Understanding Risk Management#
mindmap
root((Understanding
Risk Management))
Vulnerability vs Threat vs Risk
Vulnerability
weakness in system
Threat
potential danger to CIA
Risk
probability times impact
Probability and Impact
two axes of risk
harm magnitude
Risk Cannot Be Eliminated
managed not removed
residual risk always remains
Threats
Malicious Human
Accidental Human
Environmental
Risk Identification
gather info
vuln scan
threat intel
Risk Types
Internal External
IP Theft
Legacy Systems
Vulnerabilities
default configurations
missing patches
no firewall
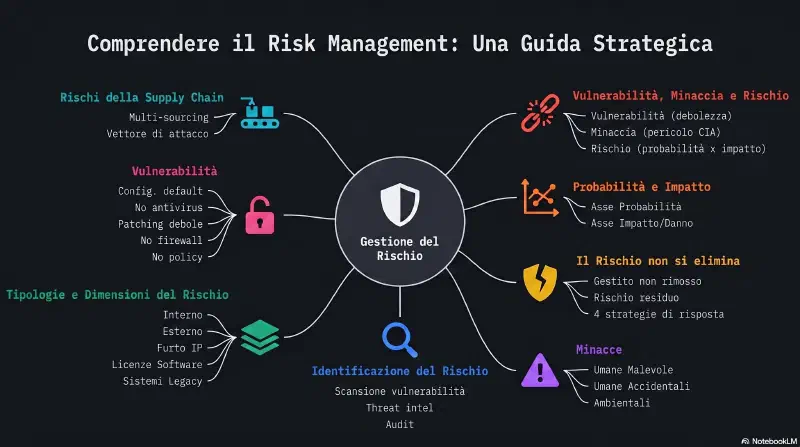
Vulnerabilità e rischio non sono sinonimi, anche se nel linguaggio comune vengono confusi:
| Termine | Cos'è | Esempio (dev) |
|---|---|---|
| Vulnerabilità | debolezza nel sistema, app o processo | libreria npm con CVE per XSS non aggiornata |
| Minaccia | pericolo potenziale che potrebbe sfruttare quella debolezza | attaccante che scansiona internet cercando quella versione vulnerabile |
| Rischio | probabilità che la minaccia sfrutti la vulnerabilità, con impatto negativo come risultato | quella libreria gira in produzione su un endpoint pubblico: la probabilità di exploit reale è alta |
La vulnerabilità esiste anche se nessuno la sta sfruttando: è una caratteristica statica del sistema. Il rischio invece dipende dal contesto: la stessa vulnerabilità in un ambiente isolato e in un ambiente esposto a internet ha un rischio molto diverso, pur essendo identica.
Probabilità e impatto: le due dimensioni del rischio#
mindmap
root((Probabilita
e Impatto))
Impact
magnitude of harm
Probability
likelihood of occurrence
Used Together
quantitative SLE ARO ALE
qualitative Low Medium High
Per valutare qualsiasi rischio si usano due criteri:
- Impatto: la magnitudo del danno (harm) che una minaccia può causare sfruttando una vulnerabilità.
- Probabilità: quanto spesso ci si aspetta che quel rischio si verifichi, se mai si verificherà.
Nota di vocabolario: harm = danno, male (sostantivo/verbo). Aggiunto al glossario, vedi harm.
Esempio: il sistema senza antivirus aggiornato#
mindmap
root((Sistema senza
Antivirus))
Vulnerability
Malware no signature
Threat
Malware written by attackers
Probability
isolated system low
internet connected high
risky downloads higher
Impact
unusable system
data loss
network wide infection
Un sistema senza antivirus aggiornato è vulnerabile al malware. Il malware scritto da attaccanti malevoli è la minaccia. La probabilità che quel malware raggiunga il sistema vulnerabile rappresenta il rischio. L'impatto dipende da cosa fa il malware: può rendere il computer inutilizzabile, causare perdita di dati o infettare tutti i computer della rete.
La probabilità di un rischio non è mai il 100%. Un sistema isolato, senza accesso a internet, senza connettività di rete e senza porte USB, ha una probabilità molto bassa di infezione da malware. La probabilità aumenta significativamente per un sistema connesso a internet, e aumenta ancora di più se l'utente visita siti rischiosi e scarica e installa file non verificati.
Stesso ragionamento di un dependency scan: npm audit segnala una vulnerabilità nota, ma il rischio reale dipende da quanto quel codice è effettivamente raggiungibile e da quanto è probabile che venga invocato con input controllato dall'attaccante.
Il rischio non si può eliminare#
mindmap
root((Il Rischio
non si Elimina))
Daily Life Analogy
driving and walking
mitigated with caution
Security Controls
mitigate risk levels
Avoidance Misconception
stops the activity
residual risk still nonzero
4 Risk Response Strategies
Mitigate Transfer
Accept Avoid
Punto centrale: il rischio non si può eliminare.
La gestione del rischio è qualcosa che si pratica ogni giorno, anche fuori dall'IT. Guidare o camminare per strada è un'attività potenzialmente molto pericolosa: le auto sfrecciano avanti e indietro e rappresentano un rischio significativo per chiunque sia sulla strada. Eppure si mitigano questi rischi con prudenza e attenzione.
Lo stesso vale per computer e reti: un'organizzazione mitiga i rischi usando diversi tipi di security control.
In cap-01 le 4 Risk Response Strategies (Mitigate, Transfer, Accept, Avoid) sembrano offrire una via per eliminare il rischio con Avoid. In realtà anche Avoid non elimina il rischio in assoluto: elimina l'attività specifica che lo generava. Il rischio residuo di operare, qualsiasi attività, qualsiasi sistema connesso, resta sempre diverso da zero: vedi Risk Concepts.
Threats#
mindmap
root((Threats))
Malicious Human
Unskilled Attacker
Organized Crime
APT nation state
Accidental Human
user error
admin misconfiguration
Environmental
blackout
chemical spill
pollution
natural events
hurricane earthquake
Threat Assessment
identify and prioritize
same as threat modeling
STRIDE attack tree
Una minaccia è un pericolo potenziale. Nel contesto della gestione del rischio, una minaccia è qualsiasi circostanza o evento che può compromettere confidentiality, integrity o availability (CIA) di dati o sistemi.
Le minacce si presentano in tre forme principali:
| Categoria | Definizione | Esempio |
|---|---|---|
| Minacce umane intenzionali (malicious human threats) | threat actor che agiscono deliberatamente: dall'Unskilled Attacker all'Organized Crime fino alle APT (Advanced Persistent Threat) sponsorizzate da governi | attacchi di rete, attacchi ai sistemi, rilascio di malware |
| Minacce umane accidentali (accidental human threats) | utenti o amministratori che causano danni senza intenzione | un utente cancella o corrompe dati per errore, o accede a dati a cui non dovrebbe; un admin cambia una configurazione per risolvere un problema e involontariamente ne causa un altro |
| Minacce ambientali (environmental threats) | eventi fisici/ambientali, non umani | un blackout prolungato può portare a sversamenti chimici (chemical spill) e inquinamento (pollution); eventi naturali come uragani, alluvioni, tornado, terremoti, frane, tempeste elettriche |
Per i threat actor intenzionali (sofisticazione, motivazioni: APT vs Organized Crime vs Hacktivist vs Unskilled Attacker) vedi Threat Actors. Per gli insider accidentali vedi Insider Threat.
Nota di vocabolario: pollution = inquinamento, contaminazione. Aggiunto al glossario, vedi pollution.
Threat assessment (valutazione della minaccia): aiuta un'organizzazione a identificare e categorizzare le minacce. Cerca di prevedere quali minacce potrebbero colpire gli asset dell'organizzazione, insieme alla probabilità che si verifichino e al potenziale impatto. Una volta identificate e prioritizzate le minacce, l'organizzazione individua i security control da applicare contro le più gravi.
E' lo stesso esercizio del threat modeling che si fa in fase di design di un'applicazione (es. STRIDE, attack tree): si elencano le minacce plausibili per quel sistema specifico, si stima quanto sono probabili e quanto costerebbero se si verificassero, e solo dopo si decide dove investire in controlli. Il threat assessment a livello organizzativo applica lo stesso ragionamento probabilità x impatto visto sopra, ma sull'intera organizzazione invece che su una singola feature.
Risk Identification#
mindmap
root((Risk
Identification))
Goal
list all possible risks
Information Sources
Application Security Testing
Threat Intelligence
Further Techniques
Vulnerability Scanning
Penetration Testing
Responsible Disclosure
System and Process Audits
Quando i professionisti della sicurezza iniziano il processo di gestione del rischio, conducono un esercizio chiamato risk identification: raccolgono informazioni da molte fonti diverse e cercano di elencare tutti i possibili rischi che potrebbero riguardare l'organizzazione.
Alcuni strumenti per identificare i rischi sono già stati visti: application security testing (vedi Analyzing and Reviewing Code) e threat intelligence (vedi Threat Intelligence Sources). Più avanti in questo capitolo vedremo altre tecniche: vulnerability scanning, penetration test, responsible disclosure program e audit di sistemi e processi (vedi #Vulnerability Scanning, #Penetration Testing, #Responsible Disclosure Programs, #System and Process Audits). Tutte queste informazioni alimentano il processo di gestione del rischio.
Risk Types#
mindmap
root((Risk
Types))
Internal
employees and internal IT
External
attackers
natural disasters
Intellectual Property Theft
copyright patents
trademarks trade secrets
Software Compliance
unlicensed use
Lard Lad license example
Legacy Systems
vendor no longer supports
no patches forever
Ci sono diversi tipi (o categorie) di rischio:
- Internal: rischi che provengono dall'interno dell'organizzazione, inclusi i dipendenti e tutto l'hardware/software usato internamente. Generalmente predicibili, mitigabili con security control standard.
- External: rischi che provengono dall'esterno, inclusi gli attaccanti esterni e le minacce naturali (uragani, terremoti, tornado). Alcuni sono predicibili, molti no: gli attaccanti modificano costantemente i metodi per eludere i controlli esistenti.
- Intellectual property theft: la proprietà intellettuale (IP) include copyright, brevetti (patents), marchi (trademarks) e segreti industriali (trade secrets). E' di valore per l'organizzazione, e il furto di IP è un rischio significativo.
- Software compliance/licensing: un'organizzazione investe tempo e risorse nello sviluppo del software e recupera l'investimento vendendo licenze d'uso. Se persone o organizzazioni usano il software senza licenza, l'azienda sviluppatrice perde soldi. Un'organizzazione può perdere soldi anche se acquista licenze ma non le protegge: nell'esempio di Gibson, un'azienda compra 10 licenze per un'applicazione, ma 5 vengono usate senza autorizzazione da persone non previste. Quando più tardi un supervisore assegna una licenza legittima a qualcun altro, l'applicazione restituisce errore "licenza già in uso": l'organizzazione ha perso il costo di 5 licenze.
- Legacy systems and legacy platforms: il rischio principale è che il vendor non li supporti più. Se emergono vulnerabilità, il vendor non rilascia patch, e chiunque usi quel sistema legacy è a rischio. Vedi Legacy hardware/system per la distinzione legacy vs EOL.
Dev parallel: software compliance/licensing è lo stesso discorso delle licenze delle dipendenze open source: una libreria GPL dentro un prodotto proprietario, o i seat di licenza Jetbrains/Adobe condivisi tra più developer senza controllo, sono lo stesso tipo di rischio. Legacy systems: un'app Symfony su PHP 7.4 (EOL da novembre 2022) ancora in produzione è esattamente questo: PHP non riceverà più patch di sicurezza, e qualsiasi CVE futura su quella versione resta aperta per sempre.
Vulnerabilities#
mindmap
root((Vulnerabilities))
Default Configurations
not hardened
default username password
Missing Antimalware
outdated signatures
Weak Patch Management
known flaws unpatched
Missing Firewall
no host or network protection
Missing Policies
no job rotation
fraud collusion risk
Exploited or Not
vulnerability is static
risk depends on context
war driving example
Una vulnerabilità è una falla o debolezza (flaw/weakness, vedi flaw) in un software, hardware o processo che una minaccia potrebbe sfruttare, causando una violazione della sicurezza (security breach). Alcuni esempi di vulnerabilità:
| Vulnerabilità | Descrizione | Approfondimento nel vault |
|---|---|---|
| Configurazioni predefinite (default configurations) | Un sistema non hardenizzato mantiene username, password e impostazioni di fabbrica: più facile da attaccare. L'hardening prevede di cambiare queste configurazioni di default. | Hardening Workstations and Servers |
| Mancanza di protezione antimalware o definizioni non aggiornate | Antivirus e anti-malware proteggono i sistemi dal malware, ma solo se attivi e con firme aggiornate. | Antivirus e Anti-Malware |
| Patch management debole o inadeguato | Sistemi non aggiornati con patch, hotfix e service pack restano esposti a bug e falle note nel software, OS o firmware, che un attaccante può sfruttare anche se la correzione esiste già. | Patching and Patch Management |
| Mancanza di firewall | Senza firewall host-based e di rete configurati correttamente, i sistemi sono più vulnerabili ad attacchi via rete e Internet. | Firewall |
| Mancanza di policy organizzative | Senza job rotation, mandatory vacation e least privilege, l'organizzazione è più esposta a frodi e collusione tra dipendenti. | Credential Policy |
Non tutte le vulnerabilità vengono sfruttate. Ad esempio, un utente potrebbe installare un router wireless lasciando le impostazioni di default: è altamente vulnerabile a un attacco, ma questo non significa che un attaccante lo scoprirà e lo attaccherà. In altre parole, il fatto che quel router wireless non sia mai stato attaccato non significa che non sia vulnerabile. In qualsiasi momento, un attaccante in war driving potrebbe passare nei dintorni e sfruttare quella vulnerabilità.
Dev parallel: è lo stesso discorso di una dipendenza con una CVE nota ma mai sfruttata in produzione: npm audit la segnala come vulnerabilità, ma se nessuno scansiona attivamente quell'endpoint il rischio resta "teorico" fino al giorno in cui qualcuno (o un bot) prova quell'exploit specifico.
Risk Management Strategies#
mindmap
root((Risk Management
Strategies))
Core Terms
Risk Awareness
Inherent Risk
Residual Risk
Control Risk
Risk Tolerance
Risk Appetite
Expansionary
Conservative
Neutral
Risk Threshold
4 Strategies
Avoidance
stop the activity
Mitigation
controls reduce risk
Acceptance
cost exceeds risk
exemption exception
Transference
insurance
cybersecurity insurance
Risk Assessment Types
one-time recurring continuous
Alcuni termini di base:
| Termine | Definizione | Esempio |
|---|---|---|
| Risk awareness (consapevolezza del rischio) | Il riconoscimento che un rischio esiste e va affrontato. Il management senior deve prima riconoscerlo, altrimenti non dedicherà risorse alla sua gestione. | Un CISO presenta al board i rischi di un sistema legacy non patchabile: prima di quel momento il management non sapeva nemmeno che il rischio esistesse. |
| Inherent risk (rischio inerente) | Il rischio che esiste prima che siano applicati dei controlli. | Un endpoint appena installato, senza hardening né antivirus. |
| Residual risk (rischio residuo) | Il rischio che rimane dopo aver mitigato il rischio a un livello accettabile. Il management decide il livello accettabile e le risorse da dedicare alla gestione. | Anche con antivirus, firewall e patch aggiornate, resta sempre un margine di rischio. |
| Control risk (rischio di controllo) | Il rischio che esiste se i controlli già in vigore non gestiscono adeguatamente il rischio. | Antivirus installato ma senza un meccanismo affidabile di aggiornamento delle firme: servono controlli aggiuntivi. |
| Risk tolerance (tolleranza al rischio) | La capacità dell'organizzazione di sostenere un rischio, distinta dalla sua disponibilità ad assumerlo (quella è il risk appetite). | Un'azienda con molta liquidità tollera meglio un rischio finanziario rispetto a una con poca liquidità. |
Risk appetite (appetito al rischio): la quantità di rischio che un'organizzazione è disposta ad accettare, in base ai propri obiettivi e alla propria strategia. Da qui deriva la risk threshold (soglia di rischio): il livello che una situazione deve raggiungere prima che l'organizzazione decida di agire per gestirla. Esistono 3 categorie di risk appetite:
| Categoria | Atteggiamento | Esempio |
|---|---|---|
| Expansionary (espansivo) | Alto rischio per alti rendimenti | Investire pesantemente in tecnologie di sicurezza all'avanguardia, o perseguire aggressivamente nuove opportunità di business anche a costo di rischi di sicurezza aggiuntivi |
| Conservative (conservativo) | Preferenza per investimenti a basso rischio, priorità a preservare l'attuale postura di sicurezza | Concentrarsi su misure di sicurezza di base, evitare nuove tecnologie che potrebbero introdurre nuovi rischi |
| Neutral (neutro) | Approccio bilanciato | Adottare nuove tecnologie ma con implementazione cauta e controlli di sicurezza aggiuntivi |
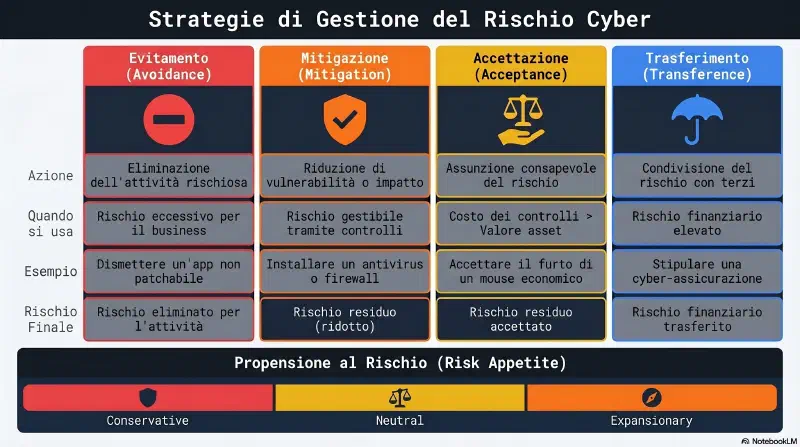
Le strategie di gestione del rischio sono le stesse 4 viste in Risk Concepts (Mitigate, Transfer, Accept, Avoid - qui Gibson le chiama Avoidance, Mitigation, Acceptance, Transference), approfondite con esempi:
- Avoidance: l'organizzazione evita un rischio non offrendo un servizio o non partecipando a un'attività rischiosa. Esempio: un'applicazione richiederebbe l'apertura di troppe porte sul firewall, viene valutata troppo rischiosa e dismessa.
- Mitigation: si implementano controlli che riducono la vulnerabilità oppure l'impatto della minaccia. Esempio: un antivirus aggiornato mitiga il rischio malware; una guardia riduce il rischio che un attaccante accéda a un'area protetta.
- Acceptance: quando il costo di un controllo supera il rischio, l'organizzazione accetta il rischio. Esempio classico: non spendere 100$ di lucchetti per proteggere un mouse da 15$. Vale anche per il rischio residuo che rimane dopo qualsiasi controllo. Se l'accettazione comporta la violazione di una policy, una legge o una norma, l'organizzazione richiede una exemption o exception (esenzione/eccezione) formale a quella policy o standard.
- Transference: l'organizzazione trasferisce (o condivide) il rischio con un'altra entità, tipicamente acquistando un'insurance (assicurazione): una parte del rischio finanziario passa dall'organizzazione alla compagnia assicurativa, che rimborsa i costi o i danni legati al rischio. La cybersecurity insurance copre nello specifico le perdite legate a incidenti come data breach o ransomware, che le polizze assicurative tradizionali di solito escludono.
Da ricordare: il rischio non si elimina, si gestisce.
- Avoidance = non svolgere l'attività rischiosa.
- Transference = trasferire il rischio a un'altra entità (assicurazione).
- Mitigation = implementare controlli che riducono il rischio.
- Acceptance = quando il costo dei controlli supera il costo del rischio, l'organizzazione accetta il rischio residuo che rimane.
Risk Assessment Types#
mindmap
root((Risk
Assessment Types))
Frequency
one-time ad hoc
recurring
continuous
Asset Value
AV quantifies value
prioritize high value
Methods
Quantitative
monetary figures
Qualitative
judgment based
Risk Control Assessment
evaluates existing controls
self-assessment conflict
Un risk assessment (valutazione del rischio, anche chiamato risk analysis/analisi del rischio) è un compito centrale nella gestione del rischio: quantifica o qualifica i rischi sulla base di valori o giudizi diversi. Può essere:
- one-time / ad hoc (una tantum): una fotografia del rischio in un momento preciso.
- recurring (ricorrente): ripetuto periodicamente, ad esempio un risk assessment annuale.
- continuous (continuo): il rischio viene ri-valutato costantemente man mano che l'ambiente tecnico e di business cambia.
Il primo passo di un risk assessment è identificare gli asset e il loro valore. Un asset è qualsiasi prodotto, sistema, risorsa o processo a cui l'organizzazione attribuisce un valore, e l'Asset Value (AV) quantifica quel valore per l'organizzazione, normalmente come cifra monetaria specifica. L'AV aiuta l'organizzazione a concentrarsi sugli asset di alto valore senza sprecare tempo su quelli di basso valore.
Una volta identificati i valori degli asset, il risk assessment identifica minacce e vulnerabilità e determina la probabilità che una minaccia tenti di sfruttare una vulnerabilità (vedi #Probabilità e impatto: le due dimensioni del rischio). Cerca di identificare l'impatto delle potenziali minacce, il danno potenziale (harm), e di prioritizzare i rischi in base a probabilità e impatto. Infine, include raccomandazioni su quali security control implementare per mitigarli: queste raccomandazioni alimentano il risk register.
E' comune eseguire un risk assessment su sistemi o applicazioni nuovi: se un'organizzazione valuta l'introduzione di un nuovo servizio che potrebbe aumentare i ricavi, esegue spesso un risk assessment per capire se i rischi potenziali compensano i guadagni potenziali.
I risk assessment usano misurazioni quantitative o qualitative. Le misurazioni quantitative usano numeri, ad esempio una cifra monetaria che rappresenta costi e valori degli asset. Le misurazioni qualitative usano giudizi. Entrambi i metodi hanno lo stesso obiettivo: aiutare il management a prendere decisioni informate basate su priorità.
Un risk control assessment (a volte chiamato risk and control assessment) (assessment == valutazione) esamina i rischi noti di un'organizzazione e valuta l'efficacia dei controlli già in vigore. Se è disponibile un risk assessment, il risk control assessment lo usa per identificare i rischi noti, poi si concentra sui controlli in vigore per determinare se li mitigano adeguatamente.
Esempio: un risk assessment identifica il malware come rischio. L'organizzazione installa un antivirus sul mail server per bloccare tutte le email in entrata che contengono malware. Il risk control assessment farà probabilmente notare che il malware arriva da molteplici fonti, quindi l'antivirus solo sul mail server non basta a mitigare il rischio: potrebbe raccomandare di installarlo su tutti gli host interni e di usare un network appliance per scansionare tutto il traffico in entrata in cerca di traffico malevolo.
Il risk control self-assessment è un risk control assessment eseguito dai dipendenti stessi, invece che da terze parti. Il pericolo dell'auto-valutazione: agli stessi dipendenti che hanno installato i controlli potrebbe essere chiesto di valutarne l'efficacia, un evidente conflitto di interessi.
Quantitative Risk Assessment#
mindmap
root((Quantitative
Risk Assessment))
Asset Value AV
Exposure Factor EF
SLE equals AV times EF
ARO annual rate
ALE equals SLE times ARO
Flood Example
Stolen Laptops Example
Un quantitative risk assessment (valutazione quantitativa del rischio) misura il rischio usando una cifra monetaria specifica, il che rende più facile prioritizzare i rischi: un rischio con una perdita potenziale di $30.000 è molto più importante di uno con una perdita potenziale di $1.000.
Si parte identificando due fattori per ogni rischio:
- Asset Value (AV): molte organizzazioni usano il costo di sostituzione (replacement cost) dell'asset come AV, perché è il costo che l'organizzazione dovrebbe sostenere se il rischio si materializzasse.
- Exposure Factor (EF): la porzione dell'asset che ci si aspetta venga danneggiata se il rischio si materializza.
Da questi due valori si calcola la Single Loss Expectancy (SLE), il costo di una singola perdita di quell'asset specifico: SLE = AV x EF.
Esempio: un rack di apparecchiature nel basement dell'ufficio costerebbe $1.000.000 da sostituire (AV = $1.000.000). Il rischio considerato è un'alluvione: si stima che un'alluvione tipica distruggerebbe metà delle apparecchiature (EF = 50%). Quindi SLE = $1.000.000 x 50% = $500.000: ci si aspetta che ogni volta che si verifica un'alluvione, causi $500.000 di danni.
La SLE misura l'impatto del rischio. Ma un'alluvione si verifica 10 volte all'anno o una volta ogni 10 anni? Per prendere una decisione informata serve anche la probabilità.
Qui entra in gioco l'Annualized Rate of Occurrence (ARO): indica quante volte ci si aspetta che la perdita si verifichi in un anno. Se l'ARO è minore di 1, viene espresso come percentuale. Se ci si aspetta un'alluvione in basement una volta ogni 10 anni, l'ARO = 10% (0.1). L'ARO è una misura di probabilità.
Infine, per unire impatto e probabilità si usa l'Annualized Loss Expectancy (ALE): ALE = SLE x ARO. Nel nostro esempio: ALE = $500.000 x 0.1 = $50.000. Ci si aspetta che, in un anno qualsiasi, il costo medio delle alluvioni sia $50.000, non che ogni anno ci sarà esattamente $50.000 di danni (in realtà ci si aspettano $500.000 di danni una volta ogni 10 anni). L'ALE serve a prioritizzare i rischi e a valutarne quantitativamente l'impatto sull'organizzazione.
Secondo esempio, i laptop rubati: i dipendenti perdono in media un laptop al mese, rubato in sala riunioni, durante visite ai clienti o in sala formazione. Ogni laptop vale $2.000 e, una volta perso, è perso del tutto: AV = $2.000, EF = 100%.
- SLE = AV x EF = $2.000 x 100% = $2.000
- ARO = 12 (un laptop al mese = 12 all'anno)
- ALE = SLE x ARO = $2.000 x 12 = $24.000
Qualcuno propone di acquistare lucchetti hardware (come un lucchetto da bicicletta: si avvolgono attorno a un mobile e si collegano al laptop) per un totale di $1.000. Gli esperti stimano che i lucchetti ridurrebbero i laptop persi da 12 a 2 all'anno: nuovo ALE = $2.000 x 2 = $4.000, un risparmio di $20.000/anno. Conviene comprarli? L'organizzazione spenderebbe $1.000 per risparmiare $20.000: un risparmio netto di $19.000. Si comprano.
Regola pratica per queste decisioni:
- Se il costo del controllo è inferiore al risparmio → si implementa il controllo (Mitigation).
- Se il costo del controllo è superiore al risparmio → si accetta il rischio (Acceptance, vedi #Risk Management Strategies).
Dev parallel: lo stesso ragionamento si applica quando si valuta se introdurre un WAF (Web Application Firewall). AV = valore dei dati esposti da un'app, EF = percentuale di dati che un data breach esporrebbe, SLE = AV x EF. ARO = quante volte all'anno ci si aspetta un attacco riuscito senza WAF, ALE = SLE x ARO. Se il costo annuale del WAF (es. licenza Cloudflare/AWS WAF) è inferiore alla riduzione di ALE che produce, si implementa; altrimenti si accetta il rischio residuo.
Da ricordare: un risk assessment quantitativo usa cifre monetarie specifiche per identificare costi e valori degli asset. La SLE identifica il costo di ogni singola perdita, l'ARO il numero di eventi in un anno tipico, l'ALE la perdita annua attesa dal rischio. ALE = SLE x ARO. Un risk assessment qualitativo usa giudizi per categorizzare i rischi in base a probabilità e impatto.
Qualitative Risk Assessment#
mindmap
root((Qualitative
Risk Assessment))
Judgment Based
Surveys Focus Groups
Low Medium High
Numeric Mapping 1 5 10
Risk equals Probability times Impact
Web Server vs Library Example
Un qualitative risk assessment (valutazione qualitativa del rischio) usa il giudizio per categorizzare i rischi in base a probabilità (likelihood of occurrence) e impatto: le stesse due dimensioni viste in #Probabilità e impatto: le due dimensioni del rischio. La probabilità è la probabilità che un evento si verifichi, ad esempio che una minaccia tenti di sfruttare una vulnerabilità. L'impatto è la magnitudo del danno risultante da un rischio: include i risultati negativi di un evento, come la perdita di confidentiality, integrity o availability di un sistema o dei dati.
La differenza con la valutazione quantitativa è netta: il quantitativo usa una quantità, un numero (cifre monetarie); il qualitativo riguarda la qualità, spesso una questione di giudizio.
Alcuni risk assessment qualitativi usano sondaggi o focus group: si raccolgono i giudizi di un gruppo di esperti e si tabulano i risultati. Ad esempio, un sondaggio potrebbe chiedere a un gruppo di esperti di valutare probabilità e impatto del rischio associato a un web server che vende prodotti su internet e a una postazione in biblioteca senza accesso a internet. Gli esperti useranno termini come Low, Medium, High per valutarli.
Potrebbero valutare la probabilità che il web server venga attaccato come High, e se l'attacco lo mette fuori servizio, anche l'impatto è High. Al contrario, la probabilità che la postazione in biblioteca venga attaccata è Low, e anche se un utente della biblioteca ne sarebbe infastidito, l'impatto è comunque Low.
E' comune assegnare numeri a questi giudizi: ad esempio Low/Medium/High → 1/5/10. Gli esperti assegnano probabilità e impatto a ciascun rischio usando Low/Medium/High, e quando si tabulano i risultati si convertono le parole in numeri: questo rende più semplice calcolare i risultati.
Negli esempi del web server e della postazione in biblioteca, si può calcolare il rischio moltiplicando probabilità e impatto:
| Asset | Probabilità | Impatto | Rischio (P x I) |
|---|---|---|---|
| Web server | High (10) | High (10) | 100 |
| Postazione biblioteca | Low (1) | Low (1) | 1 |
Il management può guardare questi numeri e decidere facilmente come allocare le risorse per proteggersi dai rischi: allocherà più risorse per proteggere il web server rispetto alla postazione in biblioteca. Una delle difficoltà di un risk assessment qualitativo è ottenere consenso su probabilità e impatto: a differenza dei valori monetari, verificabili con i fatti, probabilità e impatto sono spesso oggetto di dibattito.
Risk Reporting#
mindmap
root((Risk
Reporting))
Final Phase
lists risks found
recommends controls
SQL Injection Example
Management Decisions
implement or accept
Protect the Report
useful to attackers
restricted access
La fase finale del risk assessment è il risk reporting: identifica i rischi scoperti durante la valutazione e i controlli raccomandati. Esempio semplice: un risk assessment su una web application con database scopre che è vulnerabile a SQL injection. Il risk assessment raccomanderà quindi di riscrivere l'applicazione con tecniche di input validation e stored procedure per proteggere il database.
Il management usa questo report per decidere quali controlli implementare e quali rischi accettare. In molti casi, un report finale documenta le decisioni manageriali. Il management può anche decidere di non implementare un controllo e di accettare il rischio.
Pensate a quanto sarebbe utile questo report per un attaccante: non avrebbe bisogno di scavare per identificare vulnerabilità o controlli, il report elenca già tutti i dettagli. Anche quando il management approva i controlli per correggere le vulnerabilità, potrebbe volerci del tempo per implementarli.
Per questo motivo è importante proteggere il risk assessment report: normalmente solo l'alta dirigenza e i professionisti della sicurezza hanno accesso a questi report.
Risk Analysis#
mindmap
root((Risk
Analysis))
Key Risk Indicators
proactive metrics
incidents per month
patch lateness
Risk Register
list of risks
risk owner
Risk Matrix
probability vs impact grid
Figure 8.1
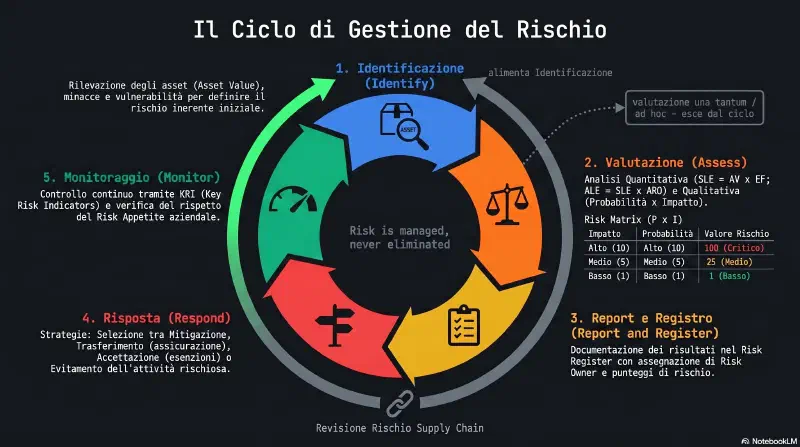
I risk assessment usano diverse tecniche per analizzare i rischi. In generale, una risk analysis (analisi del rischio) identifica i potenziali problemi che potrebbero avere un impatto negativo sugli obiettivi dell'organizzazione. Discipline diverse la definiscono in modo leggermente diverso: nel project management, una risk analysis identifica i rischi potenziali che potrebbero avere un impatto sui risultati e gli obiettivi di un progetto, piuttosto che dell'organizzazione. I termini seguenti potrebbero avere definizioni leggermente diverse nel project management o nella finanza, ma queste definizioni sono valide nel contesto cybersecurity:
- Key Risk Indicators (KRI) (indicatori chiave di rischio): metriche usate per misurare e monitorare il livello di rischio associato a un'attività, un processo o un sistema. Permettono all'organizzazione di identificare proattivamente i rischi potenziali e agire per mitigarli prima che diventino problemi significativi. Esempi: numero di incidenti di sicurezza rilevati al mese, percentuale di patch di sicurezza in ritardo, tempo medio per rilevare e rispondere a un incidente di sicurezza. Questi indicatori aiutano a identificare trend, rilevare problemi in anticipo e intervenire per minimizzare l'impatto dei rischi potenziali.
- Risk register (vedi risk register): documento o strumento che le organizzazioni usano per identificare, valutare e gestire i rischi. Include tipicamente un elenco dei rischi identificati, con probabilità, impatto potenziale e stato attuale. Aiuta a prioritizzare i rischi, allocare risorse per la mitigazione e monitorare i progressi nel tempo. Oltre a identificare i rischi, il risk register assegna i risk owner: individui o team responsabili di gestire ciascun rischio, monitorarlo, implementare le misure di mitigazione e riportarne lo stato.
- Risk matrix (matrice del rischio): un grafico a righe e colonne che mostra probabilità e impatto, come nella Figure 8.1 di Gibson:
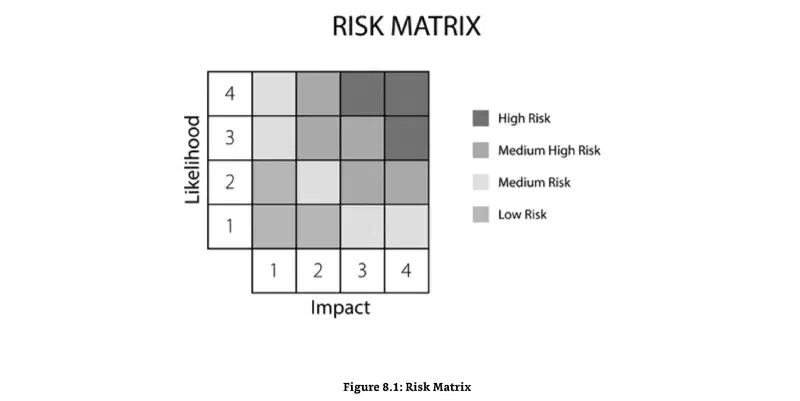
Riprendendo l'esempio del web server e della postazione in biblioteca: la postazione in biblioteca (Low/Low) cadrebbe nell'angolo a probabilità e impatto bassi, il web server (High/High) nell'angolo a probabilità e impatto alti.
Da ricordare: il risk register è un documento completo che elenca le informazioni note sui rischi, incluso il risk owner. Include tipicamente i risk score, insieme ai security control raccomandati per ridurli. La risk matrix posiziona i rischi su un grafico.
Supply Chain Risks#
mindmap
root((Supply Chain
Risks))
Definition
raw materials
processes and providers
Lard Lad Donuts example
Supply Chain as Attack Vector
Supply Chain attack
SolarWinds
XZ Utils
Mitigation
multiple sources
hard for complex materials
Dev Parallel
package monitoring
npm composer dependencies
Una supply chain (catena di approvvigionamento/catena di fornitura) include tutti gli elementi necessari per produrre e vendere un prodotto. Esempio di Gibson: il negozio Lard Lad Donuts ha bisogno di un flusso costante di farina, zucchero, uova, latte, olio e altri ingredienti. Ha bisogno di frigoriferi per conservare le materie prime, di spazio per produrre i donut e di friggitrici per cuocerli. Infine, ha bisogno di un metodo per vendere i donut ai clienti. Se uno qualsiasi di questi elementi viene a mancare, l'azienda non può più produrre e vendere donut.
E' importante capire che la supply chain non riguarda solo le materie prime: include anche tutti i processi necessari per creare e distribuire il prodotto finito. Per un'organizzazione IT, una revisione completa della supply chain significa guardare a ogni organizzazione che fornisce una componente essenziale del proprio ambiente tecnologico: fornitori hardware, fornitori software e service provider.
La supply chain può diventare essa stessa un vettore di attacco: se un attaccante vuole fermare la produzione di donut, non è necessario attaccare il negozio direttamente. Può invece colpire uno dei fornitori terzi nella supply chain (supply chain attack, vedi Supply Chain per il meccanismo e i casi reali SolarWinds e XZ Utils). Un indicatore di un possibile supply chain attack è un'interruzione nella supply chain stessa.
Un'organizzazione può eliminare la supply chain come rischio di terze parti semplicemente assicurandosi di avere fonti multiple per tutto ciò di cui ha bisogno. Questo è relativamente semplice quando si cercano fonti alternative per farina e zucchero, ma può diventare difficile quando l'organizzazione ha bisogno di materiali complessi.
Dev parallel: è lo stesso ragionamento di Package Monitoring applicato a livello organizzativo: non basta sapere quali dipendenze npm/composer usi (il "fornitore software"), serve anche un piano B se quella libreria viene abbandonata, compromessa o il suo maintainer smette di rispondere.
Comparing Scanning and Testing Tools#
mindmap
root((Comparing Scanning
and Testing Tools))
Vulnerability Scanner
checks for weaknesses
Vulnerability Scanning
Network Scanners
Penetration Test
attempts exploitation
Reconnaissance
Exploitation Chain
Configuration Review
compares to baseline
Responsible Disclosure
bug bounty programs
System and Process Audits
compliance checks
Gli amministratori di sicurezza usano strumenti per testare le proprie reti. Due categorie comuni di strumenti sono i vulnerability scanner (scanner di vulnerabilità), che verificano la presenza di debolezze, e i penetration test (test di intrusione), che tentano di sfruttare le vulnerabilità trovate. Questa sezione approfondisce entrambi.
Checking for Vulnerabilities#
mindmap
root((Checking for
Vulnerabilities))
Vulnerability Assessment
evaluates security posture
identify asset value
prioritize and recommend
Vulnerability Scan
passive identification
Sources
Network Scanners
Configuration Review
Le vulnerabilità sono debolezze (vedi #Vulnerabilities) e riducendole si riduce il rischio. Sembra semplice. Ma come si identificano le vulnerabilità che rappresentano il rischio maggiore? Due metodi comuni sono il ==vulnerability assessment== (valutazione delle vulnerabilità) e il ==vulnerability scan== (scansione delle vulnerabilità).
L'obiettivo generale di un vulnerability assessment è valutare la ==postura di sicurezza (security posture)== di sistemi e reti. Identifica vulnerabilità o debolezze all'interno di sistemi, reti e organizzazioni, ed è parte di un più ampio piano di risk management.
Un vulnerability assessment può raccogliere informazioni da una grande varietà di fonti: revisione di policy di sicurezza e log, interviste al personale e test sui sistemi. Le assessment usano spesso una combinazione di scansioni e penetration test, entrambi trattati in questa sezione. A livello generale, un vulnerability assessment prevede questi passaggi:
- Identificare gli asset e le relative capacità.
- Stabilire le priorità degli asset in base al valore.
- Identificare le vulnerabilità e stabilirne le priorità.
- Raccomandare controlli per mitigare le vulnerabilità più gravi.
Molte organizzazioni eseguono i vulnerability assessment internamente. Altre assumono professionisti esterni per assessment indipendenti. Le sezioni seguenti trattano molti degli strumenti comuni usati per vulnerability assessment e vulnerability scan.
Network Scanners#
mindmap
root((Network
Scanners))
ARP Ping Scan
SYN Stealth Scan
Port Scan
well known ports
Service Scan
verifies protocol
OS Detection
TCP IP fingerprinting
TCP window size
Un network scanner (scanner di rete) usa diverse tecniche per raccogliere informazioni sugli host di una rete. Lo strumento più diffuso è nmap, che da solo può fornire una grande quantità di informazioni sugli host di una rete. I network scanner usano tipicamente questi metodi:
- ARP ping scan: come visto in ARP, qualsiasi host che riceve un pacchetto ARP con il proprio IP risponde con il proprio MAC address. Se l'host risponde, lo scanner sa che esiste un host attivo su quell'IP.
- SYN stealth scan: richiama il three-way handshake TCP (SYN → SYN/ACK → ACK). Lo scan invia un singolo pacchetto SYN a ogni IP del range: se l'host risponde, lo scanner sa che è attivo su quell'IP. Invece di completare la connessione con un ACK, però, lo scanner risponde tipicamente con un RST (reset) per chiuderla subito - è esattamente il meccanismo descritto in SYN Flood Attacks per
nmap -sS. - Port scan: verifica quali porte sono aperte su un sistema. Ogni porta aperta indica che il protocollo sottostante è in esecuzione: ad esempio, se la porta 443 è aperta, l'host probabilmente esegue HTTPS ed è quindi un web server. Un port scan usa tipicamente le well-known port (porte note) definite dalla IANA (Internet Assigned Numbers Authority), vedi Well-Known Ports.
- Service scan: va un passo oltre il port scan. Mentre il port scan identifica le porte aperte e suggerisce quali protocolli o servizi potrebbero essere in esecuzione, ==il service scan verifica effettivamente il protocollo o servizio.== Ad esempio, se un port scan trova la porta 443 aperta, un service scan invia un comando HTTPS come
GET /: se HTTPS è davvero in esecuzione su quella porta, il server risponde al comando confermando che si tratta di un web server. - OS detection: tecniche di ==rilevamento del sistema operativo== che analizzano i pacchetti provenienti da un IP per identificarne l'OS, spesso chiamate TCP/IP fingerprinting (vedi #Footprinting Versus Fingerprinting). Esempio: la TCP window size (la dimensione della finestra di ricezione nel primo pacchetto di una sessione TCP) non è fissa e varia da sistema operativo a sistema operativo - alcune versioni di Linux usano 5.840 byte, alcuni router Cisco 4.128 byte, diverse versioni di Windows 8.192 o 65.535 byte. Le tecniche di OS detection non si basano su un singolo valore, ma valutano tipicamente più valori nelle risposte del sistema.
Dev parallel: il service scan è l'equivalente del banner grabbing che già conosci dal lato server: un header Server: nginx/1.18.0 o X-Powered-By: PHP/8.2 in una risposta HTTP rivela framework e versione tanto quanto un GET / su una porta 443 aperta. Per questo molte guide di hardening Symfony/Nginx consigliano di rimuovere o oscurare questi header. Localmente, ss -tulpn (o il vecchio netstat -tulpn) ti mostra le stesse informazioni di un port scan, ma dall'interno della macchina invece che da remoto.
Vulnerability Scanning#
mindmap
root((Vulnerability
Scanning))
Actions
identify vulnerabilities
identify misconfigurations
test controls passively
Classification Standards
CVE
MITRE dictionary
CVSS
0 to 10 severity
SCAP
Prioritizing
classification
environmental variables
industry impact
risk tolerance
Analyzing Output
host and port lists
recommendations
compare to prior scans
Confirmation of Results
False Positive
False Negative
worst case
True Positive True Negative
Un vulnerability scanner (scanner di vulnerabilità) identifica un'ampia gamma di debolezze e problemi di sicurezza noti che un attaccante potrebbe sfruttare. La maggior parte dei vulnerability scanner combina più funzionalità in un unico strumento. Una vulnerability scan include tipicamente queste azioni:
- Identificare vulnerabilità: individuare falle note in sistemi, applicazioni e processi (vedi #Vulnerabilities).
- Identificare misconfigurazioni: rilevare configurazioni non sicure o lasciate ai valori di default (vedi Configurazioni predefinite).
- Testare passivamente i security control: verificare se i controlli esistenti sono presenti e funzionano, senza interferire con le operazioni normali.
- Identificare la mancanza di security control: ad esempio patch mancanti, antivirus non installato, firewall assente.
Vulnerability Classification Standards
Per fare tutto questo, i vulnerability scanner usano database o dizionari di vulnerabilità note e testano i sistemi confrontandoli con questi database:
| Standard | Espansione | Cosa fa |
|---|---|---|
| CVE | Common Vulnerabilities and Exposures | Dizionario pubblico delle vulnerabilità note, mantenuto da MITRE Corporation e finanziato dal governo USA |
| CVSS | Common Vulnerability Scoring System | Assegna a ogni vulnerabilità un punteggio di gravità da 0 a 10 (10 = più severo), per aiutare a prioritizzare la mitigazione |
| SCAP | Security Content Automation Protocol | Formato comune che facilita la comunicazione tra vulnerability scanner e altri strumenti di sicurezza e gestione |
Il CVE funziona in modo analogo alle signature dell'antivirus (vedi Antivirus e Anti-Malware): la differenza è che il CVE è un'unica ==lista pubblica==, mentre i vendor di antivirus mantengono ==signature file proprietari==. Per il dettaglio completo su CVE, NVD e CVSS vedi cve-nvd.
Dev parallel: SCAP è l'equivalente "security" del SARIF (Static Analysis Results Interchange Format) usato da GitHub Code Scanning. E' un formato comune che Trivy, Snyk, CodeQL o un plugin ESLint di security possono produrre, e che un'altra piattaforma può consumare per aggregare i risultati di scanner diversi in un'unica dashboard.
Prioritizing Vulnerabilities
Dopo una vulnerability scan, un'organizzazione si trova spesso con decine, centinaia o migliaia di vulnerabilità. Per prioritizzarle usa diverse fonti informative:
| Fattore | Descrizione |
|---|---|
| Vulnerability classification | Uno standard di classificazione, tipicamente il CVSS score, identifica tipo e severità della vulnerabilità |
| Environmental variables | Ogni organizzazione opera in un contesto tecnico diverso: la stessa vulnerabilità ha una priorità diversa in ambienti diversi |
| Industry/organizational impact | Settori diversi gestiscono dati diversi, con regolamenti e sensibilità diverse: una vulnerabilità gravissima in un sistema di online banking può essere molto meno preoccupante su un sistema che monitora il flusso dell'acqua |
| Risk tolerance/threshold | L'organizzazione decide il livello di rischio che una vulnerabilità deve raggiungere prima di essere affrontata: non è possibile correggere ogni vulnerabilità esistente, quindi serve una soglia |
L'ultimo fattore riprende risk tolerance e risk threshold già definiti in questo capitolo (vedi #Risk Management Strategies).
Dev parallel: è esattamente il triage di un report npm audit o di un Dependabot alert. Il CVSS score da solo (vulnerability classification) non basta: una CVE "Critical" su una libreria di logging usata solo in un cron job notturno (environmental variable: non raggiungibile da input esterno, vedi il dev parallel sulla reachability in #Vulnerabilities) ha priorità molto più bassa di una CVE "High" su una libreria che parsa direttamente l'input di un form pubblico in un'app che gestisce pagamenti (industry/organizational impact). Il risk tolerance/threshold del team è spesso codificato in pratica: la soglia minima di severità sotto la quale npm audit --audit-level=high o composer audit non fanno fallire la pipeline CI.
Analyzing Vulnerability Scan Output
Una vulnerability scan produce un report con queste informazioni:
- Elenco degli host scoperti e scansionati.
- Elenco dettagliato delle applicazioni in esecuzione su ciascun host.
- Elenco dettagliato di porte e servizi aperti su ciascun host (vedi Port scan e Service scan).
- Elenco delle vulnerabilità scoperte su ciascun host.
- Raccomandazioni per risolvere le vulnerabilità scoperte.
Molti vulnerability scanner possono essere configurati per eseguire scan automaticamente a orari prestabiliti. Gli amministratori usano report predefiniti o ne creano di personalizzati, tipicamente disponibili come log da rivedere periodicamente (log review).
Un punto importante dell'analisi è confrontare lo scan corrente con gli scan precedenti. Se la stessa vulnerabilità continua a comparire scan dopo scan, ci sono tipicamente due spiegazioni:
- Una patch ha effetti collaterali indesiderati (side effects), quindi il management ha deciso di accettare il rischio e non applicarla (vedi Acceptance).
- Il vendor non ha ancora rilasciato una patch per quella vulnerabilità: è esattamente il rischio dei legacy system visto in #Risk Types.
Dev parallel: è l'equivalente di un report Trivy o Grype su un'immagine Docker, che elenca i package installati, le CVE trovate con relativa severità e la versione in cui la vulnerabilità è risolta ("fixed in"). La ricorrenza della stessa CVE scan dopo scan corrisponde a una entry in un file .trivyignore o in un'allowlist di audit-ci: una decisione esplicita di accettare quel rischio (caso 1), oppure una dipendenza EOL per cui non esiste e non esisterà mai una versione "fixed in" (caso 2, come l'app Symfony su PHP 7.4 vista in #Risk Types).
Passively Testing Security Controls
Un punto centrale: ==una vulnerability scan non tenta di sfruttare nessuna vulnerabilità==. E' un tentativo passivo di identificare le debolezze, e questo garantisce che il test non interferisca con le operazioni normali. Gli amministratori di sicurezza valutano poi le vulnerabilità trovate per decidere quali mitigare.
Al contrario, un penetration test (trattato più avanti in questo capitolo) è un test attivo che tenta effettivamente di sfruttare le vulnerabilità.
Dev parallel: è la stessa distinzione tra SAST e DAST/fuzzing vista in Analyzing and Reviewing Code. Una vulnerability scan è come un SAST: analizza il sistema senza "attaccarlo" davvero, a basso rischio di rompere qualcosa. Un penetration test è come il fuzzing o un DAST aggressivo: esegue l'attacco per davvero, e può effettivamente mandare in crash o compromettere il sistema target.
Da ricordare: un vulnerability scanner identifica vulnerabilità, sistemi mal configurati e la mancanza di security control come patch aggiornate. Una vulnerability scan è configurata per essere passiva, con impatto minimo sul sistema durante il test. Al contrario, un penetration test è intrusivo e può potenzialmente compromettere il sistema.
Confirmation of Scan Results
Gli scanner non sono perfetti. A volte segnalano una vulnerabilità che in realtà non esiste: è un false positive (falso positivo). Esempio di Gibson: una vulnerability scan su un server segnala patch mancanti per un'applicazione database, ma su quel server il database non è nemmeno installato. Uno dei compiti principali dopo una vulnerability scan è confermare se la vulnerabilità esiste davvero, eliminando i falsi positivi dal report.
E' lo stesso fenomeno dei falsi positivi in un IDS (un alert scatta ma non c'è nessuna intrusione reale) o in un antivirus heuristic-based, che può segnalare un'applicazione legittima come malware anche se non contiene codice malevolo (vedi Antivirus e Anti-Malware: l'heuristic detection produce più falsi positivi della signature detection proprio per questo). I falsi positivi aumentano l'overhead amministrativo: ogni segnalazione va investigata, anche quelle che si rivelano innocue.
Gli scanner possono anche produrre false negative (falsi negativi): la vulnerabilità esiste, ma lo scanner non la rileva e non la segnala. Esempio di Gibson, lo stesso visto sopra in Analyzing Vulnerability Scan Output: una patch rompe l'applicazione, il management accetta il rischio e non la applica. Anche se la patch manca davvero, lo scanner non segnala quella vulnerabilità.
Le quattro possibilità quando uno scanner cerca vulnerabilità su un sistema (Figure 8.2 di Gibson):
| Vulnerabilità esiste | Vulnerabilità non esiste | |
|---|---|---|
| Scanner accurato | True Positive | True Negative |
| Scanner non accurato | False Negative | False Positive |
- True positive: lo scanner identifica correttamente una vulnerabilità che esiste davvero.
- True negative: il sistema non ha la vulnerabilità, e lo scanner correttamente non la segnala.
- False positive: lo scanner segnala una vulnerabilità che non esiste.
- False negative: ==la vulnerabilità esiste, ma lo scanner non la rileva==: il caso peggiore, perché dà una falsa sensazione di sicurezza.
Dev parallel: è la stessa matrice di un test suite o di un linter. Un test che fallisce su codice corretto (flaky test) è un false positive: perdi tempo a investigare un problema che non c'è. Un test che resta verde su codice che poi si rompe in produzione è un false negative, il caso peggiore, perché dà falsa sicurezza - esattamente come uno scanner che non segnala una vulnerabilità reale. Stesso discorso per ESLint/SonarQube: una regola troppo aggressiva genera false positive (rumore, gli sviluppatori iniziano a ignorare i warning), una regola troppo permissiva genera false negative (bug reali che passano il review).
Da ricordare: un false positive indica che lo scanner ha rilevato una vulnerabilità che non esiste. Un false negative indica che la vulnerabilità esiste ma lo scanner non la rileva. True positive e true negative sono i due casi in cui lo scanner ha ragione.
Credentialed vs. Non-Credentialed Scans#
mindmap
root((Credentialed vs
Non-Credentialed))
Credentialed Scan
uses account credentials
exact software versions
fewer false positives
Non-Credentialed Scan
no credentials
attacker view
Privilege Escalation Link
attacker gains creds later
Un vulnerability scanner può eseguire due tipi di scan:
- Credentialed scan (scan con credenziali): usa le credenziali di un account per accedere al sistema.
- Non-credentialed scan (scan senza credenziali): non usa nessuna credenziale.
Gli attaccanti tipicamente non hanno le credenziali di un account interno, quindi quando scansionano un sistema eseguono scan non-credentialed: ==è esattamente la vista che ha un attaccante esterno prima di qualsiasi privilege escalation== (vedi #Privilege Escalation).
Gli amministratori di sicurezza eseguono invece spesso credentialed scan, tipicamente con i privilegi di un account amministrativo. Questo permette allo scan di verificare i problemi di sicurezza a un livello molto più profondo di un non-credentialed scan: per esempio, un credentialed scan può elencare le versioni esatte del software installato su un sistema. Inoltre, potendo accedere al funzionamento interno del sistema, un credentialed scan ha un impatto minore sui sistemi testati, risultati più accurati e meno falsi positivi.
E' interessante notare che gli attaccanti tipicamente iniziano senza credenziali, ma usano tecniche di privilege escalation per ottenere accesso amministrativo: a quel punto possono eseguire scan credentialed anche loro, se vogliono. Allo stesso modo, anche se un credentialed scan è generalmente più accurato, gli amministratori eseguono spesso anche scan non-credentialed per vedere cosa vedrebbe un attaccante senza credenziali.
Dev parallel: è la differenza tra
npm audit/composer auditeseguito localmente con accesso apackage-lock.json/composer.lock(equivalente credentialed: vede esattamente quali versioni sono installate, zero ambiguità, zero falsi positivi da "indovinare" la versione) e uno scanner black-box che colpisce il tuo endpoint pubblico dall'esterno cercando di indovinare framework e versioni dai response header (equivalente non-credentialed, lo stesso banner grabbing visto in #Network Scanners). Uno scan nella pipeline CI con accesso al codice è credentialed; un Nessus/Qualys puntato sul tuo IP pubblico senza login è non-credentialed.
Da ricordare: un false positive indica che uno scan ha rilevato una vulnerabilità che non esiste. I credentialed scan girano nel contesto di un account valido e ottengono informazioni più dettagliate sui target, come le versioni del software installato. Sono tipicamente più accurati dei non-credentialed scan e producono meno falsi positivi.
Configuration Review#
mindmap
root((Configuration
Review))
Baseline File
desired state
Configuration Validation
compares actual vs desired
Scheduled Scans
automation scripting
Requires Credentialed Scan
drift detection
Ansible Terraform
Un configuration compliance scanner (scanner di conformità della configurazione) esegue una configuration review dei sistemi per verificare che siano configurati correttamente. Tipicamente usa un file che definisce la configurazione corretta attesa per un sistema (una baseline): durante lo scan, il tool confronta la configurazione effettiva del sistema con quella definita nel file. Questo confronto si chiama anche configuration validation (validazione della configurazione).
Gli amministratori configurano spesso questi tool con automazione o scripting, in modo che girino automaticamente secondo una pianificazione (scheduled scan).
==Le configuration review scan devono tipicamente essere eseguite come credentialed scan==: solo con le credenziali giuste il tool può leggere accuratamente la configurazione interna del sistema (vedi #Credentialed vs. Non-Credentialed Scans appena visto). Senza credenziali, il tool non avrebbe accesso ai file di configurazione, ai registri o ai parametri di sistema necessari per il confronto.
Dev parallel: è esattamente il drift detection che fai con Ansible, Chef, Puppet o Terraform. La "configuration file" di Gibson è il tuo playbook/manifest/file
.tf: definisce lo stato desiderato (desired state). Lo scan è unansible-playbook --checko unterraform plan: confronta lo stato desiderato con lo stato reale (actual state) e segnala le differenze (drift), senza applicarle. E come ogni configuration review, questi tool hanno bisogno di credenziali (SSH key, cloud API token) per leggere lo stato reale del sistema: senza accesso credenziale, non potrebbero fare il confronto. La baseline che molti configuration compliance scanner usano è spesso un CIS Benchmark (vedi #Benchmarks and Configuration Guides, più avanti in questo capitolo) o le linee guida di hardening già viste in Hardening Workstations and Servers.
Da ricordare: un configuration compliance scanner confronta la configurazione effettiva di un sistema con una ==configurazione di riferimento (configuration validation)==, tipicamente definita in un file di baseline. Richiede credentialed scan per leggere accuratamente la configurazione.
Penetration Testing#
mindmap
root((Penetration
Testing))
4 Categories
Physical
social engineering lock picking
Offensive
Red Team
Defensive
Blue Team
Integrated
Purple Team
Process
Rules of Engagement
Reconnaissance
Exploitation Chain
Testing Environments
Cleanup
Test Systems
staging avoids production impact
Il penetration testing (test di intrusione, o pentest) valuta attivamente i security control implementati in un sistema o in una rete. Inizia con una fase di reconnaissance per conoscere il target (vedi #Reconnaissance), ma va oltre: tenta di sfruttare le vulnerabilità trovate, simulando o eseguendo davvero un attacco.
Esistono quattro categorie principali di penetration test:
| Categoria | Descrizione | Tecniche tipiche |
|---|---|---|
| Physical | Identifica vulnerabilità nelle misure di sicurezza fisica dell'organizzazione: accesso non autorizzato a edifici, data center o altre aree riservate | social engineering, lock picking, bypass fisico dei controlli |
| Offensive | Simula un attacco reale alla rete, ai sistemi o alle applicazioni dal punto di vista dell'attaccante, per identificare vulnerabilità sfruttabili per ottenere accesso non autorizzato o causare danni | vulnerability scanning, exploitation delle vulnerabilità trovate (vedi #Initial Exploitation), lateral movement (vedi #Lateral Movement) |
| Defensive | Valuta i security control esistenti per identificare dove sono vulnerabili, prima che un attaccante li sfrutti | analisi delle regole firewall, configuration review (vedi #Configuration Review), pentest su web application |
| Integrated | Combina physical, offensive e defensive per una valutazione completa della postura di sicurezza, condotta da un team con competenze su sicurezza fisica, di rete e applicativa | simulazione di un attacco reale su asset fisici e digitali insieme |
Dev parallel: nel linguaggio comune dell'industry, Offensive ~ Red Team, Defensive ~ Blue Team (il tuo focus di carriera), Integrated ~ Purple Team (i due team che lavorano insieme e condividono i risultati).
Poiché un penetration test può sfruttare vulnerabilità reali, ha il potenziale di interrompere le operazioni e causare instabilità nei sistemi. Per questo è importante definire rigorosamente i confini (boundaries) di un test, vedi #Rules of Engagement. Idealmente ==il penetration test si ferma appena prima di eseguire un exploit che potrebbe causare danni o un'interruzione di servizio, ma alcuni test producono risultati inaspettati.==
Per questo motivo i tester a volte eseguono il penetration test su sistemi di test invece che sui sistemi di produzione live. Esempio di Gibson: un'organizzazione ospita una web application accessibile da internet. Invece di testare il server live (impattando i clienti), i tester o gli amministratori configurano un altro server con la stessa web application. Se il penetration test mette in ginocchio il server di test, dimostra comunque accuratamente le vulnerabilità di sicurezza, ma senza impattare i clienti.
Dev parallel: è esattamente l'ambiente di staging. Non lanci un test distruttivo (load test, chaos engineering, e qui un pentest) contro produzione: cloni l'app su un ambiente che assomiglia a prod, e lì puoi anche romperla senza conseguenze per gli utenti reali.
Da ricordare: ==un penetration test è un test attivo che valuta i security control implementati e determina l'impatto di una minaccia==. Inizia con reconnaissance e poi tenta di sfruttare le vulnerabilità attaccando o simulando un attacco.
Rules of Engagement#
mindmap
root((Rules of
Engagement))
Authorization Required
written consent
Defines Boundaries
ROE scope
Without Consent
is an attack
legal consequences
Bug Bounty Scope
in scope out of scope
E' fondamentale ottenere l'autorizzazione prima di iniziare qualsiasi vulnerability test o penetration test. Questa autorizzazione definisce le rules of engagement (ROE), cioè i confini del test. Se il test causa un'interruzione di servizio anche se i tester hanno seguito le ROE, le conseguenze per loro sono molto meno probabili.
Nella maggior parte dei casi questo consenso deve essere scritto. Se non è scritto, molti professionisti della sicurezza non eseguono nessun test. ==Un penetration test senza consenso è un attacco==: un'organizzazione può percepire un amministratore in buona fede che esegue un penetration test non autorizzato come un attaccante vero e proprio. L'amministratore potrebbe ritrovarsi ad aggiornare il curriculum poco dopo aver lanciato uno scan o un penetration test non autorizzato.
Dev parallel: è lo stesso principio dei programmi di bug bounty (HackerOne, Bugcrowd). Il documento di "scope" definisce esattamente quali domini/asset sono in-scope, quali out-of-scope, e regole come "niente DoS" o "niente social engineering". Testare qualcosa fuori scope, anche con le migliori intenzioni, non è coperto dall'autorizzazione: è la stessa situazione dell'amministratore senza ROE scritte.
Reconnaissance#
mindmap
root((Reconnaissance))
Passive Reconnaissance
OSINT
theHarvester
Whois DNS lookup
no target engagement
Active Reconnaissance
engages the target
Footprinting Fingerprinting
Exploitation Chain
Initial Exploitation
Persistence
Lateral Movement
Privilege Escalation
Pivoting
I penetration tester usano diversi metodi di reconnaissance (a volte chiamata footprinting). Durante questa fase, il tester (o l'attaccante) cerca di scoprire quante più informazioni possibili su una rete, combinando passive reconnaissance e active reconnaissance and discovery.
Passive and Active Reconnaissance
La passive reconnaissance raccoglie informazioni su un sistema, una rete o un'organizzazione target usando OSINT (Open-Source Intelligence): profili social, notizie, il sito web dell'organizzazione. Se l'organizzazione ha reti wireless, può includere la raccolta passiva di informazioni dalla rete, come gli SSID. ==La passive reconnaissance non engage il target, quindi non è illegale==.
theHarvester è un tool a riga di comando per passive reconnaissance, usato dai tester nelle prime fasi di un penetration test. Usa metodi OSINT per raccogliere indirizzi email, nomi di dipendenti, IP degli host e URL: interroga motori di ricerca (noti e meno noti) e correla i risultati in un report.
La passive reconnaissance non include l'uso di tool per inviare informazioni al target e analizzarne le risposte. Può però includere tool che raccolgono informazioni da sistemi diversi dal target: ad esempio, un Whois lookup può dare informazioni sul proprietario di un domain name, oppure si possono ottenere informazioni interrogando server DNS.
Dev parallel: hai già fatto passive recon senza chiamarla così. Ogni
whois dominio.como query DNS lanciata durante gli investigation lab (vedi bgp-asn-fundamentals) è passive reconnaissance: stai interrogando un registrar o un resolver DNS, non il target. theHarvester ha lo stesso spirito del code search su GitHub/GitLab per trovare API key o subdomain esposti in repository pubblici: raccogli quello che è già pubblico, senza toccare il target.
I metodi di active reconnaissance invece usano tool che impegnano (engage) direttamente i target.
Footprinting Versus Fingerprinting#
I metodi di network reconnaissance and discovery usano tool per inviare dati ai sistemi e analizzare le risposte. Questa fase inizia tipicamente con gli stessi network scanner e vulnerability scanner già visti in #Network Scanners: identificare tutti gli IP attivi su una rete, le porte e i servizi attivi su ogni sistema, e il sistema operativo in esecuzione.
==La network reconnaissance engage i target, quindi è quasi sempre illegale senza un'autorizzazione esplicita== (vedi #Rules of Engagement).
Alcuni tool usati in questa fase:
| Tool | Espansione | Cosa fa |
|---|---|---|
| IP scanner (ping scanner) | - | Cerca IP attivi su una rete, tipicamente con ping ICMP (Internet Control Message Protocol). Se l'host risponde, lo scanner sa che è operativo su quell'IP. I firewall spesso bloccano ICMP, quindi i risultati possono essere inconsistenti |
| Nmap | Network Mapper | Già visto in #Network Scanners: identifica host attivi, IP, protocolli/servizi e OS di ogni host |
| Netcat (nc) | - | Tool CLI usato dagli amministratori per accesso remoto a sistemi Linux. I tester lo usano per banner grabbing (OS e info sulle applicazioni), trasferimento file e verifica di porte aperte |
| Scanless | - | Tool CLI Python per port scan: usa un sito web terzo per eseguire lo scan, che quindi non parte dall'IP del tester ma da quello del sito |
| Dnsenum | DNS Enumeration | Enumera i record DNS di un dominio, identifica i mail server (record MX), e tenta un AXFR transfer per scaricare tutti i record dai server DNS. Gli AXFR transfer non autenticati sono di solito bloccati (vedi zone transfer) |
| Nessus | - | Vulnerability scanner di Tenable Network Security, basato su plug-in, spesso usato per configuration review (vedi #Configuration Review). AutoNessus automatizza gli scan Nessus |
| hping | - | Invia ping via TCP, UDP o ICMP, e può scansionare porte aperte su host remoti |
| Sn1per | - | Scanner automatizzato all-in-one per vulnerability assessment e information gathering durante un pentest. Edizione Community (assessment e info sui target) vs Professional (include anche l'exploitation) |
| cURL | Client URL | Trasferisce e recupera dati da server (es. web server). I tester usano script per enumerare tutti gli URL di un sito e poi cURL per scaricarne tutte le pagine. Bloccare le richieste cURL è molto più difficile che bloccare un browser |
Dev parallel: Netcat lo hai già usato in lab per la reverse shell (
nc -lvnp 4444, vedi reverse-shell) - qui Gibson lo presenta nel suo uso "legittimo" da pentester (banner grabbing, trasferimento file), stesso tool, scopo diverso. cURL è il comando che usi ogni giorno per testare le tue API REST: un pentester lo usa per scaricare ogni pagina di un sito dopo averne enumerato gli URL, stesso strumento, scopo di recon invece che di debug. L'IP scanner via ICMP è l'analogo a livello 3 dell'ARP ping scan visto in #Network Scanners (livello 2): funziona oltre la subnet locale, ma è molto più facile da bloccare con un firewall.
Tutto questo processo di mappatura attiva di una rete ha due fasi distinte:
- Footprinting: fase di raccolta informazioni ad ampio raggio. Capire quali host esistono, quali sono attivi, quali porte/servizi risultano esposti, quali range IP, DNS, ecc. È la "mappa grezza" che ti dice DOVE c'è qualcosa.
- Fingerprinting: fase di identificazione dettagliata di un singolo bersaglio/servizio trovato nel footprinting (già visto in OS detection, es. TCP window size). Non solo "porta 22 aperta", ma quale servizio, versione, sistema operativo, configurazioni note, ecc. È il passo che ti dice esattamente COSA c'è lì dietro. Il nome stesso è un'analogia voluta: come un'impronta digitale identifica un INDIVIDUO specifico (non solo "è un essere umano"), il fingerprinting identifica esattamente QUEL sistema/servizio (non solo "è un server").
Due fasi dello stesso processo, non sinonimi: il footprinting ti dice dove guardare, il fingerprinting prende quel risultato e lo analizza in dettaglio.
Da ricordare: la passive reconnaissance (OSINT, whois, query DNS) non engage il target e non è illegale. La network reconnaissance and discovery (active recon: nmap, netcat, dnsenum, ecc.) engage il target ed è quasi sempre illegale senza autorizzazione scritta. ==Il footprinting è la mappatura generale (host, porte)==; ==il fingerprinting è il passo successivo e più granulare che usa quei risultati per identificare OS/servizio esatti.==
Initial Exploitation#
Dopo footprinting e fingerprinting, i tester hanno una mappa dettagliata: host, porte, servizi, versioni esatte. Il passo successivo è la initial exploitation: trovare una vulnerabilità che si può effettivamente SFRUTTARE (exploit), non solo identificare.
Esempio tipico: una vulnerability scan rileva che un sistema non ha installato una patch per una vulnerabilità nota. Quella vulnerabilità permette ad attaccanti (e tester) di accedere da remoto al sistema e installare malware. Con questa informazione, i tester usano metodi noti per sfruttare la vulnerabilità — ottenendo accesso completo al sistema. Da lì possono installare software aggiuntivo sul sistema compromesso.
==L'initial exploitation è il momento in cui il test passa da "osservare" a "agire sul sistema"==: prima di questo punto (footprinting, fingerprinting, vulnerability scanning) il tester ha solo raccolto informazioni; da qui in poi ha effettivamente accesso a un sistema che prima non controllava.
Dev parallel: è esattamente lo scenario che hai già scritto in cve-nvd — Apache 2.4.49, CVE-2021-41773, CVSS 9.8 Critical, exploit pubblico disponibile su Exploit-DB. Il vulnerability scan (vedi #Vulnerability Scanning) ti dice "questa CVE esiste ed è critica". L'initial exploitation è il passo successivo: usare quell'exploit pubblico per ottenere davvero accesso al server. Per un Blue Team è anche il momento più importante da rilevare: un IDS/EDR che intercetta il traffico dell'exploit (o il processo malevolo risultante) PRIMA che l'attaccante ottenga accesso completo blocca tutta la catena successiva (persistence, lateral movement, pivoting).
Persistence#
La persistence è la capacità di un attaccante di mantenere una presenza nella rete per settimane, mesi o anche anni senza essere rilevato. I penetration tester usano tecniche simili per mantenere persistence durante il test (con autorizzazione, per dimostrare quanto a lungo un accesso non autorizzato potrebbe restare invisibile).
Una tecnica comune per mantenere persistence è creare una backdoor nella rete:
- creare account alternativi e accedervi da remoto (un secondo utente, magari con privilegi simili a quello compromesso, che nessuno si aspetta di dover controllare)
- installare o modificare servizi per "richiamare" (connect back) un sistema — esempio: abilitare SSH su un host dove normalmente non gira, e creare un metodo per autenticarsi via SSH
==La persistence è il motivo per cui un singolo "click" iniziale può costare mesi di indagine forense==: l'attaccante non si accontenta dell'accesso iniziale, costruisce deliberatamente ==più vie di rientro==, così che chiudere la falla originale non basti a cacciarlo.
Dev parallel: hai già visto backdoor/RAT dal lato attaccante in Accesso e Controllo. Qui Gibson descrive il MECCANISMO: una unit systemd o un cron job che riavvia periodicamente un servizio "innocuo" è esattamente lo stesso mezzo che usi tu per task di manutenzione legittimi (backup notturni, health check) — stesso strumento, intento opposto. Per il Blue Team: un nuovo utente locale creato fuori dal processo di provisioning normale, o un nuovo servizio systemd/cron che nessuno ricorda di aver configurato, sono tra le detection rule più semplici ed efficaci (file integrity monitoring su
/etc/passwd,/etc/cron.d/,/etc/systemd/system/).
Lateral Movement#
Quando un attaccante sfrutta per la prima volta il computer di un utente, spesso ottiene le CREDENZIALI di quell'utente. Usa quelle credenziali per accedere al sistema target, e poi usa QUEL sistema per il lateral movement: il modo in cui gli attaccanti si muovono attraverso la rete, da un sistema all'altro.
Esempio: WMI (Windows Management Instrumentation) e PowerShell sono usati spesso per scansionare una rete Windows dall'interno. Dopo aver scoperto altri sistemi, l'attaccante cerca vulnerabilità e le sfrutta se possibile. ==Sfruttando più sistemi, l'attaccante ha più probabilità di mantenere persistence nella rete==: se viene scoperto e bloccato su un host, gli restano gli altri.
| Tool | Espansione | Cosa fa |
|---|---|---|
| WMI | Windows Management Instrumentation | Interfaccia di gestione Windows per query e azioni da remoto (processi, servizi, file system) su altri host del dominio |
| PowerShell | - | Shell e linguaggio di scripting Windows; con le credenziali giuste esegue comandi su host remoti dello stesso dominio (PowerShell Remoting) |
Dev parallel: WMI/PowerShell Remoting per gestire una rete Windows dall'interno è l'equivalente Windows di SSH + Ansible per una flotta Linux — stesso pattern ("un host amministra molti altri host con credenziali"), legittimo quando lo fa l'IT, lateral movement quando lo fa un attaccante con credenziali rubate. È anche il motivo per cui riusare LA STESSA password admin su tutti i server è così pericoloso: un solo host compromesso (Initial Exploitation) diventa immediatamente un host da cui amministrare TUTTI gli altri. In cloud è uno dei pattern che un Cloud Security Engineer cerca nei VPC Flow Log — traffico interno inatteso da un host verso molti altri
Privilege Escalation#
In molti penetration test, il tester ottiene prima accesso a un sistema o account a BASSO privilegio. Esempio di Gibson: il tester ottiene accesso al computer di Homer usando l'account di Homer — Homer ha accesso alla rete, ma nessun privilegio amministrativo.
I tester usano poi varie tecniche per ottenere SEMPRE PIÙ privilegi sul computer di Homer e sulla sua rete — questa è la privilege escalation.
Il cap. 6 (Un Click Basta) descrive come le APT spesso usano i RAT per ottenere accesso a un singolo sistema: l'attaccante induce l'utente a cliccare un link malevolo, ottenendo accesso a quel computer. Da lì, gli attaccanti scansionano la rete cercando vulnerabilità e, sfruttandole, ottengono privilegi sempre maggiori sulla rete. ==I penetration tester usano tattiche simili — quanto in profondità possono spingersi dipende da cosa autorizzano le ROE==.
Dev parallel: questo è il punto di arrivo del forward link che avevi visto in #Credentialed vs. Non-Credentialed Scans — un credentialed scan parte già "dentro" con un account, esattamente il punto di partenza di Homer. I vettori di privilege escalation Linux che già conosci: bit SUID/SGID su binari mal configurati (un binario eseguito con i permessi del proprietario invece di chi lo lancia), sudo configurato troppo permissivo (
NOPASSWD: ALLsu comandi che permettono di leggere/scrivere file arbitrari). In ambito container — particolarmente rilevante ora che lavori al Docker lab — montare /var/run/docker.sock dentro un container equivale a dare a quel container privilege escalation immediata fino a root sull'host: chiunque controlli quel container controlla dockerd, e dockerd può lanciare container privilegiati che montano il filesystem dell'host.
Pivoting#
Il pivoting è il processo di usare vari tool per ottenere accesso a SISTEMI AGGIUNTIVI in una rete dopo una compromissione iniziale.
Esempio di Gibson: il tester ottiene accesso al computer di Homer nella rete aziendale. Può quindi fare pivot — usare il computer di Homer come ponte per raccogliere informazioni su altri computer. Magari Homer ha accesso a network share piene di file sulle operazioni di una centrale nucleare. Il tester usa il computer di Homer per raccogliere questi dati e poi spedirli FUORI dalla rete passando dal computer di Homer stesso.
==Spesso il tester deve prima usare tecniche di privilege escalation per ottenere più privilegi — solo dopo può accedere a database (account utente e password), email, e qualsiasi altro tipo di dato nella rete==.
Dev parallel: ==il pivoting è la versione "ostile" del Jump Server== che hai già visto. Un jump server legittimo è l'UNICO host con accesso SSH ai server interni — gli admin ci passano attraverso deliberatamente, ed è monitorato. Il pivoting sfrutta la STESSA proprietà di rete (reachability) su un host che non è pensato per essere un jump server: se il computer di Homer può raggiungere il network share delle "operazioni nucleari", e l'attaccante può raggiungere il computer di Homer, allora per transitività l'attaccante può raggiungere anche quel network share. È la logica con cui un Cloud Security Engineer disegna la segmentazione (VPC, Security Group, Network Policy in Kubernetes): non basta proteggere il perimetro, bisogna limitare cosa ogni singolo host PUÒ raggiungere internamente, così che un host compromesso non sia automaticamente un pivot verso tutto il resto.
Da ricordare: dopo l'initial exploitation (sfruttare una vulnerabilità per ottenere accesso), i penetration tester (e gli attaccanti) usano tecniche di privilege escalation per ottenere più accesso sui sistemi target. Il pivoting è il processo di usare un sistema sfruttato per colpirne altri — il lateral movement è il movimento stesso attraverso la rete che rende possibile il pivoting, e la persistence è ciò che permette di mantenere tutto questo accesso nel tempo senza essere scoperti. Sequenza logica: ==Initial Exploitation → Persistence → Privilege Escalation → Lateral Movement/Pivoting== — ogni fase rende la successiva più facile.
Known, Unknown, and Partially-Known Testing Environments#
mindmap
root((Testing
Environments))
Unknown
black box
fuzzing
Known
white box
source code access
Partially Known
gray box
partial documentation
Dev Parallel
unit integration e2e tests
E' comune classificare un test in base a quanta CONOSCENZA hanno i tester dell'ambiente prima di iniziare. I tester possono essere dipendenti interni o professionisti esterni di terze parti assunti per eseguire il test. Esistono tre tipi:
| Tipo | Anche chiamato | Conoscenza dei tester |
|---|---|---|
| Unknown environment testing | black box test | Zero conoscenza — stesso punto di partenza di un attaccante. Nessuna documentazione su rete/applicazione prima del test. Usano spesso fuzzing per trovare vulnerabilità applicative |
| Known environment testing | white box test | Conoscenza completa — documentazione del prodotto, codice sorgente, eventualmente credenziali di accesso |
| Partially known environment testing | gray box test | Conoscenza parziale — es. parte della documentazione di rete, ma non il layout completo |
Da ricordare: gli unknown environment tester non hanno conoscenza preliminare del sistema prima del penetration test. I known environment tester hanno conoscenza completa dell'ambiente, e i partially known environment tester hanno conoscenza parziale.
Dev parallel: black box / white box / gray box non sono termini nuovi per te — sono ESATTAMENTE i termini che usi nel testing software. Black box testing (E2E, API testing) = testi solo dall'esterno, senza guardare il codice, come un attaccante. White box testing (unit test con accesso al codice) = conosci l'implementazione interna, puoi testare ogni branch/edge case — qui includi anche il fuzzing già visto in Analyzing and Reviewing Code. Gray box = integration test dove conosci il contratto API ma non l'implementazione interna del servizio chiamato. ==La differenza è SOLO l'obiettivo==: in QA cerchi bug funzionali, in un pentest cerchi vulnerabilità — ma il framework "quanto sa il tester prima di iniziare" è identico.
Unit test (white box — testi una funzione isolata, sai esattamente cosa c'è dentro):
$result = (new TaxCalculator())->apply(100, 'IT');
$this->assertEquals(122, $result); // IVA 22% hardcoded, nessun DB/HTTP
Integration test (gray box — più pezzi insieme, es. servizio + DB reale, ma sai cosa c'è "dietro"):
$user = $userRepository->save(new User('barno@example.com'));
$this->assertNotNull($userRepository->find($user->getId())); // tocca il DB vero
E2E test (black box — dall'esterno, come un utente/attaccante, non sai/non ti interessa l'interno):
$response = $client->request('POST', '/login', ['email' => 'barno@example.com', 'password' => 'x']);
$this->assertResponseStatusCodeSame(200); // non sai se passa per DB, cache, etc.
Stessa scala black/white/gray box di cap-08-risk-management-tools#Known, Unknown, and Partially-Known Testing Environments: meno conosci l'interno, più ti comporti come chi sta "fuori".
Cleanup#
mindmap
root((Cleanup))
Remove Accounts
Remove Scripts and Apps
Remove Files and Logs
Restore Settings
Document While Doing
terraform destroy parallel
Il cleanup è uno degli ultimi step di un penetration test. Include la rimozione di TUTTE le tracce dell'attività del tester. Dipende ovviamente da cosa ha fatto il tester durante il test e da cosa prevedono le ROE. Attività di cleanup tipiche:
- rimuovere qualsiasi account utente creato sui sistemi della rete
- rimuovere script o applicazioni aggiunte/installate sui sistemi
- rimuovere file creati sui sistemi, come log o file temporanei
- riconfigurare tutte le impostazioni modificate dai tester durante il test
==Questa è una lista estesa, e i tester non dovrebbero fare affidamento sulla memoria==. E' comune invece che i tester creino un log di ciò che stanno facendo MENTRE lo fanno — questo rende più facile invertire (reverse) tutte le loro azioni.
Dev parallel: il cleanup è il "rollback" del penetration test. Hai appena visto in #Persistence che il tester crea backdoor/account per dimostrare la persistence — il cleanup è la rimozione di esattamente quelle cose. Stesso principio di una migration di database con il suo
down(): se non scrivi la migration inversa MENTRE scrivi quella in avanti, dopo è molto più difficile ricostruirla a memoria. È anche il motivo per cuiterraform destroyesiste come comando dedicato (vedi [[[TODO] lab-terraform-cloudflare-dns|lab-terraform-cloudflare-dns]]): la rimozione di una risorsa creata da codice è un'operazione di prima classe, non un "ricordami di toglierlo dopo". Lato Blue Team: una configuration review post-engagement (vedi #Configuration Review — drift detection) è il modo per VERIFICARE che il cleanup sia stato completo, indipendentemente dal log del tester.
Responsible Disclosure Programs#
mindmap
root((Responsible
Disclosure))
RD Program
coordinated reporting process
guidelines
contact point
response timelines
Bug Bounty Program
monetary rewards
public or invite only
SECURITY md
GitHub Security Advisories
I responsible disclosure (RD) program per le vulnerabilità permettono a individui e organizzazioni di segnalare vulnerabilità o debolezze di sicurezza che hanno scoperto alle parti appropriate. L'obiettivo della responsible disclosure è permettere che i problemi di sicurezza vengano risolti PRIMA che vengano sfruttati da attaccanti, migliorando la sicurezza generale per tutti.
I programmi RD tipicamente prevedono un processo coordinato per segnalare le vulnerabilità alle parti appropriate — vendor, sviluppatori o team di sicurezza. Questo processo solitamente include:
- linee guida su come segnalare una vulnerabilità
- un punto di contatto per la segnalazione
- aspettative sui tempi di risposta e risoluzione
Quando una vulnerabilità viene segnalata, l'organizzazione che la riceve è tenuta a investigare e, se necessario, adottare i passi appropriati per risolvere il problema.
I bug bounty program sono un tipo di RD program che incentiva individui o organizzazioni a segnalare vulnerabilità offrendo ricompense monetarie o di altro tipo per segnalazioni valide. Possono essere gestiti da organizzazioni per incoraggiare ricercatori esterni o hacker a segnalare vulnerabilità che i team interni potrebbero non notare. Alcuni bug bounty program sono pubblici, altri solo su invito: questo crea un modello crowdsourced di esperti che cercano vulnerabilità.
| Termine | Espansione | Cosa è |
|---|---|---|
| RD program | Responsible Disclosure program | Processo coordinato per segnalare vulnerabilità a vendor/dev/security team, con linee guida, contatto e timeline di risposta |
| Bug bounty program | - | Tipo di RD program che ricompensa (denaro o altro) chi segnala vulnerabilità valide — pubblico o su invito |
Da ricordare: ==un RD program definisce COME segnalare una vulnerabilità (contatto, linee guida, timeline) prima che diventi pubblica==. Un bug bounty program è un RD program che inoltre PAGA per le segnalazioni valide — è un sottoinsieme, non un sinonimo (stessa relazione "specifico dentro il generale" vista per footprinting/fingerprinting e per Trojan/RAT in cap-06).
Dev parallel: il bug bounty come "scope" lo avevi già visto in #Rules of Engagement (HackerOne, Bugcrowd). Qui la chiave è il PROCESSO, non lo scope: ogni repo open source serio ha un file
SECURITY.md(GitHub Security Advisories), che è esattamente un RD program in miniatura — dice a chi scrivere (non apri una issue pubblica!), che timeline aspettarti, e spesso un embargo period prima della disclosure pubblica via CVE. Quando una libreria che usi (npm, composer) riceve una CVE, quasi sempre è passata per questo processo: ricercatore → contatto privato → fix → CVE pubblicato (vedi CVE Program) — la disclosure pubblica arriva DOPO che la patch è disponibile, non prima.
System and Process Audits#
mindmap
root((System and
Process Audits))
Compared Against
Industry Standards
PCI DSS example
Best Practices
least privilege
Internal Policies
offboarding 24h
Techniques
Interviews
Document Review
System Scans
Real World
SOC 2 ISO 27001 audit
Gli system and process audit sono strumenti importanti per valutare quanto un'organizzazione sia conforme (compliant) a tre tipi di riferimento: ==standard di settore (industry standards), best practice e policy interne (internal policies)==. Un audit prevede tipicamente una revisione dei sistemi, dei processi e delle procedure dell'organizzazione per identificare aree di non-compliance, inefficienze o aree di rischio potenziale.
Durante l'audit, gli auditor raccolgono informazioni con tecniche diverse: ==interviste, revisione della documentazione (document review) e scan dei sistemi (system scans)==. Per questo un audit è anche una fonte preziosa di informazioni sulla security posture dell'organizzazione, incluse le vulnerabilità eventualmente presenti.
| Cosa confronta | Con cosa | Esempio |
|---|---|---|
| Stato reale dei sistemi/processi | Industry standards | "Usiamo TLS 1.2+ ovunque?" vs requisito PCI DSS |
| Stato reale dei sistemi/processi | Best practice | "Gli accessi seguono least privilege?" vs prassi consolidata del settore |
| Stato reale dei sistemi/processi | Internal policy | "L'offboarding avviene entro 24h?" vs la policy HR interna |
Dev parallel: è esattamente un audit SOC 2 o ISO 27001 - quello che un'agenzia come Futura Oltre può ricevere da un cliente enterprise. L'auditor fa interview ai dev ("come gestite gli accessi?"), document review (esiste una policy scritta di onboarding/offboarding?) e system scan (apre la console IAM di AWS/Azure e controlla DAVVERO chi ha accesso a cosa). Il gap tra "quello che dite di fare" (policy) e "quello che il system scan trova" è esattamente il finding dell'audit. Vedi anche Audit.
Da ricordare: ==un audit confronta lo stato REALE di sistemi/processi (raccolto via interviste, document review, system scan) con uno stato ATTESO (industry standards, best practice, internal policy), per trovare gap di compliance, inefficienze e rischi.==
Intrusive Versus Non-Intrusive Testing#
mindmap
root((Intrusive vs
Non-Intrusive))
Intrusive
Penetration Testing
can disrupt operations
attempts exploitation
Non-Intrusive
Vulnerability Scanning
safe in production
no exploitation attempt
Independent Axis
different from known unknown
composer audit vs DAST

==I penetration test sono intrusivi e più invasivi dei vulnerability scan==: comportano il probing di un sistema e il TENTATIVO di sfruttare ogni vulnerabilità scoperta. Se l'exploit riesce, un penetration test può interrompere i servizi e persino mettere KO un sistema.
==I vulnerability scan sono generalmente non intrusivi e meno invasivi dei penetration test==: gli scan standard NON tentano di sfruttare una vulnerabilità. Per questo un vulnerability scan è molto più sicuro da eseguire su un sistema o una rete - è significativamente meno probabile che impatti i servizi.
Dev parallel:
composer audit/npm audit/ un report Trivy (vedi #Risk Types) sono non intrusivi - leggono solo le versioni dei package installati e le confrontano con un database di CVE, zero rischio per l'app in esecuzione. Un test DAST1 che lancia DAVVERO un payload SQLi contro un endpoint, o un penetration test che prova l'exploit di #Initial Exploitation, è intrusivo - può far esplodere una query, riempire un log, o bloccare il servizio. Stesso principio diterraform plan(non intrusivo, sola lettura) vsterraform apply/destroy(intrusivo, modifica davvero l'infrastruttura) - vedi [[[TODO] lab-terraform-cloudflare-dns|lab-terraform-cloudflare-dns]].
Da ricordare: ==intrusivo/non intrusivo è un asse DIVERSO da known/unknown/partially-known==: il primo riguarda SE il test può rompere qualcosa (vulnerability scan = no, penetration test = sì), il secondo riguarda QUANTO il tester sa in anticipo (black/white/gray box). Un penetration test può benissimo essere sia black-box CHE intrusivo - sono due assi indipendenti, non livelli della stessa scala.
Responding to Vulnerabilities#
mindmap
root((Responding to
Vulnerabilities))
Remediation
primary response
Remediating Vulnerabilities
Validation
confirm it worked
Validation of Remediation
Remediating Vulnerabilities#
mindmap
root((Remediating
Vulnerabilities))
Patching
primary method
apply ASAP
No Patch Available
Compensating Control
WAF example
Segmentation
isolated network
Exception Exemption
only with other measures
Dev Parallel
EOL dependency
trivyignore allowlist
==Il metodo più comune per risolvere una vulnerabilità è il patching del sistema interessato==. Le patch software sono aggiornamenti che correggono vulnerabilità e altri difetti (flaw, vedi flaw) in un'applicazione. Quando i vendor scoprono una nuova vulnerabilità, progettano una patch per correggerla e la rilasciano ai clienti. ==Gli amministratori dovrebbero applicare le patch il prima possibile==.
A volte non esiste una patch disponibile: magari il vendor sta ancora lavorando al fix, oppure il sistema ha superato la sua data di supporto e il vendor non correggerà più il problema (vedi Legacy hardware/system e EOL). In quei casi i professionisti della sicurezza potrebbero decidere di fermare il sistema, ma non è sempre praticabile - le esigenze di business possono richiedere di continuare a operare un sistema vulnerabile. In quello scenario ci sono alcune opzioni:
| Opzione | Cosa fa | Esempio |
|---|---|---|
| Compensating control | Controllo secondario che impedisce lo sfruttamento della vulnerabilità | WAF (Web Application Firewall) davanti a un'app con una SQL injection nota |
| Segmentation | Isola il sistema su una rete separata, riducendo la possibilità che soggetti esterni lo raggiungano | Vedi Segmentazione come compensating control |
| Exception/exemption alla policy | Autorizza il sistema a continuare a operare nonostante violi la policy | Da usare SOLO insieme ad altre misure (segmentation, compensating control) |
==Concedere un'eccezione di policy e lasciare che un sistema vulnerabile continui a operare SENZA fare altro per affrontare il problema è molto rischioso==.
Dev parallel: è lo stesso scenario già visto in #Risk Types per le dipendenze EOL - se
composer update/npm update(= patching) non è possibile perché il package è abbandonato, le opzioni sono: WAF/compensating control davanti all'endpoint che usa quel package, isolare quel servizio in una subnet/VPC separata (segmentation), oppure un'entry in.trivyignore/allowlist diaudit-ci(= exception alla policy) - quest'ultima da sola è esattamente il "molto rischioso" di cui parla Gibson.
Da ricordare: ==patching = remediation primaria, applicata il prima possibile. Se non c'è patch: compensating control, segmentation, o exception/exemption alla policy - quest'ultima mai da sola.==
Validation of Remediation#
mindmap
root((Validation of
Remediation))
Rescan System
confirm fix worked
Update Reporting
inform stakeholders
Maintain Records
audit evidence
Dev Parallel
CI regression test
Trivy npm audit rerun
Dopo aver rimediato una vulnerabilità, bisogna confermare che le misure correttive funzionino e che la vulnerabilità non esista più. ==Il primo passo è il rescan del sistema interessato, per verificare che la vulnerabilità sia stata effettivamente risolta==. Si può poi aggiornare il vulnerability reporting per comunicare agli stakeholder che la vulnerabilità è stata affrontata. È importante mantenere un registro del lavoro svolto: questi record possono servire se vengono messi in discussione durante un security audit.
Dev parallel: è il "regression test" di sicurezza - dopo aver aggiornato una dipendenza vulnerabile (remediation), si rilancia la stessa pipeline CI con Trivy/
npm audit/composer audit(rescan) per confermare che quella CVE non compaia più nel report. Il commit/PR che ha fatto l'update, insieme al run CI verde, è il "record" che un auditor (vedi #System and Process Audits) chiederebbe come prova - document review che incontra system scan.
Da ricordare: ==dopo ogni remediation: rescan per confermare → aggiorna il reporting per gli stakeholder → mantieni i record per audit futuri.==
Capturing Network Traffic#
mindmap
root((Capturing
Network Traffic))
Packet Capture and Replay
Wireshark
full content visible
Triaging and Tcpdump
CLI capture
tcpreplay test IDS
NetFlow
metadata only
no payload
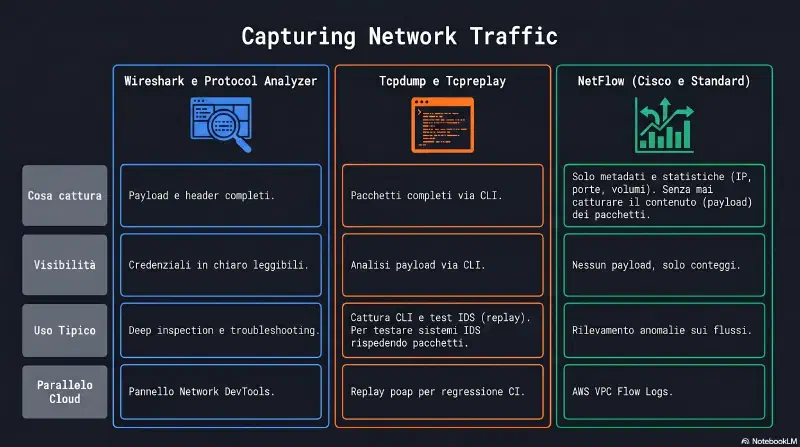
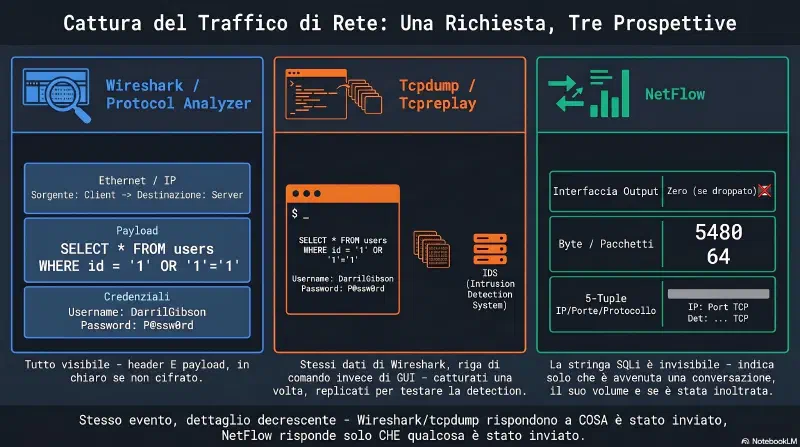
Packet Capture and Replay#
mindmap
root((Packet Capture
and Replay))
Protocol Analyzer
Wireshark sniffer
Admin Use
troubleshooting
manipulated fragmented packets
Attacker Use
cleartext credentials
rogue switch
SMB Example
username password visible
cleartext protocol
==Packet capture significa catturare i pacchetti che transitano sulla rete; packet replay significa rispedirli sulla rete==. Si fa con un protocol analyzer (chiamato anche sniffer): un tool che permette di analizzare e MODIFICARE header e payload dei pacchetti, tipicamente prima di rispedirli come replay.
Gli amministratori usano un protocol analyzer per fare troubleshooting di problemi di comunicazione tra sistemi, o per identificare potenziali attacchi individuando pacchetti manipolati o frammentati.
Gli attaccanti usano un protocol analyzer per catturare dati inviati in chiaro (cleartext) sulla rete - per esempio username e password non cifrati. Una tecnica comune: collegare uno switch non autorizzato (rogue switch) alla rete per inoltrare il traffico verso un sistema con un protocol analyzer. Se il cablaggio non è protetto, basta collegare quello switch sopra un controsoffitto.
Wireshark è un protocol analyzer gratuito, scaricabile da wireshark.org.
La figura sopra mostra l'output di Wireshark dopo aver catturato 155 pacchetti, con il pacchetto 121 selezionato nel pannello superiore. Il pannello superiore mostra IP sorgente/destinazione e il protocollo SMB2 (Server Message Block, espansione: vedi tabella sotto) - molte reti usano SMB per condividere file, e questo pacchetto contiene il contenuto di un file. Il pannello centrale mostra i dettagli del pacchetto, con l'header IPv4 parzialmente espanso. Il pannello inferiore mostra l'intero contenuto del pacchetto in esadecimale e ASCII.
Espandendo l'header IP si vedono gli indirizzi IP sorgente e destinazione (arrow 2); a volte gli attaccanti manipolano i flag negli header per vari tipi di attacco, e il protocol analyzer permette di verificare questi attacchi di manipolazione header (arrow 1). Espandendo la sezione Ethernet II si vedono i MAC address (Media Access Control) di sorgente e destinazione.
==Nel pannello inferiore sono visibili in chiaro username (DarrilGibson) e password (P@ssw0rd) (arrow 3), perché SMB invia username e password in cleartext==. Se l'applicazione avesse cifrato i dati prima di inviarli, non sarebbero leggibili.
| Acronimo | Espansione | Nota |
|---|---|---|
| SMB | Server Message Block | Protocollo Windows per condivisione file/cartelle in rete; invia credenziali in chiaro se non incapsulato in un canale cifrato |
| MAC | Media Access Control | Indirizzo fisico della scheda di rete, livello 2 (Ethernet) |
Dev parallel: la "versione web" di questo è il pannello Network delle DevTools del browser - vedi richieste/risposte HTTP, header, payload, in tempo reale. La differenza è che le DevTools mostrano il traffico GIÀ decifrato (dopo che il browser ha terminato TLS), mentre Wireshark/tcpdump vedono i byte SUL FILO - se la connessione è HTTPS, il payload nel pcap è cifrato e illeggibile (vedi SSL vs TLS). Il caso SMB di Gibson è esattamente lo scenario "nessuna cifratura a livello di trasporto": qualunque protocollo che manda credenziali in chiaro (HTTP semplice, FTP, Telnet, e qui SMB) è leggibile da chiunque possa catturare il traffico - per questo "tutto su HTTPS" non è un dettaglio, è IL controllo che rende inutile la cattura del pacchetto.
Da ricordare: ==gli amministratori usano un protocol analyzer per catturare, visualizzare e analizzare i pacchetti inviati su una rete. È utile per il troubleshooting di problemi di comunicazione tra sistemi, e per rilevare attacchi che manipolano o frammentano i pacchetti.== Per farlo con le tue mani su traffico reale (incluso un payload SQLi che attraversa la DMZ), vedi [[[IN PROGRESS] lab-dmz-logs-correlation#Parte 5 — Cattura con tcpdump/Wireshark|Parte 5 del lab DMZ]].
Triaging and Tcpdump#
mindmap
root((Triaging and
Tcpdump))
Tcpreplay
edit and resend packets
prove IDS detects attacks
Tcpdump
CLI protocol analyzer
pcap format
Case Sensitivity
lowercase c packet count
uppercase C file size rotation
Tcpreplay è una suite di utility (tcpreplay, tcpprep, tcprewrite e altre) che permette di editare pacchetti catturati e rispedirli sulla rete. Si usa spesso per testare dispositivi di rete: un amministratore può modificare pacchetti per imitare attacchi noti e mandarli a un IDS (Intrusion Detection System). Idealmente, un IDS dovrebbe SEMPRE rilevare un attacco noto e generare un alert - con tcpreplay, gli amministratori possono ==PROVARE== concretamente che l'IDS rileva attacchi specifici.
tcpdump è un protocol analyzer da riga di comando: permette di catturare pacchetti come fa Wireshark, ma da CLI invece che da interfaccia grafica. Molti amministratori usano tcpdump per catturare il traffico e poi Wireshark per analizzarlo - stesso formato file (pcap), strumenti diversi per fasi diverse.
Kali include tcpdump. ==tcpdump è case-sensitive==: il comando va scritto in minuscolo, e anche gli switch hanno maiuscole/minuscole significative.
| Switch | Significato | Comportamento |
|---|---|---|
-c (minuscola) | count | Indica il numero di pacchetti dopo il quale la cattura si ferma |
-C (maiuscola) | file size | Dimensione massima del file (in milioni di byte) - al raggiungimento, tcpdump chiude il file e ne apre uno nuovo |
Dev parallel: rispedire lo STESSO payload più volte per verificare che un security control lo blocchi sempre è esattamente quello che fai in [[[IN PROGRESS] lab-dmz-logs-correlation#Parte 2 — WAF: ModSecurity + OWASP CRS davanti a nginx|Parte 2 del lab DMZ]] con la richiesta SQLi contro ModSecurity - tcpreplay automatizza la stessa idea a livello di pacchetti raw invece che di richieste HTTP. E
tcpdump -w file.pcapsu Ubuntu (headless) seguito da analisi in Wireshark sul Mac è letteralmente [[[IN PROGRESS] lab-dmz-logs-correlation#Parte 5 — Cattura con tcpdump/Wireshark|Parte 5 del lab DMZ]].
Dev parallel: questo è anche l'esempio più concreto del caso d'uso "PROVARE che l'IDS rileva un attacco noto" di Gibson - il pcap della richiesta SQLi salvato in [[[IN PROGRESS] lab-dmz-logs-correlation#Parte 5 — Cattura con tcpdump/Wireshark|Parte 5 del lab DMZ]] è esattamente il "pacchetto che mima un attacco noto" da rispedire con tcpreplay. Quando Suricata sarà operativo (Mustache Fase 3-4, vedi Suricata — IDS passivo), questo stesso pcap diventa il test di regressione per la regola che deve far scattare l'alert: rispedisci il pcap con tcpreplay, e se Suricata NON genera l'alert, la regola (o Suricata stesso) ha un problema - lo stesso principio di #Validation of Remediation applicato a un IDS invece che a una vulnerabilità.
Da ricordare: ==-c minuscola = numero di pacchetti, -C maiuscola = dimensione file con rotazione automatica - case sensitivity è materiale d'esame.== tcpreplay serve a PROVARE che un IDS rileva davvero attacchi noti, rispedendo pacchetti che imitano l'attacco.
NetFlow#
mindmap
root((NetFlow))
Collector
router switch statistics
No Payload
metadata only
timestamps interfaces
source destination IP port
packet byte counts
Output Interface Zero
packet dropped
Dev Parallel
AWS VPC Flow Logs
anomaly detection
NetFlow è una funzionalità disponibile su molti router e switch che raccoglie statistiche sul traffico IP e le invia a un NetFlow collector. Il collector riceve e archivia i dati, e un software di analisi sul collector permette agli amministratori di visualizzare e analizzare l'attività di rete.
==La differenza fondamentale rispetto a un protocol analyzer (Wireshark/tcpdump) è che NetFlow NON include il payload e NON include nemmeno i singoli header di pacchetto==: un record NetFlow mostra solo conteggi e statistiche relative ai dati che un device riceve - è metadato, non contenuto.
NetFlow usa dei template per definire quali dati includere, ma tipicamente un record contiene:
| Campo | Cosa indica |
|---|---|
| Timestamp inizio/fine | Durata del flow |
| Interfaccia di input | Su quale interfaccia del router/switch è arrivato il traffico |
| Interfaccia di output | Su quale interfaccia è uscito - zero se il pacchetto è stato droppato |
| Source IP + porta | Mittente |
| Destination IP + porta | Destinatario |
| Packet count / byte count | Volume del flow |
| Protocollo | TCP, UDP, ICMP o altro protocollo di livello 3 |
Cisco ha creato NetFlow, ma altri vendor lo hanno adottato.
Dev parallel: NetFlow è l'equivalente "on-prem/hardware" delle AWS VPC Flow Logs, già citate in #Lateral Movement per il pattern "un host che genera traffico interno insolito verso molti altri host" (segnale di lateral movement). Stesso principio: un Flow Log non mostra il CONTENUTO delle richieste - niente query SQL, niente header HTTP, niente payload - solo 5-tuple (IP/porta sorgente e destinazione, protocollo) + bytes/packets + ACTION (ACCEPT/REJECT, equivalente all'"interfaccia di output = zero" di NetFlow quando il traffico è droppato). Per questo un Cloud Security Engineer usa i Flow Log per anomaly detection (volumi e pattern insoliti), ma deve affidarsi ai log applicativi o a un pcap (vedi #Packet Capture and Replay) per capire COSA c'era davvero dentro quel traffico.
Da ricordare: ==NetFlow ≠ packet capture: solo metadati/statistiche di flusso (chi, quando, quanto, quale protocollo, accettato o droppato), MAI il payload.== Per vedere in pratica la differenza tra "leggere un pcap completo" e "leggere solo i metadati di un flusso", torna a [[[IN PROGRESS] lab-dmz-logs-correlation#Per andare oltre (opzionale)|lab-dmz-logs-correlation]] dopo aver completato il lab.
Understanding Frameworks and Standards#
mindmap
root((Frameworks
and Standards))
ISO Standards
27001 27002
27701 31000
Industry Specific
PCI DSS
CIS Benchmarks
NIST Frameworks
RMF
CSF
Reference Architecture
design standards
Benchmarks and Guides
role based configuration
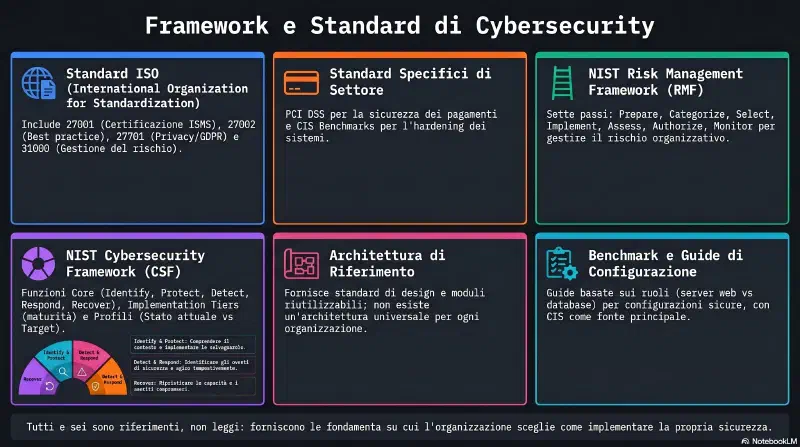
Dev parallel: ==è un significato diverso da "framework" in senso Symfony/Laravel/React==. Un framework software ti dà CODICE pronto all'uso - routing, DI container, ORM: lo installi e lui FA delle cose per te. Un framework di cybersecurity (NIST CSF, RMF, ISO 27001...) non installa niente e non fa niente da solo: è un documento che ti dà una STRUTTURA CONCETTUALE - categorie, processi, checklist - per organizzare il TUO programma di sicurezza e capire se manca qualcosa. Il punto in comune è solo "fondamenta su cui costruire invece di partire da zero": Symfony ti dà fondamenta di CODICE, NIST CSF ti dà fondamenta di PROCESSO. I controlli tecnici veri e propri (WAF, IAM, SIEM, firewall - le cose che hai effettivamente implementato nel [[[IN PROGRESS] lab-dmz-logs-correlation|lab DMZ]]) il framework non te li fornisce: ti dice in quale categoria (Identify/Protect/Detect/Respond/Recover, vedi #NIST Cybersecurity Framework) li devi collocare e se la copertura è completa. Hook: ==un framework software è una cassetta degli attrezzi (ti dà gli strumenti), un framework di cybersecurity è una direttiva (ti dice cosa fare e come organizzarlo - gli strumenti li scegli e li implementi tu)==.
ISO Standards#
mindmap
root((ISO
Standards))
27001
ISMS requirements
certification
27002
best practice guidance
27701
PIMS privacy PII
GDPR alignment
31000
risk management family
Paid Standard
not free unlike NIST
La ISO (International Organization for Standardization) è un'organizzazione indipendente che stabilisce standard per un'ampia varietà di applicazioni industriali e commerciali; alcuni riguardano direttamente la cybersecurity. ==A differenza dei documenti NIST, che sono tutti gratuiti, i documenti ISO NON sono gratuiti - vanno acquistati online==.
| Standard | Espansione | Cosa fa |
|---|---|---|
| ISO 27001 | Information Security Management Systems | Definisce i requisiti per un ISMS (Information Security Management System). Le organizzazioni che li implementano possono ottenere la certificazione ISO 27001 tramite un processo a tre stadi |
| ISO 27002 | Information security, cybersecurity and privacy protection - Information security controls | Complemento a ISO 27001: mentre la 27001 definisce i requisiti per la certificazione, la 27002 fornisce linee guida di best practice |
| ISO 27701 | Privacy Information Management System (PIMS) | Estensione a ISO 27001/27002: framework per gestire e proteggere le PII (Personally Identifiable Information). Aiuta a rispettare standard di privacy globali come il GDPR |
| ISO 31000 | Risk management | Famiglia di standard sulla gestione del rischio: linee guida che le organizzazioni possono adottare per gestire il rischio |
Dev parallel: questo è il framework dietro l'audit SOC2/ISO27001 già discusso in #System and Process Audits - ISO 27001 è lo STANDARD contro cui un auditor confronta lo stato reale di Futura Oltre, ISO 27002 è il "manuale delle best practice" che spiega COME implementare quei requisiti. ISO 27701 è la parte che riguarda specificamente i dati personali (PII) dei clienti - lo stesso GDPR già visto in Compliance Frameworks.
Da ricordare: ==ISO 27001 = requisiti per la certificazione, ISO 27002 = best practice di supporto, ISO 27701 = estensione privacy/PII (GDPR), ISO 31000 = risk management. Documenti ISO a pagamento, documenti NIST gratuiti.==
Industry-Specific Frameworks#
mindmap
root((Industry Specific
Frameworks))
PCI DSS
payment card industry
12 core requirements
CIS
Center for Internet Security
CIS Benchmarks
Dev Parallel
Stripe PayPal SAQ
Alcuni framework e standard si applicano solo a settori specifici.
| Framework | Espansione | Ambito |
|---|---|---|
| PCI DSS | Payment Card Industry Data Security Standard | Le organizzazioni che gestiscono carte di credito tipicamente si conformano al PCI DSS: include 12 requisiti principali più requisiti aggiuntivi per diversi tipi di entità, per proteggere i dati delle carte di credito. Non è infallibile, ma ha contribuito a ridurre molti dei rischi legati alle frodi con carta |
| CIS | Center for Internet Security | Organizzazione con la missione di "rendere il mondo connesso un posto più sicuro" sviluppando, validando e promuovendo soluzioni di best practice. Offre diversi download gratuiti di best practice e mantiene informazioni aggiornate sulle minacce. I membri includono aziende, agenzie governative e istituzioni accademiche, con accesso a risorse aggiuntive |
Dev parallel: PCI DSS è quello che entra in gioco ogni volta che un cliente Futura Oltre integra Stripe/PayPal/un gateway di pagamento - anche se il provider gestisce i dati della carta, il merchant compila comunque un SAQ (Self-Assessment Questionnaire) PCI DSS. CIS invece è il nome che vedrai di nuovo subito: i CIS Benchmark sono le guide di hardening per OS e applicazioni già citate in Hardening Workstations and Servers e nella Configuration Review di questo capitolo - vengono approfonditi in #Benchmarks and Configuration Guides, poco più avanti.
NIST Frameworks#
mindmap
root((NIST
Frameworks))
Risk Management Framework
RMF
Cybersecurity Framework
CSF
Il NIST (National Institute of Standards and Technology) pubblica due framework importanti, ampiamente usati dai professionisti di risk management e cybersecurity, e ampiamente rispettati nel settore: il Risk Management Framework (RMF) e il Cybersecurity Framework (CSF).
NIST Risk Management Framework#
mindmap
root((NIST RMF
SP 800-37))
7 Steps
Prepare
roles and tolerance
Categorize
CIA impact
Select
choose controls
Implement
apply controls
Assess
verify effectiveness
Authorize
senior official decision
Monitor
continuous step
Mandatory
US federal agencies
adopted by private orgs too
NIST SP 800-37, "Risk Management Framework for Information Systems and Organizations", copre l'RMF. ==Le agenzie federali USA devono adottare l'RMF, ma molte organizzazioni private lo adottano comunque==. L'RMF fornisce un processo in sette passi per identificare e mitigare i rischi:
| # | Step | Cosa succede |
|---|---|---|
| 1 | Prepare | L'organizzazione identifica i ruoli chiave per implementare il framework, identifica strategie di risk tolerance, aggiorna (o crea) i risk assessment, identifica i controlli già in essere e crea una strategia di continuous monitoring |
| 2 | Categorize | Si determina l'impatto negativo su operazioni e asset in caso di perdita di confidenzialità, integrità e disponibilità (CIA) - per prioritizzare i sistemi |
| 3 | Select | Si selezionano e personalizzano i controlli necessari, tipicamente partendo da baseline e poi adattandole |
| 4 | Implement | Si implementano i controlli selezionati; eventuali modifiche vengono documentate |
| 5 | Assess | Si verifica che i controlli producano il risultato desiderato, incluso che siano implementati correttamente e funzionino come previsto |
| 6 | Authorize | Un funzionario senior decide se il sistema è autorizzato a operare, basandosi sull'output degli step precedenti. Le agenzie governative danno a questo step più peso delle organizzazioni private |
| 7 | Monitor | Step continuo: si valutano costantemente i cambiamenti nel sistema e nell'ambiente, tipicamente con risk assessment periodici e analisi delle risposte al rischio |
Dev parallel: i sette step mappano bene su come un'organizzazione gestisce la sicurezza nel tempo. Prepare = definire policy, risk tolerance e strategia di monitoring (le basi che Futura Oltre definisce una volta). Categorize = classificare i sistemi per impatto CIA - un'app che gestisce PII dei clienti ha un impatto "confidenzialità" alto, una landing page statica no. Select/Implement = scegliere e applicare i controlli - es. decidere ed eseguire le regole firewall/WAF del [[[IN PROGRESS] lab-dmz-logs-correlation|lab DMZ]]. Assess = verificare che funzionino davvero - lo stesso principio di #Validation of Remediation (rescan dopo la remediation). Authorize = la decisione "andiamo in produzione" da parte del management. Monitor = lo step continuo, ed è esattamente #Capturing Network Traffic: log, pcap, firewall log, WAF log che generi e leggi continuamente, non una volta sola.
Da ricordare: ==RMF = NIST SP 800-37, 7 step (Prepare, Categorize, Select, Implement, Assess, Authorize, Monitor), obbligatorio per le agenzie federali USA, adottato anche da privati.==
NIST Cybersecurity Framework#
mindmap
root((NIST CSF))
Core
Identify Protect
Detect Respond Recover
mnemonic IPDRR
Tiers
Partial to Adaptive
maturity 1 to 4
Profile
Current Profile
Target Profile
gap analysis
Il Cybersecurity Framework (CSF) si allinea con l'RMF. Molte organizzazioni private lo hanno adottato per migliorare la propria capacità di prevenire, rilevare e rispondere ai cyberattacchi. Il CSF include tre componenti:
| Componente | Descrizione |
|---|---|
| Core | Un insieme di attività che un'organizzazione può selezionare per raggiungere determinati obiettivi. Include cinque funzioni: Identify, Protect, Detect, Respond, Recover |
| Tiers | Aiutano un'organizzazione a capire come vede il rischio. Quattro livelli: Partial (Tier 1), Risk Informed (Tier 2), Repeatable (Tier 3), Adaptive (Tier 4) - Tier 4 è il più alto, indica un programma di risk management maturo |
| Profile | Forniscono una lista di obiettivi basati sui bisogni e i risk assessment dell'organizzazione. I Current Profile descrivono lo stato attuale delle attività di cybersecurity, i Target Profile descrivono gli obiettivi desiderati. Confrontando Current e Target Profile, un'organizzazione identifica i gap nel proprio programma di risk management. Si possono usare profili diversi per sistemi diversi in base al loro valore |
==Le cinque funzioni del Core (Identify, Protect, Detect, Respond, Recover - mnemonico "IPDRR") sono il dettaglio più richiesto all'esame su questo framework.==
Dev parallel: le cinque funzioni del Core mappano sul lavoro quotidiano. Identify = inventario asset/dipendenze (il tuo
composer.lock/package-lock.json, l'inventario delle istanze cloud). Protect = hardening, WAF, IAM - i controlli che hai implementato (RMF step "Implement"). Detect = i log e il pcap di #Capturing Network Traffic - lo stesso "capire bene tutto" del [[[IN PROGRESS] lab-dmz-logs-correlation|lab DMZ]]. Respond = il runbook di incident response. Recover = backup e disaster recovery. E il confronto Current Profile vs Target Profile è ESATTAMENTE la gap analysis che vedrai in #Audits and Assessments, qui applicata in chiave "dove siamo vs dove vogliamo essere" invece che "standard vs realtà".
Da ricordare: ==CSF = Core (5 funzioni: Identify, Protect, Detect, Respond, Recover) + Tiers (1-4, maturità) + Profile (Current vs Target → gap).==
Reference Architecture#
mindmap
root((Reference
Architecture))
Design Standards
reusable modules
interface conventions
No Universal Architecture
adopted per project
Dev Parallel
architecture decision record
Symfony conventions
In cybersecurity, una reference architecture è un documento (o un insieme di documenti) che fornisce un set di standard. Per esempio, una software reference architecture documenta decisioni di design ad alto livello: può imporre la creazione di moduli riutilizzabili e il rispetto di uno standard specifico per le interfacce, e può elencare procedure, funzioni e metodi che un progetto software dovrebbe usare.
==Non esiste UNA reference architecture che vada bene per tutti i progetti== - il punto è che i progetti complessi spesso ne adottano una per standardizzare il lavoro di tutti.
Dev parallel: è esattamente quello che in un team dev si chiama "architecture decision record" o "linee guida interne" - le convenzioni Symfony di Futura Oltre (struttura dei bundle, convenzioni di naming, layer dei servizi, come si scrive un controller) sono una reference architecture in piccolo: nessun team esterno DEVE seguirla, ma chi lavora su QUEL progetto la segue per restare coerente con tutto il resto.
Benchmarks and Configuration Guides#
mindmap
root((Benchmarks and
Configuration Guides))
Role Based Guides
web server
ports 80 443
database server
ports closed
CIS Benchmarks
hardening standards
Dev Parallel
docker compose ports
firewall rules per role
Oltre ai framework, si possono usare varie guide per aumentare la sicurezza: benchmark o guide di configurazione sicura, guide specifiche per piattaforma/vendor, e guide general-purpose. In apparenza è semplice: per configurare sistemi Windows, usa una guida Windows; per configurare sistemi Linux, usa una guida Linux.
Inoltre, quando configuri un sistema con un ruolo specifico (web server, application server, dispositivo di rete), segui la guida appropriata per quel ruolo. Per esempio, ==un web server ha bisogno delle porte 80 e 443 aperte per HTTP e HTTPS==. Un database application server invece tipicamente NON ha bisogno di queste porte aperte, quindi dovrebbero essere chiuse. Le guide per ciascun ruolo forniscono questa informazione.
Dev parallel: questo è il punto in cui i CIS Benchmark citati in #Industry-Specific Frameworks diventano concreti, e chiude il cerchio con la Configuration Review di questo capitolo, dove un configuration compliance scanner confronta lo stato reale con esattamente questo tipo di baseline. È anche il principio dietro le regole firewall del [[[IN PROGRESS] lab-dmz-logs-correlation|lab DMZ]]:
ns-fw1accetta solo le porte 80/443 versons-sofia(ruolo: web server),ns-fw2accetta solo la porta 3306 versons-giulia(ruolo: database) - e SOLO dans-sofia, non da chiunque. In undocker-compose.yml, lo stesso principio si traduce in: il container web espone 80/443, il container database NON espone 3306 sull'host - se un servizio non ha bisogno di essere raggiungibile dall'esterno, la porta non va pubblicata, vedi anche segmentation.
Da ricordare: ==configura ogni sistema in base al suo RUOLO, non con una configurazione generica uguale per tutti - una guida/benchmark per ruolo (web, DB, rete) ti dice quali porte/servizi servono davvero.==
Audits and Assessments#
mindmap
root((Audits and
Assessments))
Audit
formal independent
External Audit
Internal Audit
produces attestation
Assessment
less formal
vuln scan pen test
Gap Analysis
standard vs reality
ISO 27001 example
Dev Parallel
SOC 2 Type II
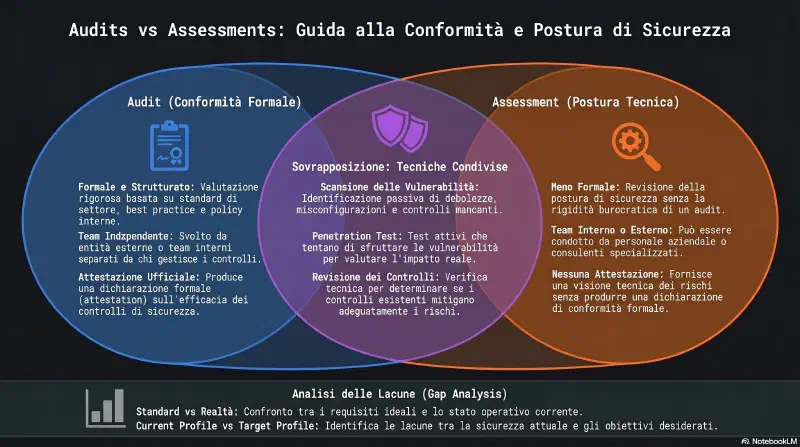
Gli audit sono una valutazione formale delle policy, delle procedure e delle operazioni di un'organizzazione. In cybersecurity, un audit confronta che l'organizzazione abbia messo in atto controlli di sicurezza adeguati ed efficaci nel proteggere gli asset critici (lo stesso framework "stato reale vs stato atteso" già visto in #System and Process Audits).
Gli assessment sono revisioni meno formali della postura di cybersecurity di un'organizzazione: possono includere vulnerability scan, penetration test e review dei controlli di cybersecurity - molte delle tecniche usate in un assessment possono avere un ruolo anche in un audit. Gli assessment possono essere svolti da gruppi diversi: l'organizzazione può assumere una società esterna con competenze specifiche, oppure chiedere al proprio team di cybersecurity di svolgerli internamente.
==Gli audit sono più formali e strutturati degli assessment, e vengono svolti da un team INDIPENDENTE rispetto a chi ha implementato i controlli==. Esistono due categorie principali di audit:
| Tipo | Chi lo svolge | A chi vanno i risultati |
|---|---|---|
| External audit | Una società di auditing indipendente esterna all'organizzazione | Comitato audit del Board, regolatori, altri stakeholder |
| Internal audit | Un team di audit interno all'organizzazione, che opera sotto la direzione del comitato audit del Board | Il Board stesso, per garantire la conformità a regolamenti e svolgere self-assessment |
Molte organizzazioni si sottopongono a un audit finanziario annuale per obbligo di legge, e i controlli di cybersecurity sono ormai una componente standard di quell'audit (external). Uno dei task più comuni assegnati a un gruppo di internal audit è la gap analysis: si prende uno standard (es. ISO 27001) e si confrontano i suoi requisiti con le operazioni normali dell'organizzazione, annotando gli eventuali gap come opportunità di miglioramento - è lo stesso confronto Current Profile vs Target Profile già visto in #NIST Cybersecurity Framework.
Il risultato di un audit è un'attestation: una dichiarazione formale che specifici controlli e processi di sicurezza sono in atto e operano efficacemente nell'organizzazione. ==È una dichiarazione significativa, perché la società di auditing ci mette in gioco la propria reputazione==.
Dev parallel: un SOC 2 Type II è l'external audit per eccellenza nel mondo SaaS/dev - una società di revisione indipendente verifica per un periodo di tempo (non solo "in questo momento") che i controlli di Futura Oltre (o di un cliente) funzionino davvero, e il report finale È l'attestation che viene mostrato ai clienti enterprise durante la vendita ("siamo SOC 2 compliant"). Una revisione di sicurezza interna prima di un rilascio importante, fatta dal tuo stesso team, è invece un internal assessment: meno formale, nessuna attestation esterna, ma utilissima per trovare problemi PRIMA che li trovi un auditor esterno.
Da ricordare: ==audit = formale, strutturato, team indipendente, produce un'attestation. Assessment = meno formale, può essere interno o esterno, niente attestation formale. Gap analysis = confronto standard vs realtà, lo stesso principio di Current vs Target Profile.==
Exam Topic Review#
Ripasso rapido di tutto il capitolo, organizzato sui 5 macro-argomenti di Gibson. Ogni punto rimanda alla sezione dettagliata se serve approfondire.
Understanding Risk Management#
- Risk = probabilità che una threat sfrutti una vulnerability. Threat = pericolo potenziale per C/I/A (confidentiality, integrity, availability). Vulnerability = debolezza in software, hardware o processo che una threat può sfruttare.
- Un rischio si valuta su due assi: impact (quanto danno fa se si verifica) e probability/likelihood (quanto spesso ci aspettiamo che si verifichi) - vedi #Probabilità e impatto: le due dimensioni del rischio.
- Il risk management riduce il rischio a un livello accettabile per l'organizzazione; quello che resta è il residual risk. ==Il senior management è responsabile della gestione del rischio e delle perdite legate al residual risk== - vedi #Il rischio non si può eliminare.
- 4 strategie verso un rischio: avoid (non offrire il servizio/non fare l'attività rischiosa), transfer (es. assicurazione), mitigate (controlli di sicurezza che riducono il rischio), accept (quando il costo del controllo supera il rischio) - vedi #Risk Management Strategies.
- Risk appetite = quanto rischio l'organizzazione è disposta ad accettare in base ai suoi obiettivi strategici (expansionary, conservative, neutral). Risk tolerance = capacità dell'organizzazione di sopportare il rischio.
- Un risk assessment quantifica o qualifica i rischi, partendo dall'identificazione degli asset e dalla loro priorità.
- ==Quantitative risk assessment==: AV (Asset Value) → EF (Exposure Factor, % di danno per occorrenza) → SLE = AV × EF (costo di una singola occorrenza) → ARO (Annual Rate of Occurrence) → ALE = SLE × ARO (costo annuo atteso). Formula chiave, spesso testata con numeri - vedi #Quantitative Risk Assessment.
- Qualitative risk assessment: giudizi soggettivi su likelihood e impact, senza numeri precisi - vedi #Qualitative Risk Assessment.
- I risk assessment report sono sensibili: accesso limitato a executive e security professional.
- Risk register = documento che elenca i rischi con score e controlli raccomandati. Risk matrix = grafico che plotta i rischi - vedi #Risk Reporting.
- Un supply chain assessment valuta l'intera catena (materie prime, hardware provider, software provider, service provider) necessaria a produrre e distribuire un prodotto - vedi #Supply Chain Risks.
Comparing Scanning and Testing Tools#
- Port scanner: trova le porte aperte e cosa gira su quelle porte - vedi #Network Scanners.
- Vulnerability scanner: testa i controlli di sicurezza per trovare vulnerabilità, controlli mancanti e misconfigurazioni - SENZA sfruttarle - vedi #Vulnerability Scanning.
- CVE (Common Vulnerabilities and Exposures) = dizionario di vulnerabilità pubbliche note. CVSS (Common Vulnerability Scoring System) = punteggio di severità da 0 a 10 (10 = più severo). ==CVE identifica COSA, CVSS dice QUANTO è grave==.
- False positive: lo scanner segnala una vulnerabilità che NON esiste. False negative: la vulnerabilità ESISTE ma lo scanner NON la rileva (il caso peggiore).
- Le vulnerabilità si prioritizzano su: classificazione, variabili ambientali, impatto su industry/organizzazione, risk tolerance/threshold.
- Credentialed scan: gira con le credenziali di un account, vede le versioni esatte del software installato, più accurato e meno falsi positivi del non-credentialed scan - vedi #Credentialed vs. Non-Credentialed Scans.
- Penetration test: test ATTIVO che tenta di sfruttare le vulnerabilità trovate, partendo da un vulnerability scan. Obiettivi: physical, offensive, defensive, o integrated - vedi #Penetration Testing.
- Serve sempre il consenso prima di un pen test; le Rules of Engagement (RoE) ne definiscono i confini - vedi #Rules of Engagement.
- Passive reconnaissance = OSINT, nessun contatto diretto col target. Active reconnaissance = scanning diretto - vedi #Reconnaissance e #Footprinting Versus Fingerprinting.
- Dopo l'exploitation iniziale: privilege escalation (più privilegi sullo stesso sistema) e pivoting (usare il sistema compromesso per raggiungere altri sistemi) - vedi #Privilege Escalation e #Pivoting.
- Unknown environment (black box): zero conoscenza preventiva. Known environment (white box): conoscenza completa, incluso codice sorgente. Partially known (gray box): conoscenza parziale - vedi #Known, Unknown, and Partially-Known Testing Environments.
- ==Intrusive (= invasive) = pen testing, può disturbare le operazioni. Non-intrusive (= non-invasive) = vulnerability testing, sicuro anche in produzione== - vedi #Intrusive Versus Non-Intrusive Testing.
- I responsible disclosure program offrono un canale per segnalare vulnerabilità trovate. I bug bounty sono un tipo di responsible disclosure che premia (anche economicamente) le segnalazioni valide - vedi #Responsible Disclosure Programs.
- La remediation più comune è la patch. Se non è possibile: compensating control, segmentation, o exception alla policy. Dopo la remediation, sempre un rescan per validare - vedi #Remediating Vulnerabilities e #Validation of Remediation.
Capturing Network Traffic#
- Un protocol analyzer (sniffer) cattura e analizza il traffico di rete. Tester e attaccanti lo usano per catturare dati in cleartext - vedi #Packet Capture and Replay.
- Gli admin lo usano per troubleshooting: ispezionano gli header dei protocolli per trovare pacchetti manipolati o frammentati.
- Un pacchetto catturato mostra: tipo di traffico (protocollo), IP e MAC sorgente/destinazione, e flag.
- Tcpreplay: suite per editare e rispedire packet capture sulla rete. Tcpdump: protocol analyzer da CLI. Wireshark: protocol analyzer grafico - vedi #Triaging and Tcpdump.
- NetFlow raccoglie statistiche sul traffico IP su router/switch e le invia a un NetFlow collector - vedi #NetFlow.
Understanding Frameworks and Standards#
- Un framework è un riferimento che fornisce una base. I framework di cybersecurity definiscono concetti di base e linee guida su COME implementare la sicurezza - non sono tool, sono direttive - vedi #Understanding Frameworks and Standards.
- ISO: 27001 (information security management/ISMS), 27002 (information security techniques), 27701 (privacy/PIMS, GDPR), 31000 (risk management) - vedi #ISO Standards.
- Chi gestisce carte di credito segue PCI DSS (Payment Card Industry Data Security Standard) - vedi #Industry-Specific Frameworks.
- NIST pubblica il RMF (Risk Management Framework) e il CSF (Cybersecurity Framework) - vedi #NIST Risk Management Framework e #NIST Cybersecurity Framework.
- Per configurare sistemi specifici si usano le vendor-specific guide - vedi #Benchmarks and Configuration Guides.
Audits and Assessments#
- Audit = valutazione formale di policy, procedure e operazioni: confermano che i controlli di sicurezza sono adeguati ed efficaci. Assessment = review meno formali (vuln scan, pen test, review dei controlli) - le stesse tecniche possono comparire dentro un audit, ma non sono la stessa cosa - vedi #Audits and Assessments.
- External audit = svolto da una società indipendente esterna. Internal audit = svolto da un team interno all'organizzazione.
- L'output di un audit è un'attestation: dichiarazione formale che specifici controlli e processi sono in atto e operano efficacemente.
Trappole d'esame — Cap 8#
False positive vs false negative — trigger: "scan reports a vulnerability that..." vs "scan misses a vulnerability that..." False positive = lo scanner segnala una vulnerabilità che NON esiste (falso allarme, fastidioso ma sicuro). False negative = la vulnerabilità ESISTE ma lo scanner NON la rileva (il caso peggiore - pensi di essere al sicuro e non lo sei).
SLE/ALE — trigger: domande con numeri e "annual loss" vs "cost of a single occurrence" SLE (Single Loss Expectancy) = AV × EF → costo di UNA singola occorrenza. ALE (Annual Loss Expectancy) = SLE × ARO → costo annuo atteso. "Quanto perdo in UN evento" = SLE. "Quanto perdo in UN ANNO" = ALE.
CVE vs CVSS — trigger: "identifier for a known vulnerability" vs "severity score from 0 to 10" CVE = il NOME/ID della vulnerabilità (es. CVE-2021-44228 = Log4Shell). CVSS = il PUNTEGGIO di severità (0-10) di quella vulnerabilità. CVE = catalogo, CVSS = voto.
Credentialed vs non-credentialed — trigger: "fewer false positives" + "detailed software versions" Credentialed scan gira con le credenziali di un account sul target: vede le versioni esatte del software, più accurato, meno falsi positivi. Non-credentialed = vista "da fuori", meno dettagliata, più falsi positivi.
Known/Unknown/Partially-known environment — trigger: "zero prior knowledge" vs "full knowledge including source code" vs "some information provided" Unknown (black box) = zero conoscenza preventiva. Known (white box) = conoscenza completa, incluso il codice sorgente. Partially known (gray box) = conoscenza parziale (es. solo gli IP target).
Intrusive vs non-intrusive — trigger: "may disrupt operations" vs "safe in production" Intrusive (= invasive) = pen testing, sfrutta attivamente le vulnerabilità e PUO' disturbare le operazioni. Non-intrusive (= non-invasive) = vulnerability scanning, non sfrutta nulla, sicuro anche in produzione.
Audit vs Assessment — trigger: "formal" + "independent team" + "attestation" vs "less formal" + "may include vuln scans/pen tests" Audit = formale, strutturato, team indipendente, produce un'attestation. Assessment = meno formale, interno o esterno, nessuna attestation - ma le sue tecniche (vuln scan, pen test) possono comparire dentro un audit.
Practice Questions#
Risposte#
Scenario Reale#
Risorse#
- Gibson, CompTIA Security+ Get Certified Get Ahead SY0-701 — Cap 8
- GetCertifiedGetAhead — https://getcertifiedgetahead.com/ (domande di pratica, lab e risorse aggiuntive per l'esame)
Collegato a#
- cap-07-advanced-attacks: capitolo precedente
DAST (Dynamic Application Security Testing): test che manda richieste reali (anche payload malevoli come SQLi/XSS) a un'app IN ESECUZIONE e osserva le risposte - black-box, intrusivo. Contrario: SAST (Static), analizza il codice senza eseguirlo - non intrusivo. Vedi DAST. ↩︎
SMB (Server Message Block) è il PROTOCOLLO di rete Microsoft per condividere file/cartelle/stampanti (porta 445/TCP). Samba NON è lo stesso nome per due cose diverse: è il SOFTWARE open source che implementa quel protocollo su Linux/Unix - stessa relazione tra Apache e HTTP (Apache implementa HTTP, non È HTTP). Vedi SMB. ↩︎