato — lateral movement bloccato a livello L3/L4.
#
# -i veth-fw2-dmz -o veth-fw2-lan: il traffico entra dal lato DMZ ed esce
# verso la LAN. Se arrivasse da un'altra interfaccia la regola non matcha.
sudo ip netns exec ns-fw2 iptables -A FORWARD \
-i veth-fw2-dmz -o veth-fw2-lan \
-p tcp --dport 3306 \
-s 10.10.10.2 -d 10.30.30.2 \
-j ACCEPT
# traffico di ritorno: risposte MySQL da ns-giulia verso ns-sofia.
# senza questa regola il SYN-ACK verrebbe droppato — la connessione non si apre.
# ESTABLISHED,RELATED: solo risposte a connessioni gia' aperte da Sofia.
# ns-giulia non puo' avviare connessioni spontanee verso la DMZ.
sudo ip netns exec ns-fw2 iptables -A FORWARD \
-i veth-fw2-lan -o veth-fw2-dmz \
-m state --state ESTABLISHED,RELATED -j ACCEPTVerifica regole — pkts deve essere 0, nessun traffico e' ancora passato:
sudo ip netns exec ns-fw2 iptables -L FORWARD -v -n
# Chain FORWARD (policy DROP 3 packets, 252 bytes)
# pkts bytes target prot opt in out
# 0 0 ACCEPT 6 -- veth-fw2-dmz veth-fw2-lan 10.10.10.2 10.30.30.2 tcp dpt:3306
# 0 0 ACCEPT 0 -- veth-fw2-lan veth-fw2-dmz 0.0.0.0/0 0.0.0.0/0 state RELATED,ESTABLISHEDProblema: il routing di Sofia non passa per FW2
Prima di testare, controllo dove Sofia manda effettivamente il traffico verso 10.30.30.2:
# ip route get mostra il next-hop esatto che il kernel userebbe per raggiungere l'IP
sudo ip netns exec ns-sofia ip route get 10.30.30.2
# 10.30.30.2 via 10.10.10.1 dev veth-sofia src 10.10.10.2 uid 0
# cacheIl next-hop e' 10.10.10.1 — ns-fw1. Questo e' il default gateway di Sofia, e ogni traffico
verso subnet sconosciute ci passa. ns-fw1 riceve il pacchetto, non ha nessuna regola per
Sofia→LAN, FORWARD DROP: il pacchetto sparisce. ns-fw2 non lo vede mai — i contatori rimangono a 0.
Su Cisco il problema non esiste perche' Sofia e' sulla DMZ e il default gateway del PC e' FW2. Qui la topologia e' diversa: Sofia ha solo FW1 come gateway. Va aggiunta una rotta statica per dire a Sofia di raggiungere la LAN passando direttamente per FW2:
# rotta statica: il traffico verso la LAN (10.30.30.0/30) passa per ns-fw2 (10.10.10.3),
# non per il default gateway ns-fw1 (10.10.10.1).
# senza questa rotta il SYN arriva a FW1 che lo droppa — FW2 non vede niente.
sudo ip netns exec ns-sofia ip route add 10.30.30.0/30 via 10.10.10.3Verifica che ora il next-hop sia corretto:
sudo ip netns exec ns-sofia ip route get 10.30.30.2
# 10.30.30.2 via 10.10.10.3 dev veth-sofia src 10.10.10.2 uid 0
# cacheTest — netcat su 3306:
# Ubuntu - terminale 1: simula MySQL in ascolto su ns-giulia
sudo ip netns exec ns-giulia nc -l -p 3306
# Ubuntu - terminale 2: connessione da ns-sofia (il web server)
# bash -c serve per eseguire la pipe dentro il namespace corretto
sudo ip netns exec ns-sofia bash -c "echo 'SELECT * FROM lezioni' | nc 10.30.30.2 3306"Su ns-giulia compare:
SELECT * FROM lezioniContatori dopo il test — pkts in crescita su entrambe le regole:
sudo ip netns exec ns-fw2 iptables -L FORWARD -v -n
# Chain FORWARD (policy DROP 3 packets, 252 bytes)
# pkts bytes target prot opt in out
# 4 228 ACCEPT 6 -- veth-fw2-dmz veth-fw2-lan 10.10.10.2 10.30.30.2 tcp dpt:3306
# 4 216 ACCEPT 0 -- veth-fw2-lan veth-fw2-dmz 0.0.0.0/0 0.0.0.0/0 state RELATED,ESTABLISHED
# 4 pacchetti in entrambe le direzioni: SYN, SYN-ACK, dati, FINTest negativo — Kali non raggiunge il database:
# da Kali VM: nessuna rotta verso la LAN, FW1 blocca tutto
nc -w3 10.30.30.2 3306
# (UNKNOWN) [10.30.30.2] 3306 (mysql) : Connection timed outflowchart LR
KALI["🖥 Kali
192.168.64.200"]:::ext
FW1["🛡 ns-fw1
ACL: tcp :80 ✓
ACL: tcp :3306 ✗
ACL: ESTABLISHED ✓"]:::fw
SOFIA["🌐 ns-sofia
10.10.10.2"]:::dmz
FW2["🛡 ns-fw2
ACL: tcp :3306 ✓
solo src 10.10.10.2
ACL: ESTABLISHED ✓"]:::fw
GIULIA[("🗄 ns-giulia
10.30.30.2")]:::lan
KALI -- "tcp :80" --> FW1
FW1 -- "✓" --> SOFIA
SOFIA -- "tcp :3306" --> FW2
FW2 -- "✓" --> GIULIA
KALI -. "tcp :3306 ✗" .-> FW1
classDef ext fill:#4a1942,color:#fff,stroke:#c084fc
classDef fw fill:#1e3a5f,color:#fff,stroke:#60a5fa
classDef dmz fill:#1a3a2a,color:#fff,stroke:#4ade80
classDef lan fill:#3a2a1a,color:#fff,stroke:#fb923c
Sofia non parla mai direttamente con Giulia — il traffico attraversa sempre ns-fw2. ns-fw2 e' il confine tra le due zone: controlla porta, sorgente, e direzione. Kali non raggiungera' mai ns-giulia direttamente — FW1 non ha nessuna regola che permette il transito verso la LAN.
Porta 443 su ns-fw1#
mindmap
root((Porta 443 su ns-fw1))
Stato prima
80 aperta
443 DROP
Regola aggiunta
ACCEPT tcp 443 in entrata
ESTABLISHED gia copre il ritorno
Verifica
nc listener su ns-sofia 443
Testo arriva da Kali
Stato finale ns-fw1
tcp 80 ACCEPT
tcp 443 ACCEPT
ESTABLISHED RELATED ACCEPT
| Stato attuale | Obiettivo | Come | |
|---|---|---|---|
| Kali → Sofia :80 | ✓ PASS | ✓ PASS | gia' aperta |
| Kali → Sofia :443 | ✗ DROP | ✓ PASS | ACCEPT tcp:443 su FW1 |
La porta 80 e' aperta, la 443 no. Aggiungiamo HTTPS — stesso pattern della 80:
# aggiungi TCP 443 (HTTPS) alla chain FORWARD di ns-fw1.
# la regola ESTABLISHED,RELATED gia' configurata copre il traffico di ritorno
# per entrambe le porte — non serve una seconda regola.
sudo ip netns exec ns-fw1 iptables -A FORWARD \
-i veth-fw1-out -o veth-fw1-dmz \
-p tcp --dport 443 -j ACCEPTVerifica — ns-fw1 ha ora tre regole:
sudo ip netns exec ns-fw1 iptables -L FORWARD -v -n
# Chain FORWARD (policy DROP X packets, Y bytes)
# pkts bytes target prot opt in out
# 4 228 ACCEPT 6 -- veth-fw1-out veth-fw1-dmz tcp dpt:80
# 0 0 ACCEPT 6 -- veth-fw1-out veth-fw1-dmz tcp dpt:443
# 4 216 ACCEPT 0 -- veth-fw1-dmz veth-fw1-out state RELATED,ESTABLISHEDTest TCP 443 con netcat — verifica che il SYN arriva a ns-sofia prima di installare nginx con TLS:
# Ubuntu - terminale 1
sudo ip netns exec ns-sofia nc -l -p 443
# Kali - terminale 2
echo "test https" | nc 10.10.10.2 443Il testo arriva su ns-sofia. La porta 443 attraversa FW1.
Topologia completa — stato prima del WAF#
Tutte le regole iptables sono in place. Prima di passare al layer applicativo (nginx + WAF), la rete e' questa:
flowchart LR
KALI["🖥 Kali
192.168.64.200"]:::ext
UBUNTU["Ubuntu host
192.168.64.1 / 10.0.0.1"]:::host
FW1["🛡 ns-fw1
10.0.0.2 / 10.10.10.1
ACCEPT tcp:80
ACCEPT tcp:443
ACCEPT ESTABLISHED"]:::fw
BRIDGE["br-dmz
switch L2"]:::bridge
SOFIA["🌐 ns-sofia
10.10.10.2"]:::dmz
FW2["🛡 ns-fw2
10.10.10.3 / 10.30.30.1
ACCEPT tcp:3306 src .10.2
ACCEPT ESTABLISHED"]:::fw
GIULIA[("🗄 ns-giulia
10.30.30.2")]:::lan
KALI -->|"enp0s1 / veth-host"| UBUNTU
UBUNTU -->|"veth-host / veth-fw1-out"| FW1
FW1 -->|"veth-fw1-dmz / veth-fw1-dmz-br"| BRIDGE
BRIDGE -->|"veth-sofia-br / veth-sofia"| SOFIA
BRIDGE -->|"veth-fw2-dmz-br / veth-fw2-dmz"| FW2
FW2 -->|"veth-fw2-lan / veth-giulia"| GIULIA
classDef ext fill:#4a1942,color:#fff,stroke:#c084fc
classDef host fill:#2a2a2a,color:#fff,stroke:#9ca3af
classDef fw fill:#1e3a5f,color:#fff,stroke:#60a5fa
classDef bridge fill:#1a2a3a,color:#fff,stroke:#38bdf8
classDef dmz fill:#1a3a2a,color:#fff,stroke:#4ade80
classDef lan fill:#3a2a1a,color:#fff,stroke:#fb923c
Ogni label sugli edge mostra i due capi del cavo virtuale:
- l'interfaccia di chi manda
- e quella di chi riceve.
FW1 e FW2 hanno le ACL attive — tutto il resto e' DROP.
nginx in ns-sofia#
mindmap
root((nginx in ns-sofia))
Concetto
Processo gira su filesystem Ubuntu
Stack di rete e di ns-sofia
ip netns exec cambia solo la rete
Configurazione
Listen 10.10.10.2 80
PID file dedicato
Log dedicati
root var www html
Analogia Docker
Stesso meccanismo sotto il cofano
Container ha network namespace dentro
Test
curl da ns-sofia localhost
curl da Kali 10.10.10.2
Log access con IP reale Kali
nginx non viene installato "dentro" il namespace (anche perchè non esiste un file system )— viene avviato nel contesto di rete di ns-sofia usando ip netns exec. Il processo gira sul filesystem dell'host Ubuntu, ma il suo stack di rete e' quello di ns-sofia. Stesso meccanismo di Docker sotto il cofano: ogni container ha dentro di se' un network namespace Linux.
# installa nginx sul sistema Ubuntu
sudo apt install -y nginx
# ferma il nginx di sistema se e' gia' in ascolto sulla 80
sudo systemctl stop nginxPer avviarlo in ns-sofia serve una configurazione separata: IP specifico (10.10.10.2, non 0.0.0.0), pid file dedicato e log dedicati per evitare conflitti con il nginx di sistema.
sudo tee /etc/nginx/nginx-sofia.conf > /dev/null << 'EOF'
worker_processes 1;
pid /run/nginx-sofia.pid;
error_log /var/log/nginx/sofia-error.log;
events { worker_connections 128; }
http {
include /etc/nginx/mime.types;
access_log /var/log/nginx/sofia-access.log combined;
server {
listen 10.10.10.2:80;
server_name corsobitcoin.com;
root /var/www/html;
index index.html;
location / {
try_files $uri $uri/ =404;
}
}
}
EOF
# pagina di test per corsobitcoin.com
sudo tee /var/www/html/index.html > /dev/null << 'EOF'
<!DOCTYPE html>
<html>
<head><title>corsobitcoin.com</title></head>
<body>
<h1>corsobitcoin.com</h1>
<p>Lezioni: Bitcoin 101, Lightning Network, Wallets.</p>
</body>
</html>
EOF
# avvia nginx nel namespace ns-sofia
sudo ip netns exec ns-sofia nginx -c /etc/nginx/nginx-sofia.confVerifica — nginx e' in ascolto su ns-sofia:
sudo ip netns exec ns-sofia ss -tlnp | grep 80
# LISTEN 0 511 10.10.10.2:80 0.0.0.0:* users:(("nginx",...))Test da ns-sofia verso se stesso:
sudo ip netns exec ns-sofia curl -s http://10.10.10.2/
# <h1>corsobitcoin.com</h1>Test da Kali — primo HTTP reale:
curl -s http://10.10.10.2/
# <h1>corsobitcoin.com</h1>
# <p>Lezioni: Bitcoin 101, Lightning Network, Wallets.</p>Log di accesso:
sudo tail -3 /var/log/nginx/sofia-access.log
# 10.10.10.2 - - [10/Jun/2026:16:36:09 +0000] "GET / HTTP/1.1" 200 174 "-" "curl/8.5.0"
# 192.168.64.200 - - [10/Jun/2026:16:36:15 +0000] "GET / HTTP/1.1" 200 174 "-" "curl/8.18.0"La prima riga e' un curl fatto da dentro ns-sofia su se stessa — source IP e' 10.10.10.2 (Sofia stessa).
La seconda riga e' il curl da Kali: nginx vede 192.168.64.200, l'IP reale di Kali. Ubuntu fa routing, non NAT — il router cambia solo i MAC address a ogni hop, il source IP del pacchetto rimane intatto. nginx vede il client originale direttamente. NAT avrebbe rimpiazzato 192.168.64.200 con 10.0.0.1, ma qui non c'e' SNAT configurato.
Contatori ns-fw1 dopo il curl:
sudo ip netns exec ns-fw1 iptables -L FORWARD -v -n
# 6 360 ACCEPT 6 -- veth-fw1-out veth-fw1-dmz tcp dpt:80
# 0 0 ACCEPT 6 -- veth-fw1-out veth-fw1-dmz tcp dpt:443
# 6 408 ACCEPT 0 -- veth-fw1-dmz veth-fw1-out state RELATED,ESTABLISHEDSYN, SYN-ACK, ACK, GET, risposta, FIN — sei pacchetti, tre per direzione.
WAF - ModSecurity su nginx#
mindmap
root((WAF ModSecurity))
Differenza da iptables
FW1 vede L3 L4 chi parla con chi
WAF vede L7 cosa dicono
Ortogonali e indipendenti
OWASP CRS
Regole 910-944 rilevano aggiungono score
Regola 949110 giudice finale
Anomaly scoring meno falsi positivi
Attacchi bloccati
SQL Injection score 8
XSS score 23
Soglia default 5
Installazione
libnginx-mod-http-modsecurity
coreruleset da GitHub
main.conf SecRuleEngine On
FW1 vede TCP sulla porta 80 — sa che la connessione e' verso ns-sofia, non sa cosa contiene. ModSecurity legge la request HTTP e blocca pattern noti di attacco: SQL injection, XSS, path traversal.
FW1 vede: TCP 192.168.64.200:54321 → 10.10.10.2:80 [PERMIT]
WAF vede: GET /login?id=' OR 1=1-- HTTP/1.1 [BLOCK — SQL injection]Il firewall controlla chi parla con chi (L3/L4). Il WAF controlla cosa dicono (L7). Sono due difese complementari — togliere una non cambia niente all'altra.
Installazione#
mindmap
root((Installazione ModSecurity))
Pacchetti
libnginx-mod-http-modsecurity
coreruleset da GitHub
File di configurazione
crs-setup.conf copiato da example
main.conf con SecRuleEngine On
Errore comune
Non includere modsecurity.conf base
Causa Phase 1 was informed already
# modulo ModSecurity per nginx
sudo apt install -y libnginx-mod-http-modsecurity
# regole OWASP CRS — il set standard di regole ModSecurity
sudo git clone --depth 1 https://github.com/coreruleset/coreruleset \
/etc/nginx/modsecurity/crs
sudo cp /etc/nginx/modsecurity/crs/crs-setup.conf.example \
/etc/nginx/modsecurity/crs/crs-setup.conf
# configurazione ModSecurity: abilita il motore + carica le regole CRS.
# NON includere modsecurity.conf base: definisce SecDefaultAction gia' presente
# in crs-setup.conf — il doppio Include causa errore "Phase 1 was informed already".
sudo tee /etc/nginx/modsecurity/main.conf > /dev/null << 'EOF'
SecRuleEngine On
Include /etc/nginx/modsecurity/crs/crs-setup.conf
Include /etc/nginx/modsecurity/crs/rules/*.conf
EOFnginx + ModSecurity#
mindmap
root((nginx con ModSecurity))
Modifiche alla config
load_module ngx http modsecurity
modsecurity on nel server block
modsecurity rules file main.conf
Riavvio
pkill nginx sofia pid
ip netns exec ns-sofia nginx -c
Aggiorna la configurazione di ns-sofia per attivare il WAF:
# aggiorna nginx-sofia.conf aggiungendo modsecurity on + modsecurity_rules_file.
# load_module va in cima al file — necessario quando nginx gira con -c custom config
# perche' /etc/nginx/modules-enabled/ non viene caricato automaticamente.
sudo tee /etc/nginx/nginx-sofia.conf > /dev/null << 'EOF'
load_module modules/ngx_http_modsecurity_module.so;
worker_processes 1;
pid /run/nginx-sofia.pid;
error_log /var/log/nginx/sofia-error.log;
events { worker_connections 128; }
http {
include /etc/nginx/mime.types;
access_log /var/log/nginx/sofia-access.log combined;
server {
listen 10.10.10.2:80;
server_name corsobitcoin.com;
root /var/www/html;
index index.html;
modsecurity on;
modsecurity_rules_file /etc/nginx/modsecurity/main.conf;
location / {
try_files $uri $uri/ =404;
}
}
}
EOF
# riavvia nginx con la nuova configurazione
sudo pkill -F /run/nginx-sofia.pid 2>/dev/null; sleep 1
sudo ip netns exec ns-sofia nginx -c /etc/nginx/nginx-sofia.confTest WAF — attacchi reali#
mindmap
root((Test WAF attacchi reali))
SQL Injection
id OR 1 1 URL encoded
Risposta 403 Forbidden
Score 8 sopra soglia 5
XSS
script alert 1 script URL encoded
Risposta 403 Forbidden
Score 23 sopra soglia 5
Richiesta legittima
GET slash
200 OK nessun blocco
Score 0
SQL injection:
# da Kali VM
curl -s "http://10.10.10.2/?id=%27%20OR%201%3D1--"Risposta:
<html><head><title>403 Forbidden</title></head>
<body><h1>403 Forbidden</h1></body></html>ModSecurity ha riconosciuto il pattern ' OR 1=1-- come SQL injection e ha restituito 403 prima che la request raggiungesse nginx.
XSS:
curl -s "http://10.10.10.2/?q=%3Cscript%3Ealert(1)%3C%2Fscript%3E"
# <html><head><title>403 Forbidden</title></head>...Richiesta legittima — non bloccata:
curl -s "http://10.10.10.2/"
# <h1>corsobitcoin.com</h1> <- 200 OK, nessun bloccoLog ModSecurity — SQL injection e XSS:
sudo grep "ModSecurity" /var/log/nginx/sofia-error.log | tail -5
# [error] *1 [client 192.168.64.200] ModSecurity: Access denied with code 403 (phase 2).
# Matched "Operator `Ge' with parameter `5' against variable `TX:BLOCKING_INBOUND_ANOMALY_SCORE' (Value: `8')
# [id "949110"] [msg "Inbound Anomaly Score Exceeded (Total Score: 8)"]
# [uri "/?id=%27%20OR%201%3D1--"] ...
#
# [error] *2 [client 192.168.64.200] ModSecurity: Access denied with code 403 (phase 2).
# Matched "Operator `Ge' with parameter `5' against variable `TX:BLOCKING_INBOUND_ANOMALY_SCORE' (Value: `23')
# [id "949110"] [msg "Inbound Anomaly Score Exceeded (Total Score: 23)"]
# [uri "/?q=%3Cscript%3Ealert(1)%3C%2Fscript%3E"] ...CRS v4 non blocca regola per regola — usa anomaly scoring. Ogni regola che matcha aggiunge punti a TX:BLOCKING_INBOUND_ANOMALY_SCORE. Quando il totale supera la soglia (default: 5), la regola 949110 blocca la request in phase 2.
SQL injection ha totalizzato 8, XSS 23 — entrambi sopra soglia. Una request normale totalizza 0.
Il vantaggio del modello a punteggio: un singolo header sospetto non basta a bloccare — serve una combinazione. Meno falsi positivi rispetto al blocco per singola regola. Il client: 192.168.64.200 nei log conferma che nginx vede ancora l'IP reale di Kali.
Il log contiene tutto quello che serve per l'analisi: regola che ha bloccato (949110), score totale, URI, IP sorgente, ID univoco della request. In un SOC reale questo log va a un SIEM — e' la firma dell'attacco, tracciabile e correlabile con altri eventi.
Wazuh - gli alert ModSecurity nel SIEM#
Un WAF che blocca e logga ma non manda niente a un SIEM e' un sistema cieco: l'attacco viene fermato, ma nessuno lo sa. Wazuh raccoglie i log di ModSecurity, li decodifica, li correla con MITRE ATT&CK e genera alert con severity. In un Blue Team reale questa e' la differenza tra un sistema che blocca in silenzio e uno che allerta il SOC.
Configurazione — localfile in ossec.conf#
mindmap
root((Configurazione localfile))
Componente
wazuh-logcollector
Blocco localfile in ossec.conf
Parametri
log format syslog
location sofia-error.log
Riavvio
systemctl restart wazuh-agent
Decoder
nginx-errorlog built-in
Estrae srcip id msg uri
Wazuh agent monitora file di log tramite il componente wazuh-logcollector. Basta aggiungere un blocco <localfile> a /var/ossec/etc/ossec.conf:
sudo sed -i 's|</ossec_config>| <localfile>\n <log_format>syslog</log_format>\n <location>/var/log/nginx/sofia-error.log</location>\n </localfile>\n\n</ossec_config>|' /var/ossec/etc/ossec.conf
sudo systemctl restart wazuh-agentlog_format syslog dice al logcollector come parsare il file. Wazuh ha un decoder specifico nginx-errorlog che riconosce il formato del nginx error log e lo smonta nei campi strutturati.
Il flusso nginx → Wazuh#
flowchart LR
KALI["🖥 Kali
192.168.64.200"]:::ext
SOFIA["🌐 ns-sofia
nginx + ModSecurity"]:::dmz
LOG["📄 sofia-error.log
/var/log/nginx/"]:::host
LC["wazuh-logcollector
legge il file"]:::host
MGR["🔍 Wazuh Manager
decoder + rules engine"]:::siem
DASH["📊 Dashboard
alert + MITRE"]:::siem
KALI -->|"GET /?id=' OR 1=1--"| SOFIA
SOFIA -->|"403 + log entry"| LOG
LOG -->|"tail -f inotify"| LC
LC -->|"TLS — evento raw"| MGR
MGR -->|"rule 31333 fired"| DASH
classDef ext fill:#4a1942,color:#fff,stroke:#c084fc
classDef dmz fill:#1a3a2a,color:#fff,stroke:#4ade80
classDef host fill:#2a2a2a,color:#fff,stroke:#9ca3af
classDef siem fill:#1e3a5f,color:#fff,stroke:#60a5fa
Wazuh logcollector usa inotify — non fa polling: viene notificato dal kernel ogni volta che il file cresce. La latenza tra il blocco ModSecurity e l'alert in dashboard e' di pochi secondi.
L'alert in dettaglio#
mindmap
root((Alert in dettaglio))
Campi chiave
rule id 31333 regola Wazuh nginx
rule level 7 Bad word match
decoder nginx-errorlog
data srcip 192.168.64.200
MITRE mapping
T1083 File and Directory Discovery
Tattica Discovery
Automatico da Wazuh
Soglie
Livello 7 significativo non critico
Sopra 10 email e alert critico
input.type: log
agent.name: HIDS-Barno
agent.id: 003
manager.name: wazuh.manager
data.srcip: 192.168.64.200
rule.id: 31333
rule.level: 7
rule.description: ModSecurity rejected a query
rule.groups: nginx, web, modsecurity
rule.mitre.id: T1083
rule.mitre.tactic: Discovery
decoder.name: nginx-errorlog
location: /var/log/nginx/sofia-error.logOgni campo ha un significato preciso:
rule.id: 31333 — e' la regola Wazuh (non CRS) che matcha gli eventi ModSecurity nei log nginx. Wazuh ha regole proprie per nginx/ModSecurity nel file 0260-nginx_rules.xml. La regola 31333 matcha specificamente gli Access denied di ModSecurity.
rule.level: 7 — scala 0-15 di Wazuh. Livello 7 = "Bad word match". Sopra 10 scatta email/alert critico. 7 e' significativo ma non critico — giusto per un attacco rilevato e bloccato.
decoder.name: nginx-errorlog — Wazuh ha un decoder built-in che riconosce il formato del nginx error log e estrae i campi: srcip, id, msg, uri. Senza decoder il log sarebbe una stringa opaca.
rule.mitre.id: T1083 / rule.mitre.tactic: Discovery — Wazuh mappa automaticamente gli alert su MITRE ATT&CK. T1083 e' "File and Directory Discovery" — la regola Wazuh associa i tentativi di SQL injection/path traversal a questa tattica perche' l'attaccante potrebbe star cercando di enumerare la struttura dell'applicazione.
Perche' si chiama 949110#
mindmap
root((949110 CRS))
File CRS per categoria
910 IP Reputation
941 XSS aggiunge score
942 SQL Injection aggiunge score
949 Blocking Evaluation
Logica
Regole 910-944 rilevano solo
Regola 949110 giudice finale
Legge TX BLOCKING INBOUND ANOMALY SCORE
Esempio SQL injection
942100 libinjection +5
942190 keyword OR +3
Score totale 8 soglia 5
949110 ACCESS DENIED 403
Il numero 949110 viene dal sistema di numerazione del CRS, non di Wazuh. Le regole CRS sono organizzate in file con un prefisso numerico:
REQUEST-900-EXCLUSION-RULES-BEFORE-CRS.conf — esclusioni
REQUEST-910-IP-REPUTATION.conf — blocklist IP
REQUEST-913-SCANNER-DETECTION.conf — scanner, crawler
REQUEST-920-PROTOCOL-ENFORCEMENT.conf — violazioni HTTP
REQUEST-930-APPLICATION-ATTACK-LFI.conf — Local File Inclusion
REQUEST-932-APPLICATION-ATTACK-RCE.conf — Remote Code Execution
REQUEST-941-APPLICATION-ATTACK-XSS.conf — XSS (aggiunge score)
REQUEST-942-APPLICATION-ATTACK-SQLI.conf — SQL injection (aggiunge score)
REQUEST-949-BLOCKING-EVALUATION.conf — il "giudice"Le regole 910-944 rilevano gli attacchi e aggiungono punti a TX:BLOCKING_INBOUND_ANOMALY_SCORE. Non bloccano da sole.
La regola 949110 e' il giudice finale — in phase 2 legge il punteggio accumulato e se supera la soglia (default: 5) blocca con 403. Il nome del file REQUEST-949-BLOCKING-EVALUATION lo dice esplicitamente: e' la fase di valutazione del blocco, non la fase di rilevamento.
Questo e' il motivo per cui nel log vedi sempre 949110 come regola bloccante — indipendentemente da cosa ha triggerato l'attacco (SQL injection, XSS, RCE). Le regole specifiche lavorano in silenzio accumulando score; 949110 e' l'unica che genera l'Access denied.
Kali manda: GET /?id=' OR 1=1--
CRS phase 1/2:
942100 SQL injection via libinjection → +5 score
942190 SQL injection keyword OR → +3 score
-----------------------------------------------
TX:BLOCKING_INBOUND_ANOMALY_SCORE = 8
CRS phase 2:
949110 score 8 >= soglia 5 → ACCESS DENIED 403ossec.log vs nginx error log#
mindmap
root((ossec.log vs nginx error log))
sofia-error.log
Scritto da nginx e ModSecurity
Contiene eventi applicativi
Blocchi WAF errori HTTP
ossec.log
Scritto da wazuh-agent
Log operativo avvii errori config
Non contiene eventi raccolti
Dove vanno gli eventi
Via TLS al Wazuh Manager
Appaiono solo in dashboard
Una distinzione importante da tenere in mente:
| File | Chi scrive | Cosa contiene |
|---|---|---|
/var/log/nginx/sofia-error.log | nginx/ModSecurity | eventi applicativi — blocchi WAF, errori HTTP |
/var/ossec/logs/ossec.log | wazuh-agent | log operativo dell'agent — avvii, errori di config, stato |
ossec.log non contiene gli eventi raccolti. Gli eventi viaggiano via TLS al manager e appaiono solo nella dashboard. Se cerchi ModSecurity in ossec.log non trovi niente — non e' un bug, e' by design.
Test end-to-end#
mindmap
root((Test end-to-end))
Percorso positivo
Kali ping ns-fw1 TTL 63
Kali curl nginx 200 OK
Sofia nc MySQL SELECT passato
Cosa Kali NON puo fare
nc 10.30.30.2 3306 timeout
nc 10.10.10.2 22 timeout
SQL injection 403 dal WAF
Contatori iptables
ns-fw1 porta 80 hitcnt crescente
ns-fw2 porta 3306 hitcnt crescente
ESTABLISHED speculare
Il percorso completo: Kali → nginx con WAF → MySQL simulato.
# Step 1 — Kali → FW1: raggiungibilita' base
ping -c3 10.0.0.2
# 64 bytes from 10.0.0.2: ttl=63 ✓ (Ubuntu ha fatto un hop L3)
# Step 2 — Kali → Sofia/nginx: HTTP attraverso FW1
curl -s http://10.10.10.2/
# <h1>corsobitcoin.com</h1> ✓
# Step 3 — Sofia → Giulia: MySQL attraverso FW2
# apri listener MySQL simulato su ns-giulia
sudo ip netns exec ns-giulia nc -l -p 3306 &
# connettiti da ns-sofia
sudo ip netns exec ns-sofia bash -c "echo 'SELECT * FROM corsi' | nc 10.30.30.2 3306"
# SELECT * FROM corsi (compare su ns-giulia) ✓Kali (192.168.64.200)
│
│ curl http://10.10.10.2/ ✓ (ns-fw1: tcp 80 ACCEPT)
│ TTL=62 — Ubuntu + ns-fw1
▼
ns-sofia / nginx + WAF (10.10.10.2)
│
│ nc 10.30.30.2 3306 ✓ (ns-fw2: tcp 3306 da 10.10.10.2 ACCEPT)
▼
ns-giulia / MySQL simulato (10.30.30.2)Cosa Kali NON puo' fare:
# raggiungere il database direttamente
nc -w3 10.30.30.2 3306
# timeout — FW1 blocca, nessuna rotta nella catena
# SSH su ns-sofia
nc -w3 10.10.10.2 22
# timeout — FW1 non ha una regola per la 22
# SQL injection attraverso il WAF
curl "http://10.10.10.2/?id=%27%20OR%201%3D1--"
# 403 Forbidden — ModSecurity interviene prima di nginxContatori finali — prova che il traffico ha attraversato le regole corrette:
sudo ip netns exec ns-fw1 iptables -L FORWARD -v -n
# porta 80: hitcnt in crescita per ogni curl
# porta 443: 0 se non abbiamo fatto richieste HTTPS
# ESTABLISHED,RELATED: speculare al traffico in entrata
sudo ip netns exec ns-fw2 iptables -L FORWARD -v -n
# tcp dpt:3306: hitcnt per le connessioni nc di test
# ESTABLISHED,RELATED: le risposte MySQLCosa ho imparato#
mindmap
root((Cosa ho imparato))
Namespace
Isolano rete non il processo
ip netns exec non e un container
Docker usa namespace piu cgroups
iptables vs Cisco ASA
iptables simmetrico tutto bloccato
ASA asimmetrico inside raggiunge fuori
Zero comportamento implicito
ESTABLISHED RELATED
Stateful inspection in iptables
Va aggiunto esplicitamente
Senza il SYN ACK viene droppato
Ambiente ospite complica il lab
Docker ufw occupano FORWARD chain
In Ubuntu pulito non esiste problema
WAF ortogonale a firewall
FW controlla L3 L4
WAF controlla L7
Due layer indipendenti
Script e la topologia salvata
Equivalente del pkt di Packet Tracer
Infrastructure as code da qui parte
I namespace Linux isolano la rete, non il processo. nginx gira sul filesystem di Ubuntu ma vede solo le interfacce di ns-sofia. ip netns exec non e' un container — e' solo un cambio di stack di rete. Docker usa namespace + cgroups + union filesystem insieme: e' lo stesso mattone di base, assemblato in modo piu' completo.
iptables e' simmetrico, il security-level ASA non lo e'. Su Cisco, inside (100) raggiunge la DMZ senza ACL perche' scende di livello. Con FORWARD DROP, ns-giulia non raggiunge ns-sofia e viceversa finche' non c'e' una regola esplicita per ogni direzione. Piu' verboso, zero comportamento implicito da ricordare.
ESTABLISHED,RELATED e' il stateful inspection. L'ASA traccia le connessioni automaticamente. iptables lo fa con il modulo state — va aggiunto esplicitamente. Senza quella regola ogni risposta del server verrebbe droppata: il SYN passa, il SYN-ACK no.
L'ambiente ospite complica il lab. Docker e ufw occupano la FORWARD chain dell'host con policy DROP prima che la configuriamo. In un Ubuntu pulito questo problema non esiste. Ma in produzione e' sempre cosi': piu' servizi significano piu' regole iptables, spesso in conflitto. Capire chi ha aggiunto quale regola richiede di leggere le chain nell'ordine in cui vengono processate — non basta guardare iptables -L.
Il WAF e' orthogonale al firewall. FW1 non sa che il payload contiene ' OR 1=1--. Lo sa solo il WAF perche' opera a L7, dopo che il firewall ha gia' deciso di lasciare passare la connessione. Togliere il WAF non cambia niente alle regole iptables — e viceversa. Sono due layer indipendenti che si sommano.
Lo script e' il lab. In Packet Tracer salvi il .pkt e riapri tutto. Qui setup-dmz.sh e' la versione salvata della topologia — la stessa idea del file .pkt, ma testuale e modificabile. L'infrastruttura come codice parte esattamente da qui: una topologia di rete descritta come codice, riproducibile con un comando.
I namespace sono volatili - lo script#
mindmap
root((Namespace volatili e script))
Problema
Namespace vivono in memoria
Spegni VM sparisce tutto
Soluzione
wip.sh su Ubuntu 8 step interattivi
wip kali.sh su Kali 3 rotte
Cosa ricrea wip.sh
Namespace e veth pair
IP e rotte
ip forward
Fix FORWARD chain host
iptables DROP e ACL
Cosa non e' nello script
nginx e ModSecurity
Pacchetti e configurazioni
Solo topologia L3 L4
A differenza di Packet Tracer che salva il file .pkt, i namespace Linux vivono in memoria. Spegni la VM, sparisce tutto.
La soluzione sono due script bash che replicano tutto quello che abbiamo fatto nel lab:
wip.sh — da eseguire su Ubuntu come sudo bash wip.sh. Ricrea in 8 step interattivi:
- Namespace (ns-fw1, ns-sofia, ns-fw2, ns-giulia)
- Veth pair e bridge DMZ
- Indirizzi IP + rotta statica Sofia→LAN via ns-fw2
- Rotte Ubuntu host verso DMZ e LAN
- ip_forward su host, ns-fw1, ns-fw2
- Fix FORWARD chain host (Docker/ufw)
- iptables default DROP + ACL porta 80 e 443 su ns-fw1
- iptables ACL porta 3306 su ns-fw2 (solo da ns-sofia)
Ogni step mostra i comandi prima di eseguirli e aspetta INVIO — pensato per ripassare la topologia passo per passo, non solo per l'automazione.
wip_kali.sh — da eseguire su Kali come sudo bash wip_kali.sh. Aggiunge le tre rotte necessarie per raggiungere le subnet del lab:
ip route add 10.0.0.0/30 via 192.168.64.3 # link esterno: host <-> ns-fw1
ip route add 10.10.10.0/29 via 192.168.64.3 # DMZ
ip route add 10.30.30.0/30 via 192.168.64.3 # LANCosa non e' nello script — nginx, ModSecurity e la configurazione Wazuh non sono riproducibili da zero con un bash: richiedono pacchetti installati (apt install nginx libnginx-mod-http-modsecurity), file di configurazione già presenti e il CRS clonato. Questi step vanno eseguiti manualmente seguendo le sezioni del lab. Lo script ricrea solo la topologia di rete — il layer L3/L4.
Script e file di configurazione del lab: github.com/Barno/u-random-dev